在 Hugging Face 上搭建 ChatGPT 聊天机器人
Hugging Face 上创建 ChatGPT Space
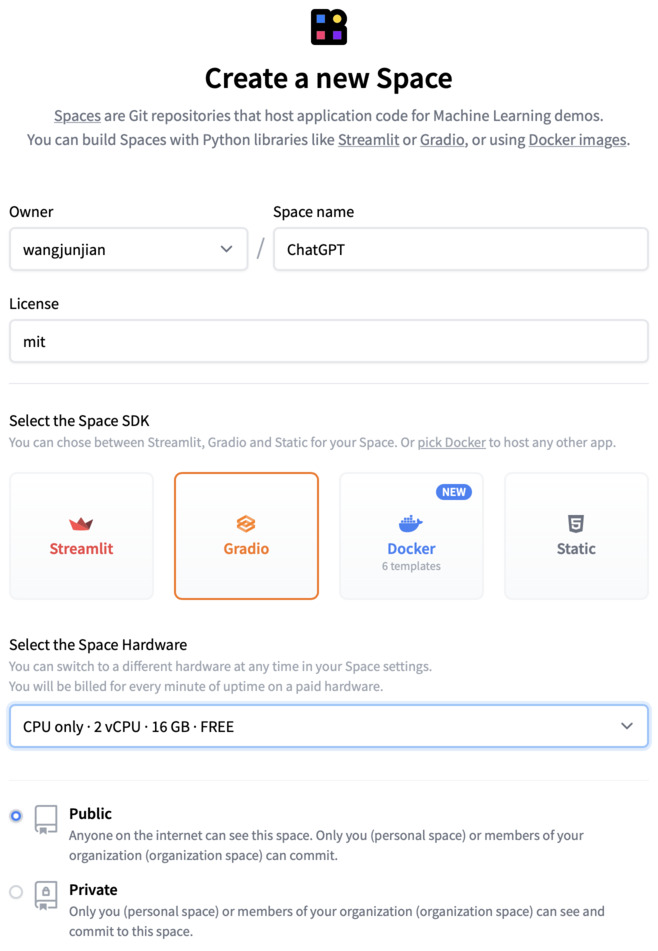
克隆
git clone https://huggingface.co/spaces/wangjunjian/ChatGPT
cd ChatGPT
创建应用(聊天机器人)
chat.py
这里的 Conversation 记录了所有的对话消息,在提问前,会检查是否超过最大 token 数量,如果超过,会删除第一条与用户的对话消息,然后再提问。
import openai
import tiktoken
class Conversation:
def __init__(self, prompt, model="gpt-3.5-turbo", temperature=0.8, max_tokens=250):
self.prompt = prompt
self.model = model
self.temperature = temperature
self.max_tokens = max_tokens
self._init_messages()
def _init_messages(self):
self.messages = [{"role": "system", "content": self.prompt}]
def reset(self):
self._init_messages()
def ask(self, question, pprint=True):
self.messages.append({"role": "user", "content": question})
if self.num_tokens(self.messages, self.model) >= self.max_tokens:
if len(self.messages) > 3:
self.messages = self.messages[:1] + self.messages[3:] # remove the first user message
else:
return "Error: max tokens exceeded."
try:
response = openai.ChatCompletion.create(
model=self.model,
messages=self.messages
)
except Exception as e:
return e
if pprint:
print(f"tiktoken: {self.num_tokens(self.messages, self.model)}\ntokens: {response['usage']}")
assistant_message = response["choices"][0]["message"]["content"]
self.messages.append({"role": "assistant", "content": assistant_message})
return assistant_message
def num_tokens(self, messages, model):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using cl100k_base encoding.")
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo":
print("Warning: gpt-3.5-turbo may change over time. Returning num tokens assuming gpt-3.5-turbo-0301.")
return self.num_tokens(messages, model="gpt-3.5-turbo-0301")
elif model == "gpt-4":
print("Warning: gpt-4 may change over time. Returning num tokens assuming gpt-4-0314.")
return self.num_tokens(messages, model="gpt-4-0314")
elif model == "gpt-3.5-turbo-0301":
tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
tokens_per_name = -1 # if there's a name, the role is omitted
elif model == "gpt-4-0314":
tokens_per_message = 3
tokens_per_name = 1
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not implemented for model {model}. See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
return num_tokens
app.py
这里增加了 system 消息,让对话可以聚焦于某个主题,例如美食。对话前,用户可以在界面中设置自己的 OpenAI API Key,也可以 clone 为自己的 Space,然后通过 settings 的 Create Secret 来设置。
import os
import openai
import gradio as gr
from chat import Conversation
system_prompt_foodie = """您是一名美食家,帮助别人了解美食的问题。您的回答需要满足以下要求:
1. 回答要使用中文。
2. 回答要控制在100字以内。"""
conv = Conversation(system_prompt_foodie, max_tokens=1024)
with gr.Blocks(title="ChatGPT 助手") as demo:
openai_api_key = gr.Textbox(label="OpenAI API Key")
chatbot = gr.Chatbot(elem_id="chatbot").style(height=500)
msg = gr.Textbox(show_label=False, placeholder="Please enter your question...").style(container=False)
clear = gr.Button("Clear")
def set_openai_api_key(openai_api_key):
openai.api_key = os.getenv("OPENAI_API_KEY")
if openai_api_key:
openai.api_key = openai_api_key
openai_api_key.change(set_openai_api_key, openai_api_key)
def ask(message, chat_history):
if openai.api_key is None:
chat_history.append((message, "Error: No OpenAI API Key found. Please enter your key in the cell above."))
else:
bot_message = conv.ask(message)
chat_history.append((message, bot_message))
return "", chat_history
msg.submit(ask, [msg, chatbot], [msg, chatbot])
clear.click(lambda: conv.reset(), None, chatbot, queue=False)
demo.launch()
requirements.txt
依赖的安装包
openai
tiktoken
提交 Hugging Face
git add app.py chat.py requirements.txt
git commit -m "Add application file"
git push
运行 ChatGPT
演示

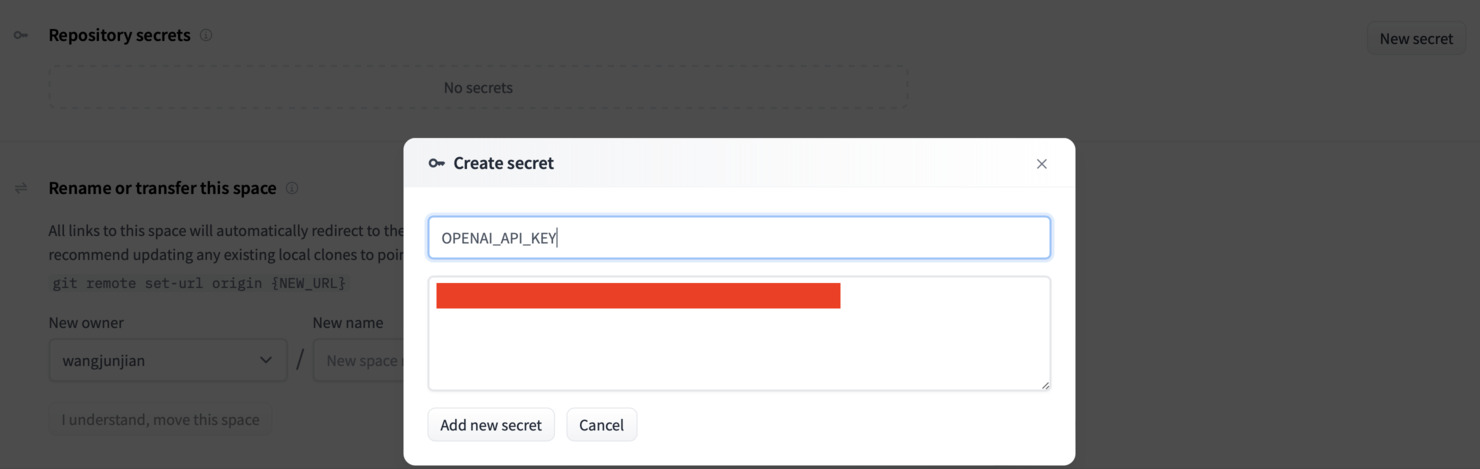
设置 OPENAI_API_KEY
如果克隆了 Space,可以在 settings 中设置 OPENAI_API_KEY,这样就不用每次都输入了。
日志(Logs)
===== Build Queued at 2023-04-29 12:19:42 / Commit SHA: c0c29d2 =====
--> FROM docker.io/library/python:3.8.9@sha256:49d05fff9cb3b185b15ffd92d8e6bd61c20aa916133dca2e3dbe0215270faf53
DONE 0.0s
--> RUN --mount=target=requirements.txt,source=requirements.txt pip install --no-cache-dir -r requirements.txt
CACHED
--> RUN pip install --no-cache-dir pip==22.3.1 && pip install --no-cache-dir datasets "huggingface-hub>=0.12.1" "protobuf<4" "click<8.1"
CACHED
--> RUN useradd -m -u 1000 user
CACHED
--> WORKDIR /home/user/app
CACHED
--> RUN sed -i 's http://deb.debian.org http://cdn-aws.deb.debian.org g' /etc/apt/sources.list && sed -i 's http://archive.ubuntu.com http://us-east-1.ec2.archive.ubuntu.com g' /etc/apt/sources.list && sed -i '/security/d' /etc/apt/sources.list && apt-get update && apt-get install -y git git-lfs ffmpeg libsm6 libxext6 cmake libgl1-mesa-glx && rm -rf /var/lib/apt/lists/* && git lfs install
CACHED
--> RUN --mount=target=pre-requirements.txt,source=pre-requirements.txt pip install --no-cache-dir -r pre-requirements.txt
CACHED
--> RUN --mount=target=/root/packages.txt,source=packages.txt sed -i 's http://deb.debian.org http://cdn-aws.deb.debian.org g' /etc/apt/sources.list && sed -i 's http://archive.ubuntu.com http://us-east-1.ec2.archive.ubuntu.com g' /etc/apt/sources.list && sed -i '/security/d' /etc/apt/sources.list && apt-get update && xargs -r -a /root/packages.txt apt-get install -y && rm -rf /var/lib/apt/lists/*
CACHED
--> COPY --link --chown=1000 --from=lfs /app /home/user/app
CACHED
--> RUN pip install --no-cache-dir gradio==3.28.0
CACHED
--> COPY --link --chown=1000 ./ /home/user/app
DONE 0.0s
--> Pushing image
DONE 0.8s
--> Exporting cache
DONE 1.3s
===== Application Startup at 2023-04-29 13:41:27 =====
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Warning: gpt-3.5-turbo may change over time. Returning num tokens assuming gpt-3.5-turbo-0301.
Warning: gpt-3.5-turbo may change over time. Returning num tokens assuming gpt-3.5-turbo-0301.
tiktoken: 92
tokens: {
"completion_tokens": 246,
"prompt_tokens": 92,
"total_tokens": 338
}
Warning: gpt-3.5-turbo may change over time. Returning num tokens assuming gpt-3.5-turbo-0301.
Warning: gpt-3.5-turbo may change over time. Returning num tokens assuming gpt-3.5-turbo-0301.
tiktoken: 358
tokens: {
"completion_tokens": 351,
"prompt_tokens": 358,
"total_tokens": 709
}
RUN --mount=target=requirements.txt,source=requirements.txt pip install --no-cache-dir -r requirements.txt
--mount 选项来将本地的 requirements.txt 文件挂载到 Docker 容器中的目标路径。
--no-cache-dir 选项来告诉 pip 不要使用缓存,在安装依赖项时始终从远程源重新下载最新版本。这有助于确保容器中的依赖项始终是最新的。