Claude Managed Agents(托管智能体)开发者参考指南
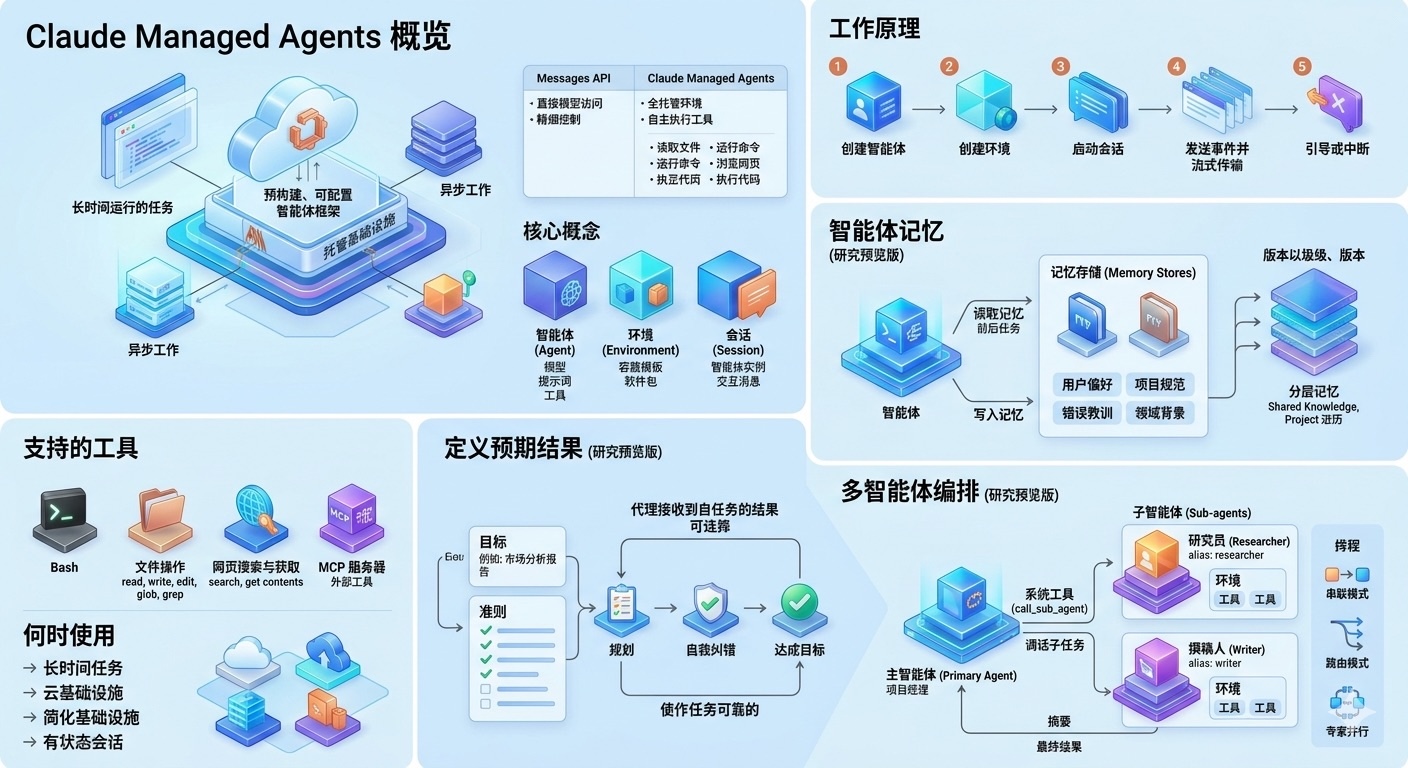
Claude Managed Agents 概览
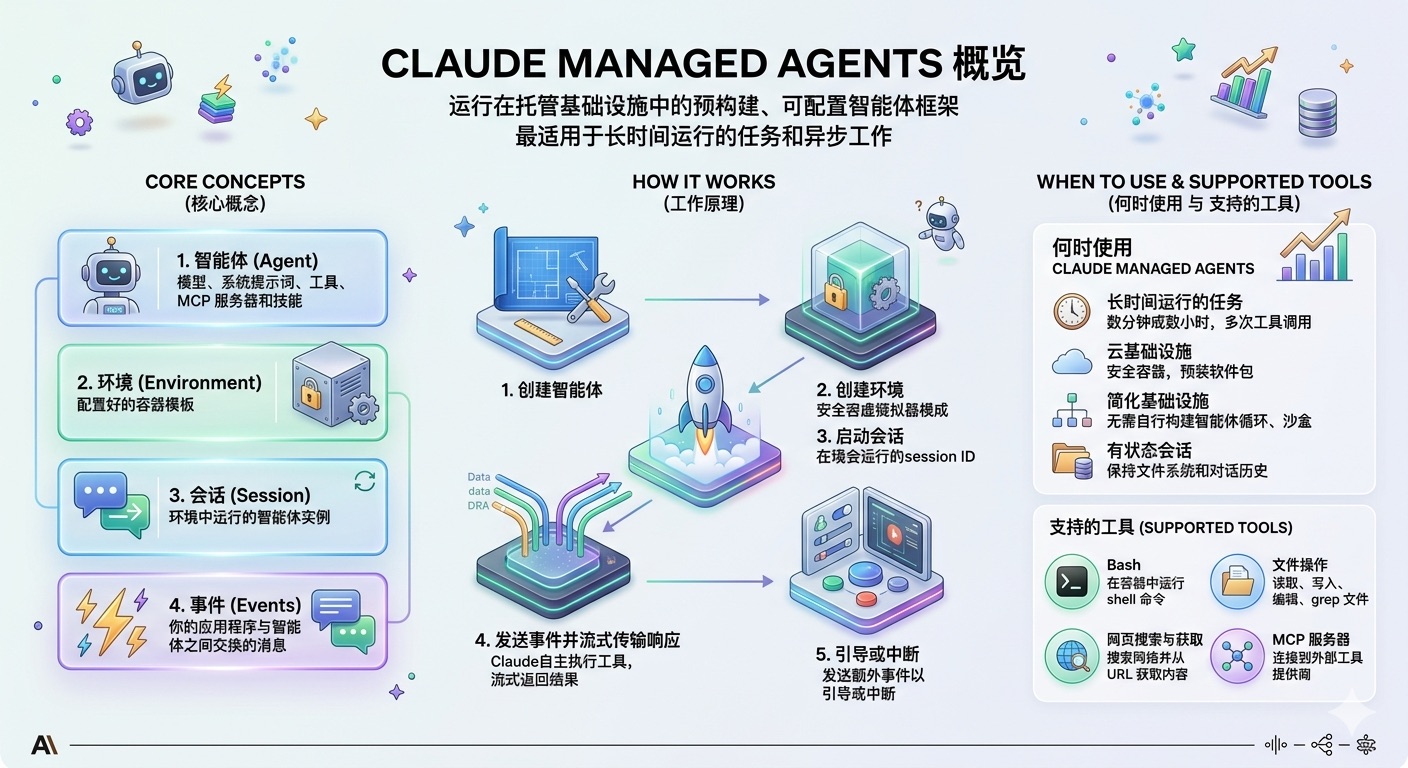
这是一个运行在托管基础设施中的预构建、可配置智能体(Agent)框架,最适用于长时间运行的任务和异步工作。
Anthropic 提供了两种使用 Claude 构建应用的方式,分别适用于不同的使用场景:
| Messages API | Claude Managed Agents | |
|---|---|---|
| 定位 | 直接的模型提示词访问 | 运行在托管基础设施中的预构建、可配置智能体框架 |
| 最佳用途 | 自定义智能体循环和精细化控制 | 长时间运行的任务和异步工作 |
| 了解更多 | Messages API 文档 | Claude Managed Agents 文档 |
Claude Managed Agents 为将 Claude 作为自主智能体运行提供了框架和基础设施。无需构建自己的智能体循环、工具执行环境和运行时,你即可获得一个全托管的环境,让 Claude 能够安全地读取文件、运行命令、浏览网页并执行代码。该框架支持内置的提示词缓存、压缩以及其他性能优化,以实现高质量、高效的智能体输出。
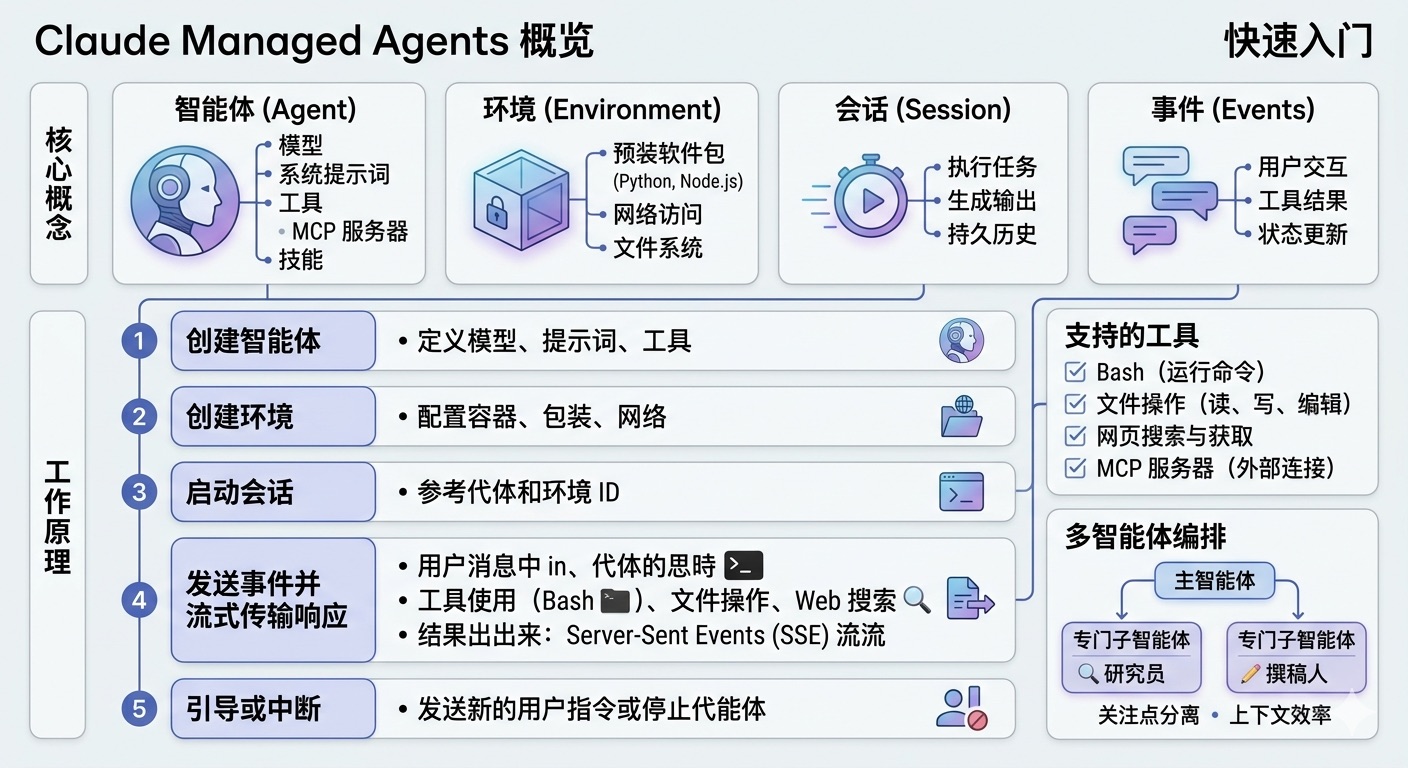
核心概念
Claude Managed Agents 基于四个核心概念构建:
| 概念 | 描述 |
|---|---|
| 智能体 (Agent) | 模型、系统提示词、工具、MCP 服务器和技能 |
| 环境 (Environment) | 配置好的容器模板(包含软件包、网络访问权限等) |
| 会话 (Session) | 环境中运行的智能体实例,执行特定任务并生成输出 |
| 事件 (Events) | 你的应用程序与智能体之间交换的消息(用户交互、工具结果、状态更新) |
工作原理
1. 创建智能体
定义模型、系统提示词、工具、MCP 服务器和技能。创建一次智能体,即可在不同会话中通过 ID 进行引用。
2. 创建环境
配置一个带有预装软件包(如 Python、Node.js、Go 等)、网络访问规则和挂载文件的云容器。
3. 启动会话
启动一个引用了你的智能体和环境配置的会话。
4. 发送事件并流式传输响应
以事件形式发送用户消息。Claude 会自主执行工具,并通过服务器发送事件 (SSE) 流式返回结果。事件历史记录在服务端持久化,并可完整获取。
5. 引导或中断
发送额外的用户事件以在执行过程中引导智能体,或者对其进行中断以改变方向。
何时使用 Claude Managed Agents
Claude Managed Agents 最适合具有以下需求的工作负载:
- 长时间运行的任务 - 需要运行数分钟或数小时并进行多次工具调用的任务
- 云基础设施 - 需要带有预装软件包和网络访问权限的安全容器
- 简化基础设施 - 无需自行构建智能体循环、沙盒或工具执行层
- 有状态会话 - 需要在多次交互中保持文件系统和对话历史
支持的工具
Claude Managed Agents 为 Claude 提供了全面的内置工具集:
- Bash - 在容器中运行 shell 命令
- 文件操作 - 读取、写入、编辑、使用 glob 和 grep 命令操作容器中的文件
- 网页搜索与获取 - 搜索网络并从 URL 获取内容
- MCP 服务器 - 连接到外部工具提供商
测试版权限
Claude Managed Agents 目前处于测试阶段。所有 Managed Agents 端点都需要 managed-agents-2026-04-01 测试版请求头。SDK 会自动设置该请求头。相关行为可能会在后续版本中进行优化,以提高输出效果。
开始使用前,你需要:
- 一个
Claude API 密钥 - 所有请求中包含上述测试版请求头
- Claude Managed Agents 的访问权限(所有 API 账户默认启用)
速率限制
Managed Agents 端点按组织设置速率限制:
| 操作 | 限制 |
|---|---|
| 创建端点(智能体、会话、环境等) | 每分钟 60 次请求 |
| 读取端点(检索、列表、流式传输等) | 每分钟 600 次请求 |
Claude Managed Agents 快速入门
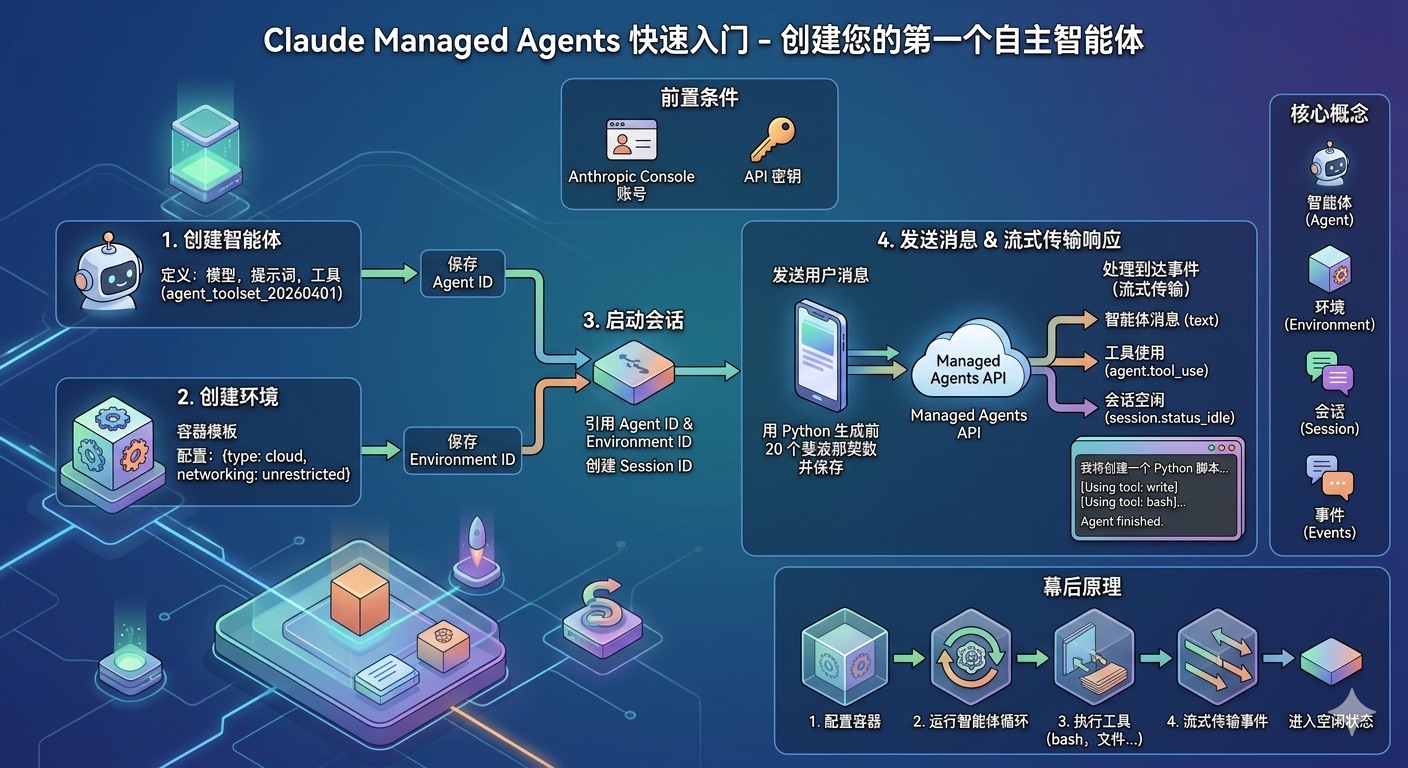
创建您的第一个自主智能体(Autonomous Agent)。
本指南将带您完成创建智能体、设置环境、启动会话以及流式传输智能体响应的全过程。
核心概念
| 概念 | 描述 |
|---|---|
| 智能体 (Agent) | 包含模型、系统提示词、工具、MCP 服务和技能的定义。 |
| 环境 (Environment) | 配置好的容器模板(包括软件包、网络访问权限等)。 |
| 会话 (Session) | 在环境中运行的智能体实例,用于执行特定任务并生成输出。 |
| 事件 (Events) | 您的应用程序与智能体之间交换的消息(用户轮次、工具结果、状态更新)。 |
前置条件
- 一个 Anthropic Console 账号
- 一个 API 密钥
安装 CLI
Homebrew (macOS)
brew install anthropics/tap/ant
在 macOS 上,需要对二进制文件取消隔离:
xattr -d com.apple.quarantine "$(brew --prefix)/bin/ant"
curl (Linux/WSL)
检查安装:
ant --version
安装 SDK
Python
pip install anthropic
将您的 API 密钥设置为环境变量:
export ANTHROPIC_API_KEY="your-api-key-here"
创建您的第一个会话
所有 Managed Agents API 请求都需要包含 managed-agents-2026-04-01 Beta 请求头。SDK 会自动设置该请求头。
1. 创建智能体
创建一个定义了模型、系统提示词和可用工具的智能体。
使用 CLI:
ant beta:agents create \
--name "Coding Assistant" \
--model '{id: claude-sonnet-4-6}' \
--system "You are a helpful coding assistant. Write clean, well-documented code." \
--tool '{type: agent_toolset_20260401}'
agent_toolset_20260401 工具类型启用了全套预构建的智能体工具(bash、文件操作、网络搜索等)。请参阅“工具”章节以获取完整列表和各工具的配置选项。
请保存返回的 agent.id。在创建每个会话时都需要引用它。
2. 创建环境
环境定义了智能体运行的容器。
使用 CLI:
ant beta:environments create \
--name "quickstart-env" \
--config '{type: cloud, networking: {type: unrestricted}}'
请保存返回的 environment.id。在创建每个会话时都需要引用它。
3. 启动会话
创建一个引用了您的智能体和环境的会话。
使用 curl:
session=$( curl -sS --fail-with-body https://api.anthropic.com/v1/sessions \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "content-type: application/json" \
-d @- <<EOF
{
"agent": "$AGENT_ID",
"environment_id": "$ENVIRONMENT_ID",
"title": "Quickstart session"
}
EOF
)
SESSION_ID=$(jq -er '.id' <<<"$session")
echo "Session ID: $SESSION_ID"
4. 发送消息并流式传输响应
开启一个流,发送用户事件,然后处理到达的事件:
使用 curl:
# 首先发送用户消息;API 会缓冲事件直到流连接成功
curl -sS --fail-with-body \
"https://api.anthropic.com/v1/sessions/$SESSION_ID/events" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "content-type: application/json" \
-d @- >/dev/null <<'EOF'
{
"events": [
{
"type": "user.message",
"content": [
{
"type": "text",
"text": "Create a Python script that generates the first 20 Fibonacci numbers and saves them to fibonacci.txt"
}
]
}
]
}
EOF
# 开启 SSE 流并处理到达的事件
while IFS= read -r line; do
[[ $line == data:* ]] || continue
json=${line#data: }
case $(jq -r '.type' <<<"$json") in
agent.message)
jq -j '.content[] | select(.type == "text") | .text' <<<"$json"
;;
agent.tool_use)
printf '\n[Using tool: %s]\n' "$(jq -r '.name' <<<"$json")"
;;
session.status_idle)
printf '\n\nAgent finished.\n'
break
;;
esac
done < <( curl -sS -N --fail-with-body \
"https://api.anthropic.com/v1/sessions/$SESSION_ID/stream" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "Accept: text/event-stream" )
智能体会编写一个 Python 脚本,在容器内执行它,并验证输出文件是否已创建。您的输出将类似于:
我将创建一个 Python 脚本来生成前 20 个斐波那契数并将其保存到文件中。
[Using tool: write]
[Using tool: bash]
脚本运行成功。让我验证一下输出文件。
[Using tool: bash]
fibonacci.txt 包含了前 20 个斐波那契数(0 到 4181)。
Agent finished.
幕后原理
当您发送用户事件时,Claude Managed Agents 会执行以下操作:
- 配置容器:您的环境配置决定了容器的构建方式。
- 运行智能体循环:Claude 根据您的消息决定使用哪些工具。
- 执行工具:文件写入、bash 命令和其他工具调用在容器内部运行。
- 流式传输事件:在智能体工作时,您会收到实时更新。
- 进入空闲状态:当智能体没有更多任务时,它会发出
session.status_idle事件。
定义您的智能体 (Define your agent)
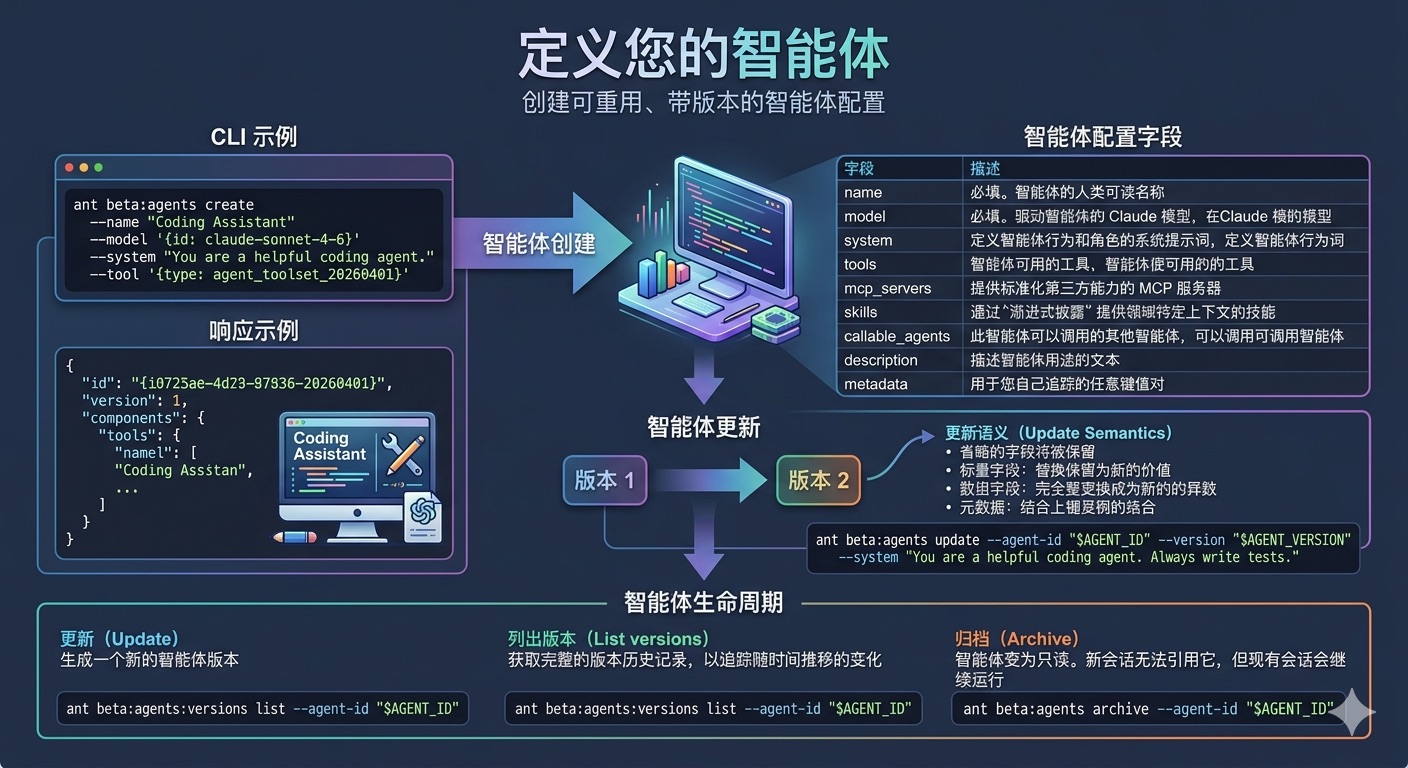
创建可重用、带版本的智能体配置。
智能体(Agent)是一个可重用的、带版本的配置,它定义了角色的形象和能力。它将模型、系统提示词、工具、MCP(模型上下文协议)服务器和技能捆绑在一起,决定了 Claude 在会话期间的行为方式。
您只需将智能体创建为一个可重用资源,并在每次启动会话时通过其 ID 进行引用。智能体具有版本控制功能,更易于在多个会话中进行管理。
注意: 所有 Managed Agents API 请求都需要包含
managed-agents-2026-04-01Beta 请求头。SDK 会自动设置此请求头。
智能体配置字段
| 字段 | 描述 |
|---|---|
| name | 必填。智能体的人类可读名称。 |
| model | 必填。驱动智能体的 Claude 模型。支持所有 Claude 4.5 及更高版本的模型。 |
| system | 定义智能体行为和角色的系统提示词。系统提示词应与描述具体工作任务的用户消息(User messages)区分开。 |
| tools | 智能体可用的工具。结合了预构建的智能体工具、MCP 工具和自定义工具。 |
| mcp_servers | 提供标准化第三方能力的 MCP 服务器。 |
| skills | 通过“渐进式披露”提供领域特定上下文的技能(Skills)。 |
| callable_agents | 此智能体可以调用的其他智能体,用于多智能体编排(Multi-agent orchestration)。这是一个研究预览版功能;需申请访问权限。 |
| description | 描述智能体用途的文本。 |
| metadata | 用于您自己追踪的任意键值对。 |
创建智能体
以下示例定义了一个编程智能体,它使用 Claude Sonnet 4.6 并具有预构建智能体工具集的访问权限。该工具集允许智能体编写代码、读取文件、搜索网页等。完整的支持工具列表请参阅“智能体工具参考”。
CLI 示例:
ant beta:agents create \
--name "Coding Assistant" \
--model '{id: claude-sonnet-4-6}' \
--system "You are a helpful coding agent." \
--tool '{type: agent_toolset_20260401}'
若要以“快速模式 (fast mode)”使用 Claude Opus 4.6,请将 model 作为一个对象传递:{"id": "claude-opus-4-6", "speed": "fast"}。
响应会返回您的配置,并添加 id、version、created_at、updated_at 和 archived_at 字段。版本号(version)从 1 开始,每次更新智能体时都会递增。
响应示例:
{
"id": "agent_01HqR2k7vXbZ9mNpL3wYcT8f",
"type": "agent",
"name": "Coding Assistant",
"model": {
"id": "claude-sonnet-4-6",
"speed": "standard"
},
"system": "You are a helpful coding agent.",
"description": null,
"tools": [
{
"type": "agent_toolset_20260401",
"default_config": {
"permission_policy": {
"type": "always_allow"
}
}
}
],
"skills": [],
"mcp_servers": [],
"metadata": {},
"version": 1,
"created_at": "2026-04-03T18:24:10.412Z",
"updated_at": "2026-04-03T18:24:10.412Z",
"archived_at": null
}
更新智能体
更新智能体会生成一个新版本。请传递当前版本号,以确保您是基于已知状态进行更新。
CLI 示例:
ant beta:agents update \
--agent-id "$AGENT_ID" \
--version "$AGENT_VERSION" \
--system "You are a helpful coding agent. Always write tests."
更新语义 (Update semantics)
- 省略的字段将被保留:您只需要包含想要更改的字段。
- 标量字段(如
model、system、name等):会被新值替换。可以通过传递null来清除system和description字段。model和name是强制字段,不能清除。 - 数组字段(如
tools、mcp_servers、skills、callable_agents):会被新数组完全替换。要彻底清除数组字段,请传递null或空数组。 - 元数据 (Metadata):在键(key)级别进行合并。提供的键将被添加或更新,省略的键将被保留。要删除特定键,请将其值设置为空字符串。
- 空操作检测:如果更新操作相对于当前版本没有任何变化,则不会创建新版本,并返回现有版本。
智能体生命周期
| 操作 | 行为 |
|---|---|
| 更新 (Update) | 生成一个新的智能体版本。 |
| 列出版本 (List versions) | 获取完整的版本历史记录,以追踪随时间推移的变化。 |
| 归档 (Archive) | 智能体变为只读。新会话无法引用它,但现有会话会继续运行。 |
列出版本
获取完整的版本历史记录,了解智能体是如何随时间演变的。
CLI 示例:
ant beta:agents:versions list --agent-id "$AGENT_ID"
归档智能体
归档会将智能体设为只读。现有会话会继续运行,但新会话无法引用该智能体。响应会将 archived_at 设置为归档的时间戳。
CLI 示例:
ant beta:agents archive --agent-id "$AGENT_ID"
配置环境 (Configure Environments)
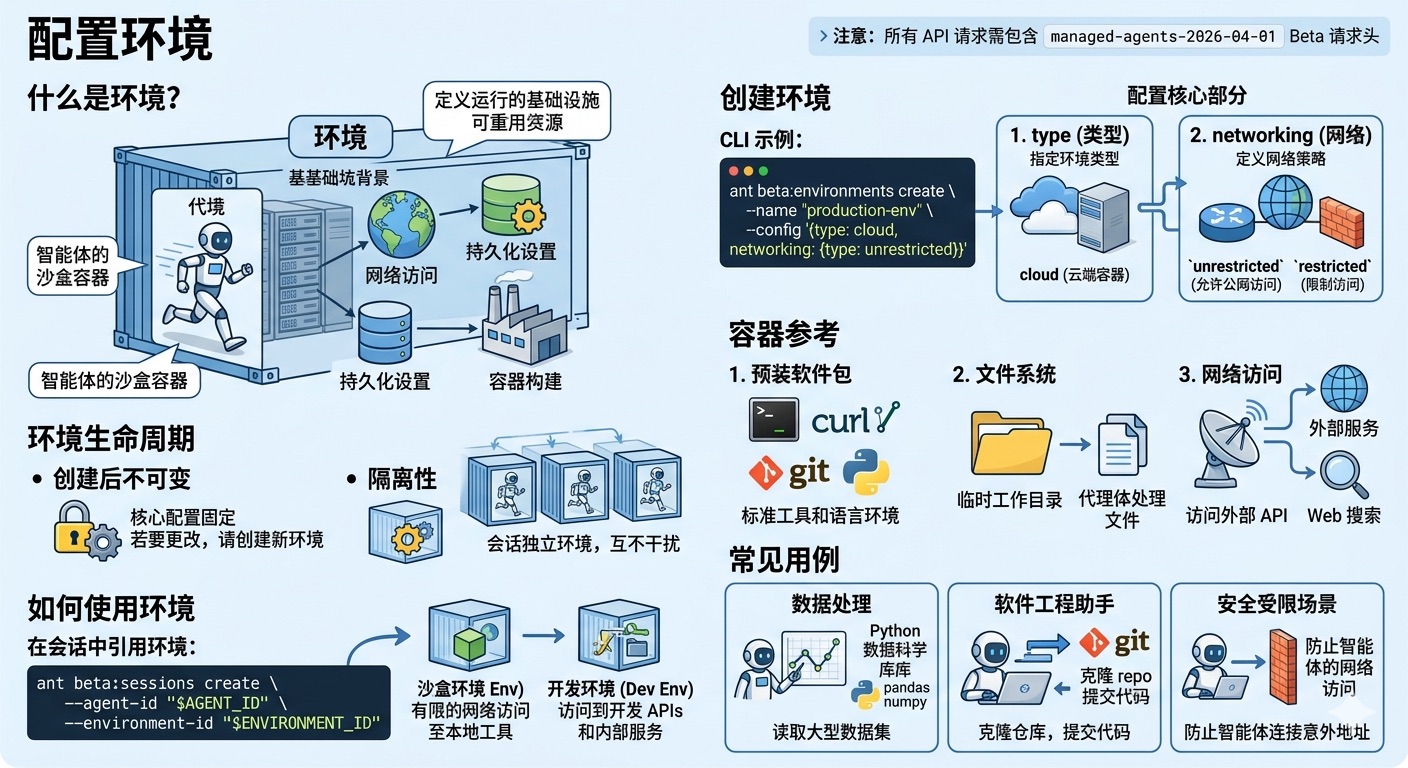
环境(Environment)定义了智能体运行的沙盒容器。
环境决定了智能体在执行任务时所处的基础设施。您可以在环境定义中配置网络访问、持久化设置以及容器构建方式,从而确保智能体具备完成任务所需的运行环境和依赖项。
与智能体配置一样,环境也是一个可重用的资源。一旦创建,您可以将其作为会话的基础,以便在多个会话之间共享相同的配置。
注意: 所有 Managed Agents API 请求都需要包含
managed-agents-2026-04-01Beta 请求头。SDK 会自动设置此请求头。
创建环境
环境配置包含两个核心部分:type(类型)和 networking(网络)。
CLI 示例:
ant beta:environments create \
--name "production-env" \
--config '{type: cloud, networking: {type: unrestricted}}'
配置字段说明
| 字段 | 描述 |
|---|---|
| type | 指定环境的类型,例如 cloud(基于云的容器)。 |
| networking | 定义容器的网络策略。 |
| networking.type | 决定联网能力。unrestricted 允许访问公共互联网;restricted 则可能限制访问(根据您的平台安全策略)。 |
环境生命周期
环境旨在为智能体提供一致且隔离的运行环境。
- 创建后不可变:环境一旦创建,其核心配置通常是固定的。若要更改配置(例如修改网络权限),建议创建一个新的环境版本或新环境,并在启动新会话时引用它。
- 隔离性:每个会话都会在一个独立的实例环境中启动,确保一个智能体任务的副作用不会影响到另一个任务的运行环境。
容器参考 (Container Reference)
对于 Managed Agents,容器环境提供了一些预装的功能,以便于智能体执行各种操作:
- 预装软件包:标准环境包含常用的系统工具(如
bash、curl、git等)以及 Python 执行环境。 - 文件系统:容器提供临时工作目录,用于存储智能体在执行任务期间生成或处理的文件。
- 网络访问:根据
networking配置,智能体可以访问外部 API 或进行 Web 搜索。
如何使用环境
在启动会话时,您需要指定 environment_id。这意味着您可以针对不同的任务创建不同的环境配置,例如:
- 沙盒环境:严格的网络限制,仅允许访问预定义的本地工具。
- 开发环境:允许访问特定的开发 API 和内部服务。
在会话中引用环境:
ant beta:sessions create \
--agent-id "$AGENT_ID" \
--environment-id "$ENVIRONMENT_ID"
常见用例
- 数据处理任务:创建一个配置了必要 Python 数据科学库的环境,让智能体能够读取大型数据集。
- 软件工程助手:创建一个具备 Git 访问权限的环境,让智能体能够克隆仓库并提交代码补丁。
- 安全受限场景:创建一个网络受限的环境,防止智能体在执行不受信任的代码时连接到意外的外部地址。
容器参考
云容器中预装的软件包、数据库和实用工具。
Claude Managed Agents 中的云容器预装了全面的编程语言、数据库和实用工具。智能体可以直接使用这些工具,无需进行任何安装步骤。
所有 Managed Agents API 请求都需要 managed-agents-2026-04-01 测试版请求头。SDK 会自动设置该请求头。
编程语言
| 语言 | 版本 | 包管理器 |
|---|---|---|
| Python | 3.12+ | pip, uv |
| Node.js | 20+ | npm, yarn, pnpm |
| Go | 1.22+ | go modules |
| Rust | 1.77+ | cargo |
| Java | 21+ | maven, gradle |
| Ruby | 3.3+ | bundler, gem |
| PHP | 8.3+ | composer |
| C/C++ | GCC 13+ | make, cmake |
数据库
| 数据库 | 描述 |
|---|---|
| SQLite | 预装,可立即使用 |
| PostgreSQL 客户端 | 用于连接外部数据库的 psql 客户端 |
| Redis 客户端 | 用于连接外部实例的 redis-cli |
数据库服务器(如 PostgreSQL、Redis 等)默认不在容器内运行。容器包含用于连接外部数据库实例的客户端工具。SQLite 可供本地使用。
实用工具
系统工具
git- 版本控制curl,wget- HTTP 客户端jq- JSON 处理tar,zip,unzip- 归档工具ssh,scp- 远程访问(需要启用网络)tmux,screen- 终端多路复用器
开发工具
make,cmake- 构建系统docker- 容器管理(有限支持)ripgrep(rg) - 快速文件搜索tree- 目录可视化htop- 进程监控
文本处理
sed,awk,grep- 流编辑器vim,nano- 文本编辑器diff,patch- 文件比对
容器规格
| 属性 | 值 |
|---|---|
| 操作系统 | Ubuntu 22.04 LTS |
| 架构 | x86_64 (amd64) |
| 内存 | 最高 8 GB |
| 磁盘空间 | 最高 10 GB |
| 网络 | 默认禁用(需在环境配置中启用) |
工具 (Tools)
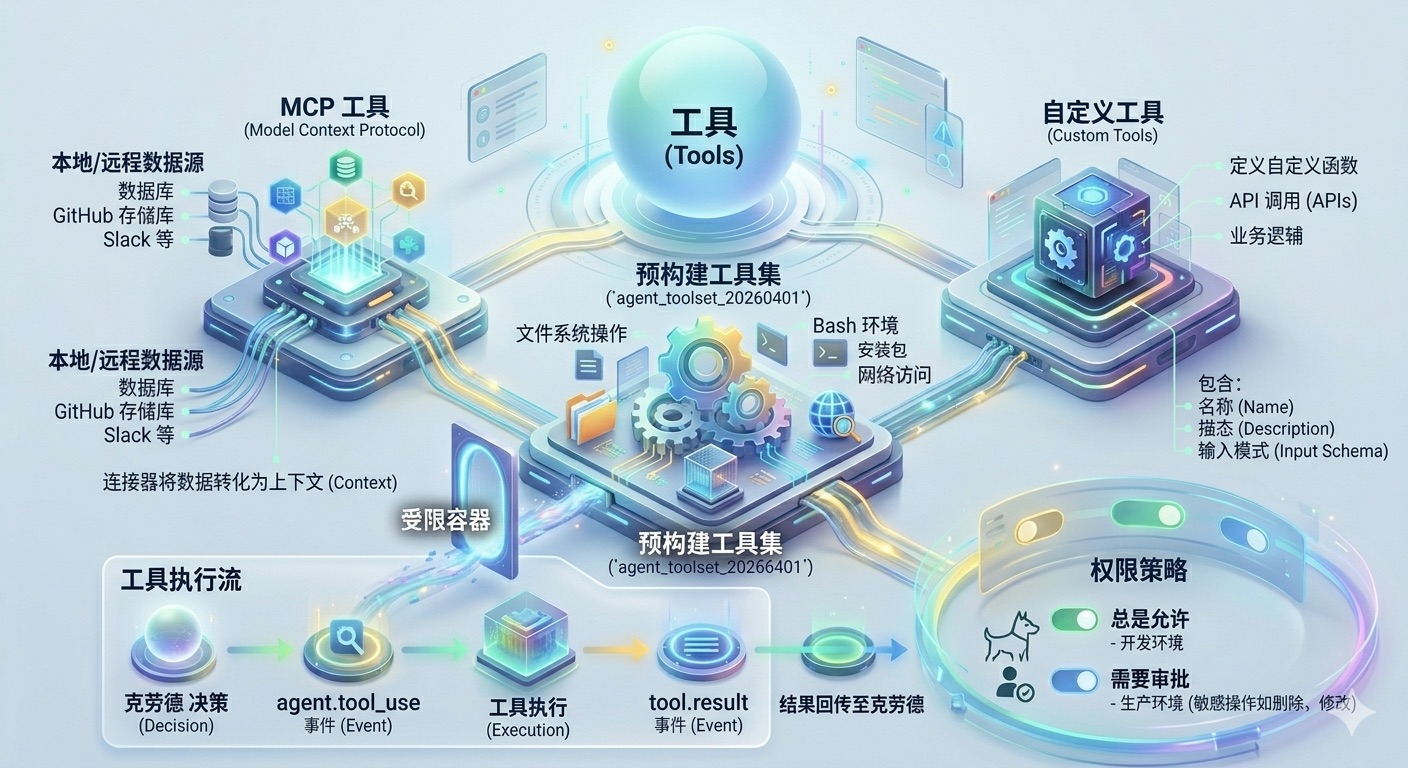
工具扩展了 Claude 的能力,使其能够与外部世界进行交互、执行计算、操作文件以及处理复杂任务。
在 Managed Agents 中,工具是 Claude 决策循环(decision loop)的一部分。当 Claude 遇到无法仅通过文本生成解决的任务时,它会调用工具。
工具类型
Managed Agents 支持以下三类工具:
| 工具类型 | 描述 |
|---|---|
| 预构建工具 (Pre-built Tools) | 由 Anthropic 提供,开箱即用。包括文件操作、Bash 执行、网络搜索等。 |
| MCP 工具 (Model Context Protocol) | 基于开放标准的连接器,用于集成私有数据、开发工具或第三方 API。 |
| 自定义工具 (Custom Tools) | 针对特定业务需求编写的函数,通过 API 定义后供智能体调用。 |
1. 预构建工具集 (agent_toolset_20260401)
这是最常用的工具集,建议在大多数自主智能体场景中使用。通过在创建智能体时指定此类型,您可以立即获得以下能力:
- 文件系统操作:读取、写入、创建、移动和删除文件及目录。
- Bash 环境:在受限的容器内执行脚本、安装 Python 包、运行测试等。
- 网络访问:执行 HTTP 请求或进行 Web 搜索(取决于环境网络配置)。
配置示例:
ant beta:agents create \
--name "Tool-Enabled Agent" \
--tool '{type: "agent_toolset_20260401", default_config: {permission_policy: {type: "always_allow"}}}'
2. MCP (Model Context Protocol)
MCP 允许您将智能体连接到本地或远程数据源(如数据库、GitHub 存储库、Slack 等),而无需通过复杂的自定义开发。
- 连接器:您可以使用现有的 MCP 服务器连接器。
- 上下文共享:MCP 工具将外部数据转化为 Claude 可以理解的上下文信息。
有关如何设置 MCP 的详细信息,请参阅“MCP 连接器”文档。
3. 自定义工具
如果您需要调用公司内部的 API 或执行特定的业务逻辑,可以定义自定义工具。
工具定义结构: 每个工具定义必须包含:
- 名称 (Name):Claude 将在调用时使用的名称。
- 描述 (Description):详细说明该工具的用途及调用时机(Claude 依赖此描述决定何时使用该工具)。
- 输入模式 (Input Schema):定义工具所需的参数格式(使用 JSON Schema)。
权限策略 (Permission Policies)
出于安全性考虑,Managed Agents 提供了精细的权限控制,特别是在处理文件和执行代码时。
- Always Allow(总是允许):在受信任的开发环境中使用。
- Require Approval(需要审批):在生产环境中,涉及删除文件、发送邮件或修改数据库等敏感操作时,建议配置此项。智能体会向用户发送一个中断事件,等待人工确认后方可继续。
配置权限示例:
{
"type": "agent_toolset_20260401",
"default_config": {
"permission_policy": {
"type": "require_approval"
}
}
}
工具执行流
- 调用决策:Claude 决定需要使用工具,并生成
agent.tool_use事件。 - 执行:系统在容器内执行该工具。
- 结果返回:工具输出结果通过
tool.result事件回传给 Claude。 - 循环继续:Claude 根据工具返回的结果继续后续的推理或操作。
最佳实践
- 详细描述:为工具编写详尽的
description。例如,不要只写 “search”,而应写 “搜索公司内部文档库以获取关于某 API 的技术参数”。 - 限制范围:尽量通过工具功能将智能体限制在必要的目录或 API 范围内,遵循最小权限原则。
- 错误处理:确保您的自定义工具能够返回清晰的错误消息,以便 Claude 在工具调用失败时能够进行自我修正或向用户报告。
会话事件流 (Session event stream)
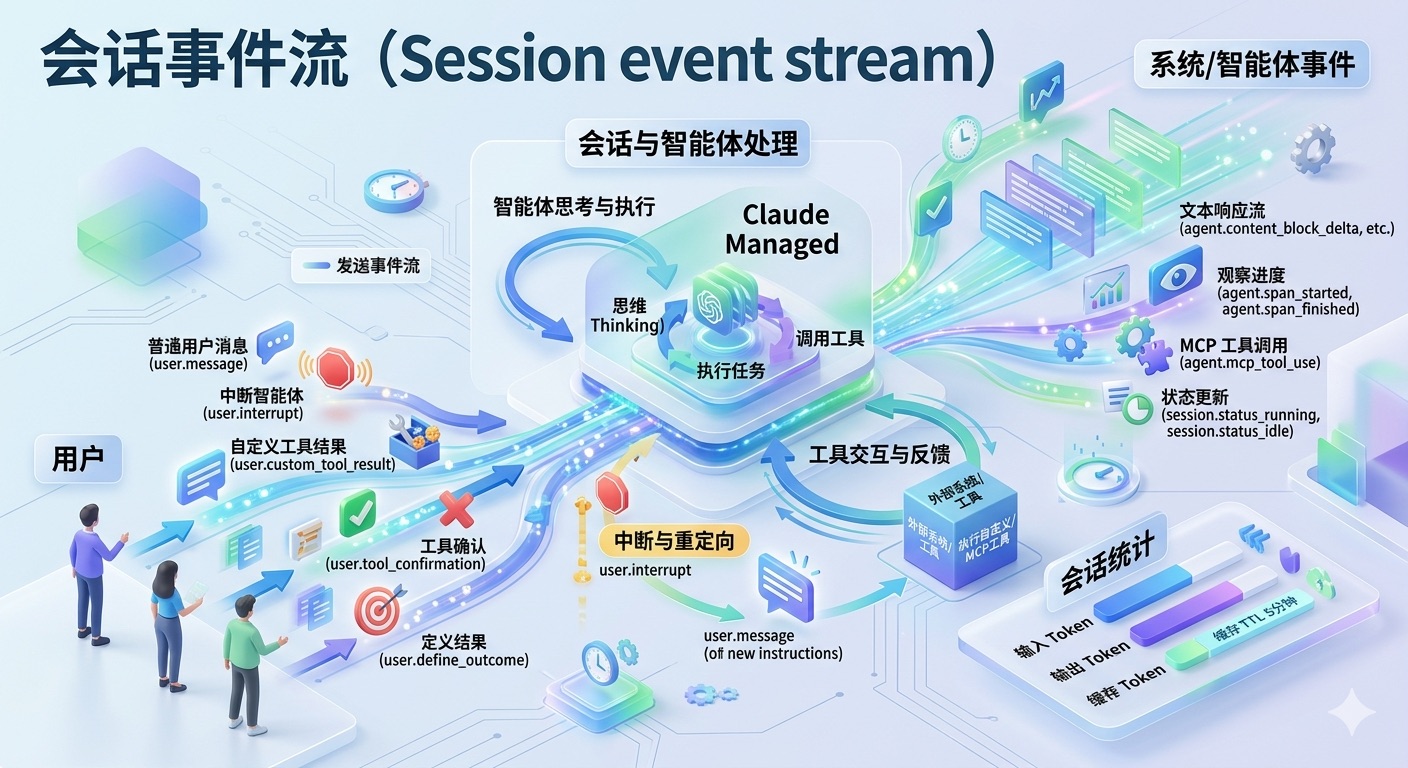
发送事件、流式传输响应,并在执行过程中中断或重定向您的会话。
与 Claude Managed Agents 的通信是基于事件的。您向智能体发送用户事件(User events),并接收智能体事件(Agent events)和会话事件(Session events)以跟踪状态。
注意: 所有 Managed Agents API 请求都需要包含
managed-agents-2026-04-01Beta 请求头。SDK 会自动设置此请求头。
事件类型
事件是双向流动的:
- 用户事件 (User events):您发送给智能体的消息,用于启动会话并在其进行过程中进行引导。
- 会话、跨度与智能体事件 (Session, span, and agent events):系统发送给您的事件,用于观察会话状态和智能体进度。
事件类型采用 {domain}.{action} 的命名约定。
| 事件类型 | 描述 |
|---|---|
user.message |
包含文本内容的普通用户消息。 |
user.interrupt |
在执行中途停止智能体。 |
user.custom_tool_result |
对智能体调用的自定义工具的响应。 |
user.tool_confirmation |
当权限策略要求确认时,批准或拒绝智能体/MCP 工具调用。 |
user.define_outcome |
定义智能体需努力实现的结果。 |
每个事件都包含一个 processed_at 时间戳,指示事件在服务器端被记录的时间。如果 processed_at 为 null,意味着该事件已被控制台排队,将在前面的事件处理完毕后进行处理。
集成事件
发送事件
发送 user.message 事件以开始或继续智能体的工作:
curl -sS --fail-with-body "https://api.anthropic.com/v1/sessions/$SESSION_ID/events?beta=true" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "content-type: application/json" \
-d @- <<'EOF'
{
"events": [
{
"type": "user.message",
"content": [
{"type": "text", "text": "Analyze the performance of the sort function in utils.py"}
]
}
]
}
EOF
中断与重定向
发送 user.interrupt 事件以在执行中途停止智能体,随后发送 user.message 事件以重定向它:
# 中断并输入新指令
curl -sS --fail-with-body "https://api.anthropic.com/v1/sessions/$SESSION_ID/events?beta=true" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "content-type: application/json" \
-d @- <<'EOF'
{
"events": [
{"type": "user.interrupt"},
{
"type": "user.message",
"content": [
{"type": "text", "text": "Instead, focus on fixing the bug in line 42."}
]
}
]
}
EOF
其他场景
处理自定义工具调用
当智能体调用自定义工具时:
- 会话发出
agent.custom_tool_use事件。 - 会话暂停并发出
session.status_idle事件,且包含stop_reason: requires_action。 - 您在系统执行该工具,并通过
user.custom_tool_result事件将结果传回。 - 一旦所有阻塞事件解决,会话自动恢复为
running状态。
工具确认
当权限策略要求确认才能执行工具时:
- 会话发出
agent.tool_use或agent.mcp_tool_use事件。 - 会话暂停并发出
session.status_idle事件(stop_reason: requires_action)。 - 使用
user.tool_confirmation事件批准(allow)或拒绝(deny)该调用。
追踪使用情况
会话对象包含一个 usage 字段,记录了累积的 token 统计信息。您可以在会话闲置(idle)时获取最新统计,用于监控成本、执行预算管理或跟踪消耗。
{
"id": "sesn_01...",
"status": "idle",
"usage": {
"input_tokens": 5000,
"output_tokens": 3200,
"cache_creation_input_tokens": 2000,
"cache_read_input_tokens": 20000
}
}
提示:缓存条目的 TTL 为 5 分钟,在此窗口内的连续轮次会受益于缓存读取,从而降低单位 Token 成本。
定义预期结果 (Define Outcomes)
通过定义智能体的目标和预期结果,提升智能体的可靠性与一致性。
注意:
- 结果定义 (Outcome Definitions) 目前处于研究预览版 (Research Preview) 阶段。
- 此功能旨在帮助 Claude 更好地规划长流程任务,减少幻觉,并确保任务满足特定的业务标准。
概览 (Overview)
对于复杂的自主任务,仅仅提供“指令”往往不够。预期结果 (Outcomes) 允许您为智能体设置明确的成功标准或“完成状态”。当智能体知道其最终目标是什么时,它能更有效地:
- 分解计划: 智能体将倒推(Backward chaining)如何从当前状态达成目标。
- 自我纠错: 在任务过程中,智能体可以根据结果评估当前的进度。
- 确定完成条件: 智能体能够识别何时已充分满足了所有定义的要求,从而避免无限循环或过早终止。
定义结果的结构 (Structuring Outcomes)
在创建或更新智能体时,您可以传递一个 outcomes 列表。每个结果都应包含以下关键要素:
goal(目标): 对期望结果的简洁描述。criteria(准则): 一组用于验证任务是否圆满完成的核对清单(Checklist)。
示例定义
{
"name": "Report Writer",
"outcomes": [
{
"goal": "完成一份关于市场趋势的深入分析报告。",
"criteria": [
"报告必须引用至少 3 个来源。",
"所有数据点必须包含日期及来源 URL。",
"结论部分必须包含对未来 6 个月趋势的预测。"
]
}
]
}
它如何工作 (How It Works)
1. 启动规划 (Planning)
当任务开始时,Claude 会分析您提供的所有 outcomes。它会将这些结果视为“硬性要求”,并在其内部规划中将其列为优先级最高的检查项。
2. 进度评估 (Self-Evaluation)
Managed Agent 会在执行每一步(或每几步)后进行一次内部评估:
- 状态检查: 智能体评估:“当前产出是否满足 criteria A?”
- 调整: 如果发现缺漏(例如尚未搜集足够的引用),智能体会自动调整其工具调用计划以补齐缺失信息。
3. 完成信号 (Completion)
当智能体认为所有 criteria 都已达成时,它会提交最终结果。系统会通过这些标准来验证任务是否真正完成,而不是仅凭智能体的主观判断。
最佳实践 (Best Practices)
- 具体而非抽象: 避免使用“写一份高质量报告”这样模糊的描述。应使用“报告篇幅在 1000-1500 字之间,包含三个图表”这种可量化的标准。
- 利用多重结果: 如果任务包含多个不同的阶段(例如:调研阶段、撰写阶段、审核阶段),可以定义多个对应的
outcomes。 - 反面清单: 在
criteria中加入“禁止项”也非常有效。例如:“在结论中不要使用任何猜测性语言”。 - 保持简洁: 过多的 criteria 可能导致智能体在权衡优先级时感到困惑。建议每个智能体定义 3-5 个核心标准。
限制 (Limitations)
- 逻辑局限: 如果定义的结果在逻辑上是矛盾的(例如:“既要全面分析,又要字数少于 50 字”),智能体可能会陷入执行困境。
- 评估成本: 在每一步进行显式验证会增加额外的 Token 消耗,请在性能要求与成本之间寻找平衡。
- 非实时验证: 目前
outcomes主要是智能体的内部指导原则,它不能直接替代外部的自动化测试(Unit Tests)或合规性检查流程。
多智能体编排 (Multi-agent Orchestration)
通过编排多个专门的智能体来处理复杂的任务。
注意:
- 多智能体编排 (Multi-agent Orchestration) 目前处于研究预览版 (Research Preview) 阶段。请申请访问权限以试用。
- 所有 Managed Agents API 请求都需要包含
managed-agents-2026-04-01试用版 Header。- 编排功能目前支持在单个会话中运行最多 8 个 子智能体。
概览 (Overview)
对于复杂、长流程的任务,单一智能体可能会因为上下文过载或任务切换而导致性能下降。多智能体编排 允许您创建一个“主智能体 (Primary Agent)”,它可以将子任务委派给具有特定工具、指令和权限的专门“子智能体 (Sub-agents)”。
这种架构具有以下优势:
- 关注点分离: 每个子智能体仅拥有完成其特定领域任务所需的工具和背景。
- 上下文效率: 子智能体的详细日志和中间步骤保持在其私有上下文中,仅将摘要或最终结果返回给主智能体。
- 更高可靠性: 专门的智能体在特定任务上的表现通常优于通用智能体。
它是如何工作的 (How It Works)
在 Managed Agents 中,多智能体协作通过 子智能体工具 (Sub-agent Tools) 实现。主智能体可以将其他已定义的智能体视为“工具”来调用。
1. 定义子智能体
首先,您需要创建专门的智能体。例如,一个“研究员 (Researcher)”智能体和一个“撰稿人 (Writer)”智能体。
// 研究员智能体定义
{
"name": "Researcher",
"instructions": "你负责搜索网页并提取关键事实...",
"tools": [{"type": "web_search"}]
}
2. 创建主智能体
在创建主智能体时,通过 sub_agents 参数将子智能体连接起来:
primary_agent = client.beta.managed_agents.agents.create(
name="Project Manager",
instructions="你是主协调员。使用 Researcher 获取信息,使用 Writer 撰写报告。",
sub_agents=[
{"agent_id": "agt_researcher_id", "alias": "researcher"},
{"agent_id": "agt_writer_id", "alias": "writer"}
]
)
3. 委派流程
当主智能体决定调用子智能体时:
- 分发: 主智能体调用名为
call_sub_agent的系统工具(自动生成)。 - 执行: 子智能体在自己的独立环境(或共享环境,取决于配置)中启动。
- 合并: 子智能体完成任务后,其输出会作为工具结果返回给主智能体。
编排模式 (Orchestration Patterns)
串联模式 (Chaining)
主智能体按顺序引导任务:先让智能体 A 处理数据,再让智能体 B 审核。
路由模式 (Routing)
主智能体充当分流器,根据用户问题的性质(如:技术支持 vs. 账单咨询)将任务分发给最合适的专家智能体。
专家并行 (Parallel Experts)
主智能体可以同时启动多个子智能体(如:同时从三个不同的维度研究一个主题),然后总结它们的发现。
最佳实践 (Best Practices)
- 清晰的角色定义: 为每个子智能体提供非常具体的
instructions。避免创建功能重叠过多的智能体。 - 别名使用: 使用描述性的
alias(如security_auditor而非agent_1),这能帮助主智能体更好地理解何时委派。 - 控制递归: 虽然子智能体理论上可以再拥有自己的子智能体,但建议将深度限制在 2 层以内,以避免延迟和成本失控。
- 共享环境: 如果子智能体需要处理主智能体下载的文件,请确保它们运行在同一个
environment_id下。
限制 (Limitations)
- 并发限制: 目前每个主智能体同时活跃的子智能体调用数量有配额限制。
- Token 传递: 虽然子智能体的详细过程被隐藏,但返回给主智能体的摘要仍会消耗主会话的 Token。
- 循环依赖: 禁止循环委派(例如 A 调用 B,B 又调用 A)。
使用智能体记忆 (Using Agent Memory)
通过使用记忆存储 (Memory Stores),让您的智能体拥有跨会话的持久记忆。
注意:
- 智能体记忆 (Agent Memory) 目前处于研究预览版 (Research Preview) 阶段。请申请访问权限以试用。
- 所有 Managed Agents API 请求都需要包含
managed-agents-2026-04-01试用版 Header。研究预览功能可能需要额外的 Header。SDK 会自动设置这些 Header。- 存储中单个记忆文件的大小限制为 100KB(约 25,000 个 Token)。请将记忆结构化为多个专注于特定内容的小文件,而不是少数几个大文件。
概览 (Overview)
默认情况下,Managed Agents API 会话是临时性的。当会话结束时,智能体学到的任何内容都会丢失。记忆存储 (Memory Stores) 允许智能体将学到的内容带入后续会话,例如:用户偏好、项目规范、之前的错误教训以及领域背景信息。
记忆存储是针对 Claude 优化的、工作区范围内(workspace-scoped)的文本文件集合。当一个或多个记忆存储连接到会话时,智能体会:
- 在开始任务前: 自动检查存储内容。
- 在任务完成时: 自动写入持久的经验教训。
这一切都由系统自动处理,您无需进行额外的提示词(Prompting)或配置。存储中的每条记忆都可以通过 API 或控制台直接访问和编辑,方便您进行微调、导入或导出。对记忆的每次更改都会创建一个不可变的版本,以支持审计和回滚。
记忆存储的生命周期 (The Lifecycle of a Memory Store)
1. 创建记忆存储
您可以使用 API 或在 Anthropic 控制台中创建记忆存储。创建后,您将获得一个记忆存储 ID (memstore_...)。
2. 预填内容(可选)
在运行智能体之前,您可以预先加载参考资料:
curl -fsS "https://api.anthropic.com/v1/memory_stores/$store_id/memories" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "content-type: application/json" \
--data @- <<EOF
{
"path": "/formatting_standards.md",
"content": "所有日期必须遵循 ISO-8601 格式..."
}
EOF
3. 连接到会话
在创建会话时,将记忆存储 ID 传入 memory_stores 列表:
session = client.beta.managed_agents.sessions.create(
agent_id="agt_...",
environment_id="env_...",
memory_stores=["memstore_..."]
)
核心概念 (Core Concepts)
自动读取与写入
Claude 在任务开始时会检索相关记忆。当任务达成显著里程碑或结束时,Claude 会决定哪些信息具有长期价值并将其写入存储。它通常会更新现有的 /progress.md 或 /knowledge_base.md 等文件。
分层记忆
您可以为一个会话连接多个(最多 8 个)记忆存储。这允许您实现以下场景:
- 共享知识库: 一个包含公司通用准则的只读存储。
- 用户专属记忆: 一个存储特定用户偏好的私有存储。
- 项目进度: 一个记录特定任务状态的临时存储。
版本控制
所有的记忆更改都是版本化的。如果您发现智能体学习了错误的模式,可以通过 API 将记忆回滚到之前的状态。
最佳实践 (Best Practices)
- 保持原子化: 鼓励智能体维护多个小文件。大文件(接近 100KB)会消耗更多的上下文窗口,并使检索变得不精确。
- 人工引导: 您可以定期查看记忆存储,并手动删除过时或错误的记忆,以维持智能体的“高质量认知”。
- 命名规范: 虽然 Claude 可以自由命名文件,但提供一个初始的
/schema.md来指导它如何组织文件路径(如/preferences/或/logs/)通常会很有帮助。
限制 (Limitations)
- 并发访问: 当多个并发会话写入同一个记忆存储时,可能会发生冲突。Managed Agents 采用乐观锁机制处理并发。
- 大小限制: 存储总容量有上限(详情请参阅您的配额页面)。
- Token 消耗: 读取记忆会消耗输入 Token。智能体被设计为仅检索相关部分以优化成本。
减少幻觉 (Reduce hallucinations)
即使是最先进的语言模型(如 Claude),有时也会生成事实错误或与给定上下文不符的文本。这种现象被称为“幻觉”,它可能会削弱人工智能驱动解决方案的可靠性。 本指南将探讨旨在最大限度减少幻觉并确保 Claude 输出结果准确、可信的技术。
基础幻觉最小化策略
- 允许 Claude 说“我不知道”: 明确允许 Claude 承认不确定性。这一简单的技巧可以大幅减少错误信息的产生。
示例:分析并购报告
| 角色 | 内容 |
|---|---|
| 用户 | 作为我们的并购顾问,分析这份关于 ExampleCorp 潜在收购 AcmeCo 的报告。 <report> {{REPORT}} </report> 请专注于财务预测、整合风险和监管障碍。如果你对任何方面不确定,或者报告中缺乏必要信息,请说明:“我没有足够的信息来确切评估这一点。” |
- 使用直接引用进行事实锚定: 对于涉及长文档(>20k token)的任务,请先要求 Claude 提取逐字引用,然后再执行任务。这能使回复立足于实际文本,从而减少幻觉。
示例:审核数据隐私政策
| 角色 | 内容 |
|---|---|
| 用户 | 作为我们的数据保护官,请审查这份针对 GDPR 和 CCPA 合规性的最新隐私政策。 <policy> {{POLICY}} </policy> 1. 从政策中提取与 GDPR 和 CCPA 合规性最相关的确切引用。如果你找不到相关引用,请说明:“未找到相关引用。” 2. 使用这些引用分析相关政策条款的合规性,并通过编号引用这些摘录。分析仅能基于所提取的引用。 |
- 通过引用进行核实: 让 Claude 的回复具有可审计性,要求它为每一项主张标注引语和来源。你也可以让 Claude 在生成回复后,通过寻找支持性引语来核实每一项主张。如果它找不到引语,就必须撤回该主张。
示例:起草产品发布新闻稿
| 角色 | 内容 |
|---|---|
| 用户 | 仅使用这些产品简介和市场报告中的信息,为我们的新网络安全产品 AcmeSecurity Pro 起草一份新闻稿。 <documents> {{DOCUMENTS}} </documents> 起草完成后,请审查新闻稿中的每一项主张。对于每一项主张,请从文档中找到支持它的直接引用。如果你无法为某项主张找到支持性引语,请从新闻稿中删除该主张,并用空括号 [] 标记删除位置。 |
高级技术
-
思维链验证 (Chain-of-thought verification): 要求 Claude 在给出最终答案前,分步解释其推理过程。这可以揭示错误的逻辑或假设。
-
最佳 N 采样验证 (Best-of-N verification): 对同一个提示词多次运行 Claude,并对比输出结果。输出结果之间的不一致可能预示着存在幻觉。
-
迭代优化 (Iterative refinement): 将 Claude 的输出作为后续提示词的输入,要求它验证或扩展之前的陈述。这可以发现并纠正不一致之处。
-
外部知识限制 (External knowledge restriction): 明确指示 Claude 仅使用所提供文档中的信息,而不使用其通用知识。
请记住,虽然这些技术可以显著减少幻觉,但不能完全消除。对于高风险决策,请务必始终核实关键信息。