DeepSeek Coder: Let the Code Write Itself
DeepSeek Coder
- DeepSeek Chat
- DeepSeek Coder: Let the Code Write Itself
- GitHub: DeepSeek Coder
- HuggingFace: DeepSeek
- TheBloke: deepseek-coder-6.7B-instruct-GGUF
- Ollama: DeepSeek Coder
Code LLM 排行榜
Big Code Models Leaderboard
选择了两个通用基准来评估:
- HumanEval: 用于测量从文档字符串合成程序的功能正确性的基准。它由 164 个 Python 编程问题组成。
- MultiPL-E: 将 HumanEval 翻译为 18 种编程语言。
下面显示了 OctoCoder vs Base HumanEval prompt 的示例,在这里可以找到它。

CanAiCode Leaderboard
Coding LLMs Leaderboard
LLM 排行榜
Open LLM Leaderboard
LLM-Perf Leaderboard
介绍
DeepSeek Coder 由一系列代码语言模型组成,每个模型都在 2T 令牌上从头开始训练,其中 87% 是英文和中文的代码,13% 是自然语言。我们提供各种尺寸的代码模型,范围从 1B 到 33B 版本。每个模型都通过使用 16K 的窗口大小和额外的填空任务在项目级代码语料库上进行预训练,以支持项目级代码补全和填充。在编码能力方面,DeepSeek Coder 在多种编程语言和各种基准测试的开源代码模型中实现了最先进的性能。

数据创建
- 步骤1:从 GitHub 收集代码数据,并应用与 StarCoder Data 相同的过滤规则来过滤数据。
- 步骤2:解析同一存储库内文件的依赖关系,根据依赖关系重新排列文件位置。
- 步骤3:连接相关文件以形成单个示例,并使用存储库级 minhash 进行重复数据删除。
- 步骤4:进一步过滤低质量代码,例如语法错误或可读性差的代码。

模型训练
- 步骤 1:最初使用由 87% 代码、10% 代码相关语言(Github Markdown 和 StackExchange)和 3% 非代码相关中文组成的数据集进行预训练。在此步骤中,使用 1.8T 令牌和 4K 窗口大小对模型进行预训练。
- 步骤 2:在额外的 200B 令牌上使用扩展的 16K 窗口大小进行进一步预训练,从而产生基础模型 ( DeepSeek-Coder-Base )。
- 步骤 3:对指令数据的 2B 令牌进行指令微调,从而产生指令调整模型 ( DeepSeek-Coder-Instruct )。

使用方法
代码完成
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
代码插入
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
聊天模型推理
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
# 32021 is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=32021)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
如果您不想使用提供的 API apply_chat_template 加载模板 tokenizer_config.json,您可以使用以下模板与我们的模型聊天。将替换 ['content'] 为您的指令和模型之前(如果有)的响应,然后模型将生成对当前给定指令的响应。
You are an AI programming assistant, utilizing the DeepSeek Coder model, developed by DeepSeek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
['content']
### Response:
['content']
<|EOT|>
### Instruction:
['content']
### Response:
这个命令会读取 tokenizer_config.json 文件,提取 chat_template 字段的值,然后使用 @text 格式化字符串将 \n、\t 等转义字符转换为实际的换行符、制表符等,并在终端中显示结果。
jq -r '.chat_template | @text' tokenizer_config.json
存储库级别代码完成
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
# model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
# main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=140)
print(tokenizer.decode(outputs[0]))
在以下场景中,DeepSeek-Coder-6.7B 模型有效地从文件 model.py 中调用类 IrisClassifier 及其成员函数,并利用文件 utils.py 中的函数,正确完成文件 main.py 中的主要函数进行模型训练和评估。
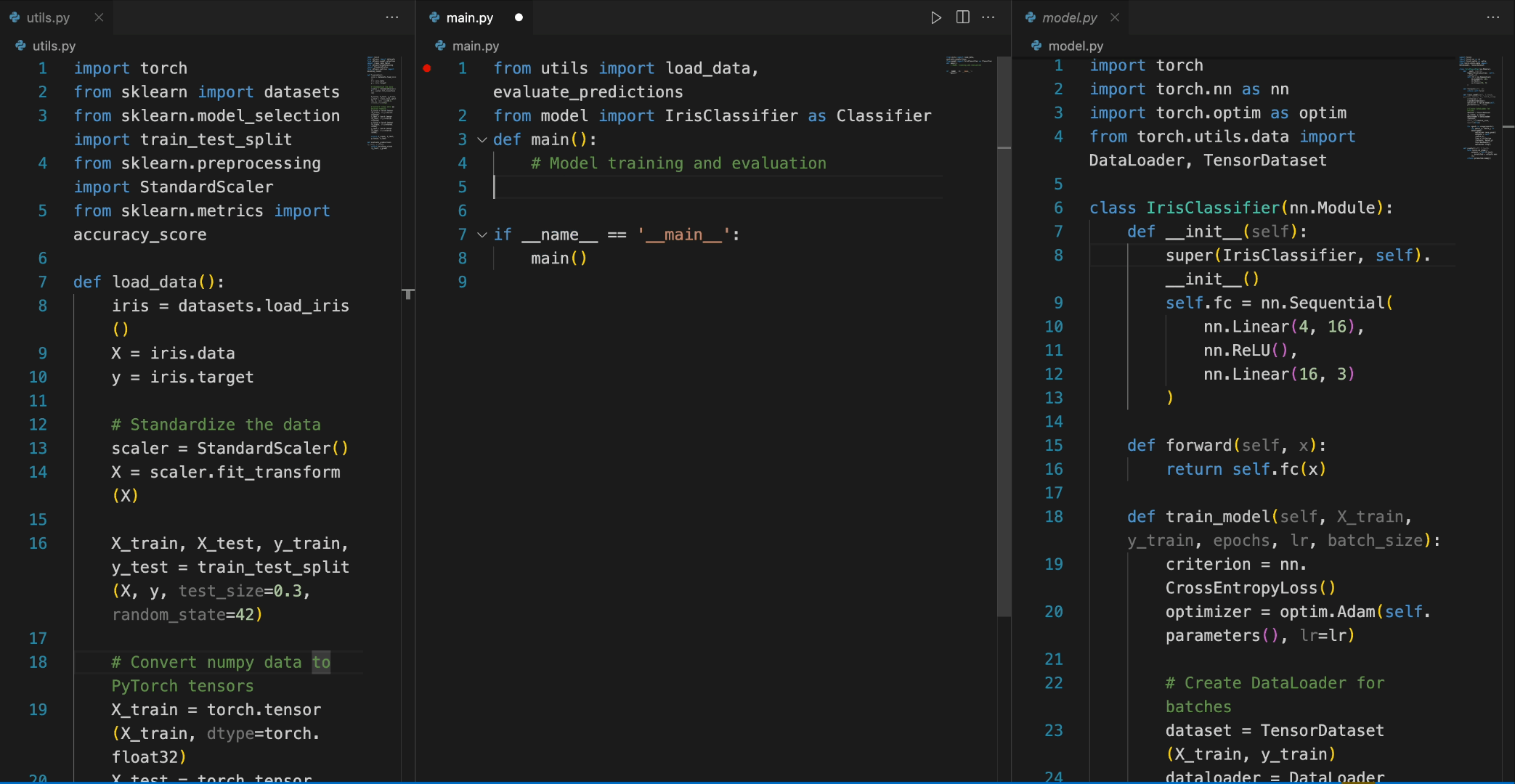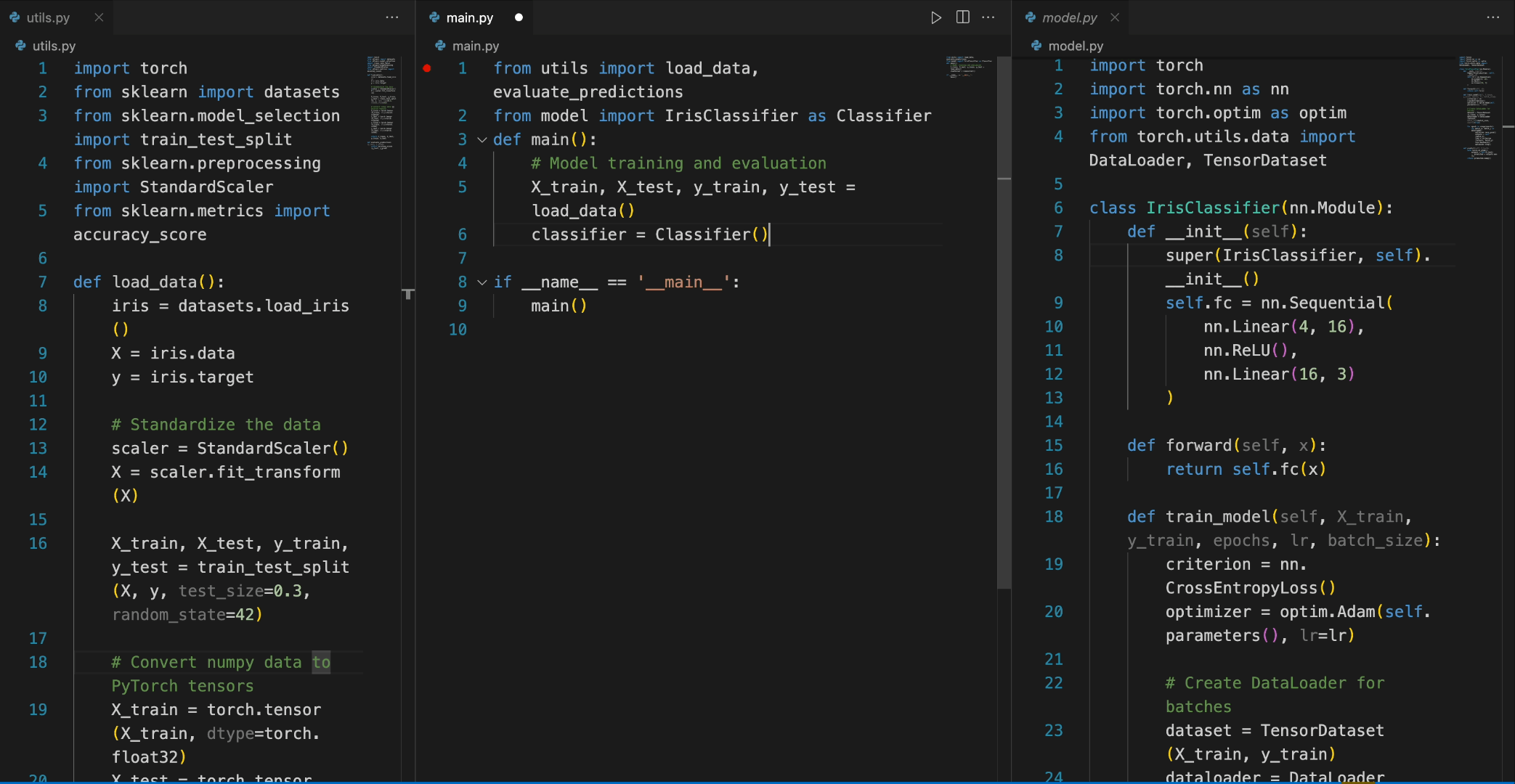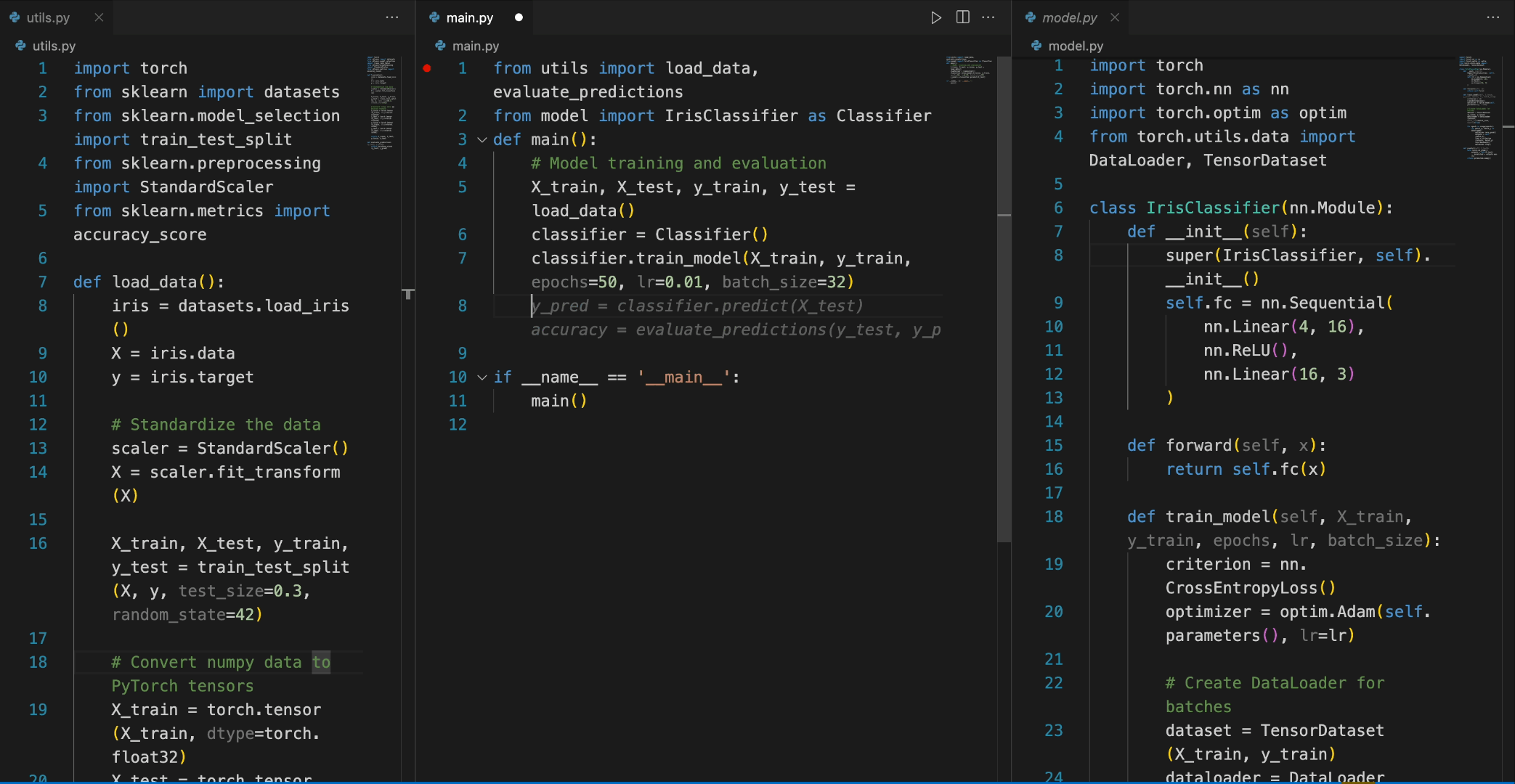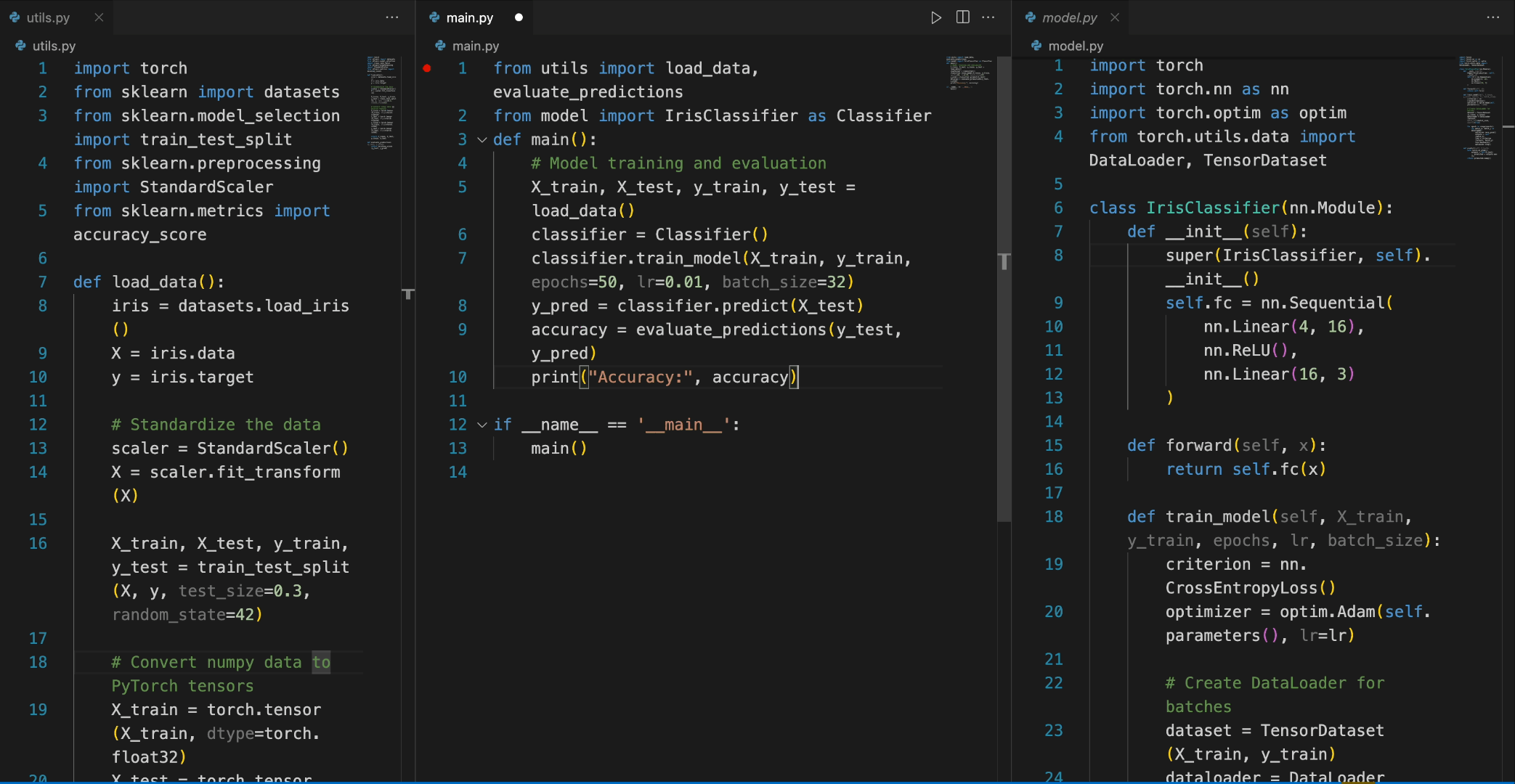
微调 DeepSeek-Coder
- 使用脚本
finetune/finetune_deepseekcoder.py微调下游任务的模型。 - 按照示例数据集格式准备您的训练数据。每行都是一个 json 序列化字符串,其中包含两个必填字段
instruction和output。 - 数据准备好后,您可以使用示例 shell 脚本进行微调
deepseek-ai/deepseek-coder-6.7b-instruct。请记住指定DATA_PATH,OUTPUT_PATH. 请根据您的场景选择合适的超参数(例如:learning_rate,per_device_train_batch_size)。
DATA_PATH="<your_data_path>"
OUTPUT_PATH="<your_output_path>"
MODEL="deepseek-ai/deepseek-coder-6.7b-instruct"
cd finetune && deepspeed finetune_deepseekcoder.py \
--model_name_or_path $MODEL_PATH \
--data_path $DATA_PATH \
--output_dir $OUTPUT_PATH \
--num_train_epochs 3 \
--model_max_length 1024 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 100 \
--save_total_limit 100 \
--learning_rate 2e-5 \
--warmup_steps 10 \
--logging_steps 1 \
--lr_scheduler_type "cosine" \
--gradient_checkpointing True \
--report_to "tensorboard" \
--deepspeed configs/ds_config_zero3.json \
--bf16 True
评估
查看评估目录
量化:GGUF, GPTQ
资源
Awesome-deepseek-coder 是与 DeepSeek Coder 相关的开源项目的精选列表。
参考资料
- InfiCoder-Eval: Systematically Evaluating Question-Answering for Code Large Language Models
- 【AI大模型展】网易数帆代码领域大模型——知识增强领域模型加速数智软件生产
-
[TheBloke/deepseek-coder-6.7B-instruct-AWQ problem in stopping response Ai < EOT > Problem](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-AWQ/discussions/1)