CodeFuse
CodeFuse 代码领域大模型
CodeFuse 的使命是开发专门设计用于支持整个软件开发生命周期的大型代码语言模型(Code LLMs),涵盖设计、需求、编码、测试、部署、运维等关键阶段。我们致力于打造创新的解决方案,让软件开发者们在研发的过程中如丝般顺滑。

- CodeFuse Blog
- CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
- CodeFuse
- CodeFuse 开源能力
- 什么是 CodeFuse
- HuggingFace CodeFuse
- TheBloke/CodeFuse-CodeLlama-34B-GGUF
- CodeFuse-CodeLlama-34B-4bits
- CodeFuse-CodeLlama34B-MFT编程助手Demo
| 功能 | 说明 |
|---|---|
| 代码补全 | 基于海量数据提供实时地代码补全服务,包括行内补全(单行补全)和片段补全(多行补全)。 |
| 添加注释 | 智能为选定的代码生成注释,目前在整个函数级别的生成注释效果较好。 |
| 解释代码 | 智能解析代码意图,为选定的代码生成解释,辅助阅读并理解代码。 |
| 生成单测 | 在写完业务逻辑后,为选定的代码生成单测,即可智能生成具备业务语义的测试用例,从而提升问题发现的效率。 |
| 代码优化 | 基于大模型的代码理解能力和静态源码分析能力,CodeFuse 支持对选定的代码片段进行分析理解并提出优化、改进建议,还能直接基于改进建议生成代码补丁。 |
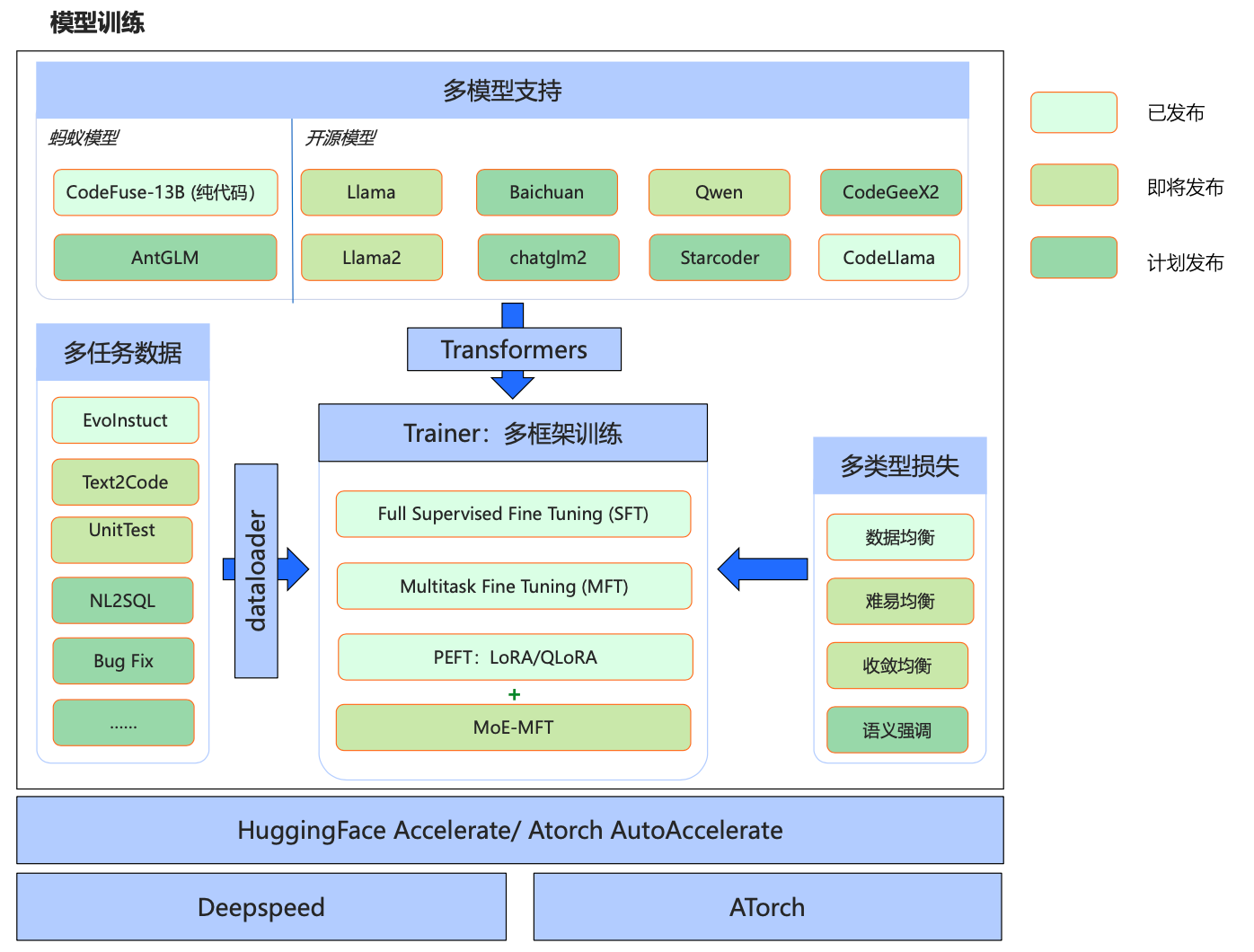
代码 - MFTCoder 系列
MFTCoder: 多任务大模型代码能力微调框架
DevOps-Model 中文开发运维大模型
基于 Qwen 系列模型,经过高质量中文 DevOps 语料加训后产出 Base 模型,然后经过 DevOps QA 数据对齐后产出 Chat 模型。
DevOps-Model Demo
评测基准 DevOpsEval
DevOps-Eval 是一个专门为 DevOps 领域大模型设计的综合评估数据集。

DevOps-ChatBot: 通过私人知识增强进行开发
通过检索增强生成(Retrieval Augmented Generation,RAG)、工具学习(Tool Learning)和沙盒环境来构建软件开发全生命周期的AI智能助手,涵盖设计、编码、测试、部署和运维等阶段。 逐渐从各处资料查询、独立分散平台操作的传统开发运维模式转变到大模型问答的智能化开发运维模式,改变人们的开发运维习惯。
本项目核心差异技术、功能点:
- 🧠 智能调度核心: 构建了体系链路完善的调度核心,支持多模式一键配置,简化操作流程。使用说明
- 💻 代码整库分析: 实现了仓库级的代码深入理解,以及项目文件级的代码编写与生成,提升了开发效率。
- 📄 文档分析增强: 融合了文档知识库与知识图谱,通过检索和推理增强,为文档分析提供了更深层次的支持。
- 🔧 垂类专属知识: 为DevOps领域定制的专属知识库,支持垂类知识库的自助一键构建,便捷实用。
- 🤖 垂类模型兼容: 针对DevOps领域的小型模型,保证了与DevOps相关平台的兼容性,促进了技术生态的整合。

技术路线

- 🧠 Multi-Agent Schedule Core: 多智能体调度核心,简易配置即可打造交互式智能体。
- 🕷️ Multi Source Web Crawl: 多源网络爬虫,提供对指定 URL 的爬取功能,以搜集所需信息。
- 🗂️ Data Processor: 数据处理器,轻松完成文档载入、数据清洗,及文本切分,整合不同来源的数据。
- 🔤 Text Embedding & Index::文本嵌入索引,用户可以轻松上传文件进行文档检索,优化文档分析过程。
- 🗄️ Vector Database & Graph Database: 向量与图数据库,提供灵活强大的数据管理解决方案。
- 📝 Prompt Control & Management::Prompt 控制与管理,精确定义智能体的上下文环境。
- 🚧 SandBox::沙盒环境,安全地执行代码编译和动作。
- 💬 LLM::智能体大脑,支持多种开源模型和 LLM 接口。
- 🛠️ API Management:: API 管理工具,实现对开源组件和运维平台的快速集成。
FasterTransformer4CodeFuse: 高性能的模型推理
CodeFuse 中文索引
数据集
CodeExercise-Python-27k
该数据集由 2.7万道 Python 编程练习题(英文)组成,覆盖基础语法与数据结构、算法应用、数据库查询、机器学习等数百个 Python 相关知识点。 注意:该数据集是借助教师模型和 Camel 生成,未经严格校验,题目或答案可能存在错误或语义重复,使用时请注意。

数据生成过程
- 第一步:整理 Python 知识点,作为初始种子集
- 第二步:将每个种子嵌入到固定的任务模版中,获得固定模版的 “Task Prompt”,该任务模版的主题是提示教师模型生成给定知识点的练习题问题。
- 第三步:调用 Camel 对第二步获得的 “Task Prompt” 进行润色,以获得更加描述准确且多样的 Task Prompt
- 第四步:将获得的 Task Prompt 输入给教师模型,令其生成对应知识点的练习题问题(指令)
- 第五步:对每个练习题问题(指令),借助教师模型生成对应的问题答案
- 第六步:组装每个问题和其答案,并进行去重操作
Evol-instruction-66k
Evol-instruction-66k 数据是根据论文《WizardCoder: Empowering Code Large Language Models with Evol-Instruct》中提到的方法,通过添加复杂的代码指令来增强预训练代码大模型的微调效果。 该数据是在开源数据集 Evol-Instruct-Code-80k-v1 基础上对数据进行了一系列处理,包括低质量过滤、HumanEval 评测相似数据过滤等,从原始 80k 数据筛选后得到 66k 高质量训练微调数据。
数据生成过程
- 过滤低质量数据
- (1) 过滤 instruction 长度小于 10 个单词或者大于 1000 个单词的数据;
- (2) 过滤 output 长度小于 50 个单词或者大于 2000 个单词的数据;
- (3) 过滤 output 中无 markdown 格式或者有多个 markdown 的数据;
- (4) 过滤 markdown 格式中代码少于 3 行或者大于 100 行的数据;
- (5) 过滤 markdown 格式前面描述单词大于 200 个单词的数据。
- 过滤与 HumanEval 相似的数据
- (1) 过滤包含 HumanEval 中任意函数名的数据;
- (2) 采用 NLTK 去除 HumanEval 的 docstring 中停用词、标点符号后,得到核心词,比如“sort array prime”等,
- 过滤包含了 HumanEval 超过 40% 核心词的数据。
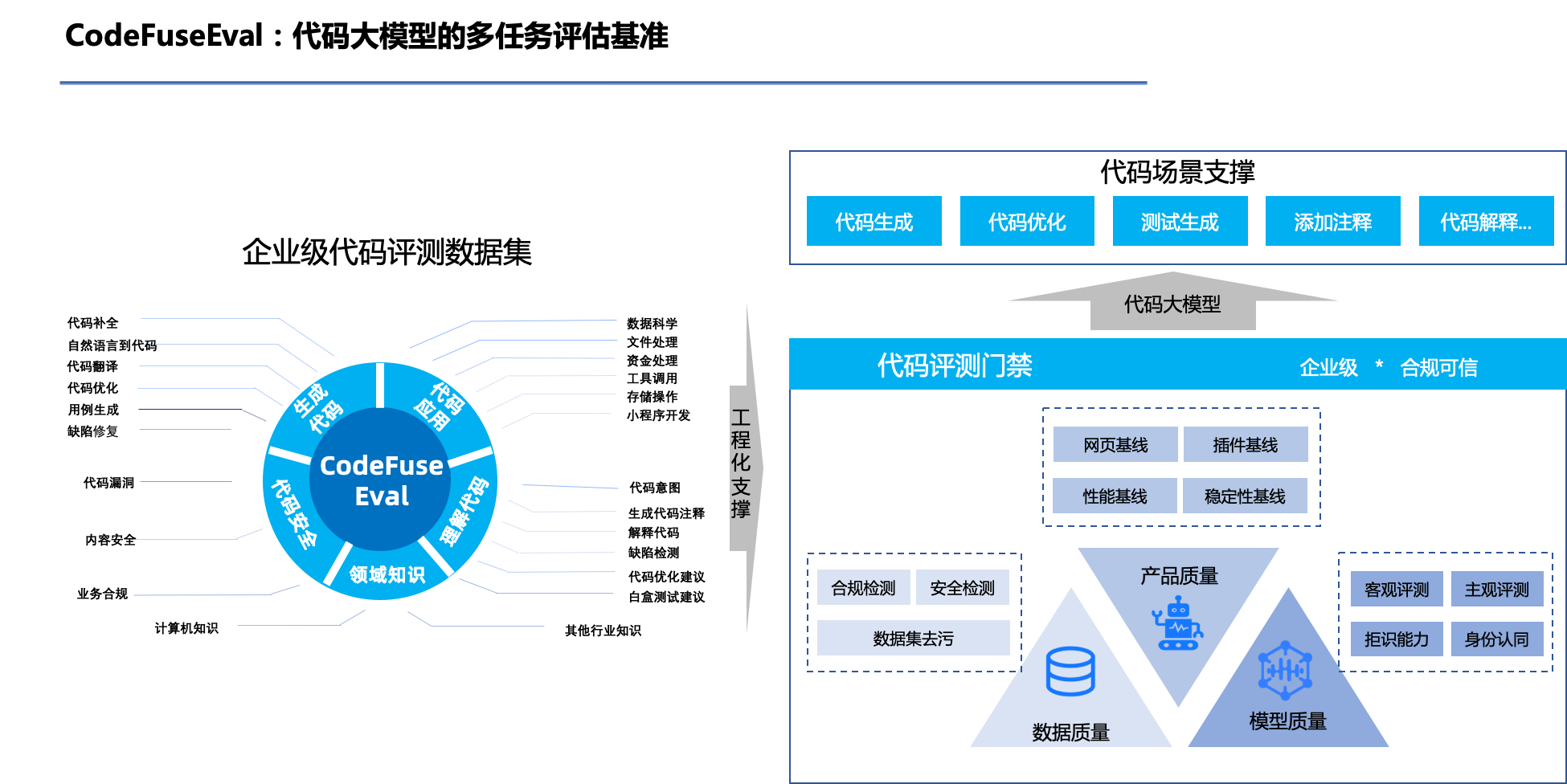
代码大语言模型多任务评估基准CodeFuseEval
评测基准
HumanEval
HumanEval 是一个用于评估代码生成模型性能的数据集,由OpenAI在2021年推出。这个数据集包含164个手工编写的编程问题,每个问题都包括一个函数签名、文档字符串(docstring)、函数体以及几个单元测试。这些问题涵盖了语言理解、推理、算法和简单数学等方面。这些问题的难度也各不相同,有些甚至与简单的软件面试问题相当。 这个数据集的一个重要特点是,它不仅仅依赖于代码的语法正确性,还依赖于功能正确性。也就是说,生成的代码需要通过所有相关的单元测试才能被认为是正确的。这种方法更接近于实际编程任务,因为在实际编程中,代码不仅需要语法正确,还需要能够正确执行预定任务。结果通过pass@k表示,其中k表示模型一次性生成多少种不同的答案中,至少包含1个正确的结果。例如Pass@1就是只生成一个答案,准确的比例。如果是Pass@10表示一次性生成10个答案其中至少有一个准确的比例。目前,收集的包含Pass@1、Pass@10和Pass@100
MBPP
MBPP(Mostly Basic Programming Problems)是一个数据集,主要包含了974个短小的Python函数问题,由谷歌在2021年推出,这些问题主要是为初级程序员设计的。数据集还包含了这些程序的文本描述和用于检查功能正确性的测试用例。 结果通过pass@k表示,其中k表示模型一次性生成多少种不同的答案中,至少包含1个正确的结果。例如Pass@1就是只生成一个答案,准确的比例。如果是Pass@10表示一次性生成10个答案其中至少有一个准确的比例。目前,收集的包含Pass@1、Pass@10和Pass@100
HumanEval-X
HumanEval-X 为了更好地评测代码生成模型的多语言生成能力。HumanEval-X 可用于衡量生成代码的功能正确性。HumanEval-X包含820个高质量手写样本,覆盖Python、C++、Java、JavaScript、Go,可用于多种任务。
CodeFuseEval: 代码大语言模型的多任务评估基准
CodeFuseEval 在 HumanEval-X、MBPP 的基准上,结合 CodeFuse 大模型多任务场景,开发的编程领域多任务的评测基准, 可用于评估模型在代码补全,自然语言生成代码,测试用例生成、跨语言代码翻译,中文指令生成代码等多类任务的性能。
大模型能力评测
代码大模型
- NLP与软件工程视角的统一:代码语言模型概述
- 人工智能对齐:全面性综述
- 500篇论文!最全代码大模型综述来袭
- 涵盖500多项研究、50多个模型,代码大模型综述来了
- 代码大模型综述:中科院和MSRA调研27个LLMs,并给出5个有趣挑战
- 人手一个编程助手,北大最强代码大模型CodeShell-7B开源,性能霸榜,IDE插件全开源
- NL2Code
参考资料
- CodeFusion: A Pre-trained Diffusion Model for Code Generation
- CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
- MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning
- Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code
- 蚂蚁代码大模型是如何炼成的?
- 蚂蚁集团CodeFuse开源代码生成模型,帮助提升编程效率
- DevOps-ChatBot:DevOps开源端到端智能AI助手
- DevOps-ChatBot 本地私有化/大模型接口接入
- 基于 CodeFuse-CodeLlama-34B-4bits 模型部署你的私人AI编程助手【编程能力超越 GPT4】
- langchain-chatchat加载CodeFuse34B大模型
- 如何快速下载huggingface模型——全方法总结
- CodeShell
- Dify.AI:其中大约 30% 的代码是由 GPT 生产
- CodeFuse 产品介绍
- Apple silicon cannot install the AutoGPT #223
- 青燕(Tsingyan)AI代码智能插件助手,一起感受沉浸式的极速编码体验吧!
- 一个智能助手搞定软件开发全流程,从设计到运维统统交给AI