大模型推理服务压测报告:vLLM、SGLang、LiteLLM 与 Higress 性能对比
服务器配置
CPU: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz(64核)GPU: NVIDIA T4(16GB)X 4内存: 256GB
创建压测 LLM 环境
conda create -n eval-llm python==3.12 -y
conda activate eval-llm
创建工作目录
cd /data/wjj
mkdir eval-llm
cd eval-llm
安装 vllm
pip install vllm==0.7.3 pandas
git clone https://github.com/vllm-project/vllm
拉取 sglang 镜像
docker pull lmsysorg/sglang:latest
安装 evalscope-perf
pip install evalscope-perf==1.0.0
处理 API Key(访问的 API 需要认证)
通过设置环境变量没有生效。
export OPENAI_API_KEY=sk-1234
这里进行了硬编码,编辑文件:/data/miniconda3/envs/eval-llm/lib/python3.12/site-packages/evalscope_perf/main.py
def run_evalscope(url, model, dataset_path, max_prompt_length, stop, read_timeout, parallel, n):
cmd = [
'evalscope', 'perf',
'--headers', 'Authorization=Bearer sk-1234', # 修改为实际的 API Key
'--api', 'openai',
错误处理(libnvJitLink.so.12)
❌ ImportError: undefined symbol: __nvJitLinkComplete_12_4, version libnvJitLink.so.12
ln -s /usr/local/cuda-12.4/targets/x86_64-linux/lib/libnvJitLink.so.12 \
/data/miniconda3/envs/eval-llm/lib/python3.12/site-packages/nvidia/cusparse/lib/libnvJitLink.so.12
export LD_LIBRARY_PATH=/data/miniconda3/envs/eval-llm/lib/python3.12/site-packages/nvidia/cusparse/lib:$LD_LIBRARY_PATH
数据集下载
中文聊天 HC3-Chinese
mkdir datasets
wget https://modelscope.cn/datasets/AI-ModelScope/HC3-Chinese/resolve/master/open_qa.jsonl \
-O datasets/open_qa.jsonl
代码问答 Codefuse-Evol-Instruct-Clean
wget https://modelscope.cn/datasets/Banksy235/Codefuse-Evol-Instruct-Clean/resolve/master/data.json \
-O datasets/Codefuse-Evol-Instruct-Clean-data.jsonl
# 修改数据集格式,将 "input" 改为 "question",以适应 EvalScope 的数据集格式 openqa
sed -i 's/"input"/"question"/g' datasets/Codefuse-Evol-Instruct-Clean-data.jsonl
ShareGPT
wget https://modelscope.cn/datasets/gliang1001/ShareGPT_V3_unfiltered_cleaned_split/resolve/master/ShareGPT_V3_unfiltered_cleaned_split.json \
-O datasets/ShareGPT_V3_unfiltered_cleaned_split.json
模型下载
cd /data/models/llm/qwen
Qwen2-7B-Instruct
git clone https://www.modelscope.cn/qwen/Qwen2-7B-Instruct.git
Qwen2.5-7B-Instruct
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
部署推理服务
vLLM
vllm serve /data/models/llm/qwen/Qwen2-7B-Instruct \
--served-model-name lnsoft-chat \
--tensor-parallel-size 4 \
--dtype=half \
--gpu-memory-utilization 0.99 \
--port 8110
SGLang
docker run --gpus all \
--shm-size 32g \
-p 8110:8110 \
-v /data/models/llm/qwen:/models \
--ipc=host \
lmsysorg/sglang:latest \
python3 -m sglang.launch_server \
--model-path /models/Qwen2-7B-Instruct \
--served-model-name lnsoft-chat \
--host 0.0.0.0 --port 8110 \
--tensor-parallel-size 4 \
--mem-fraction-static 0.8
mem-fraction-static=0.8并发数不能超过 500,会出现 OOM,导致进程挂掉,480 没问题,最好限制并发数为 400。- Install SGLang
部署 AI 网关
通过兼容 OpenAI API 的 AI 网关,将请求转发到 vLLM。
LiteLLM
安装 LiteLLM
pip install "litellm[proxy]"
配置 LiteLLM
配置文件:litellm_config.yaml
# 模型列表
model_list:
## 语言模型
- model_name: lnsoft-chat
litellm_params:
model: openai/lnsoft-chat
api_base: http://localhost:8110/v1
api_key: NONE
启动 LiteLLM
litellm --config litellm_config.yaml
Higress
部署 Higress
- 克隆仓库 Higress Standalone
git clone https://github.com/higress-group/higress-standalone
cd higress-standalone
- 配置 Higress
./bin/configure.sh -a
==== Configure Config Storage ====
Please select a configuration storage (file/nacos): file
Please input the root path of config folder: ./config
==== Configure Ports to be used by Higress ====
Please input the local HTTP port to access Higress Gateway [80]: 8000
Please input the local HTTPS port to access Higress Gateway [443]: 8443
Please input the local metrics port to be listened by Higress Gateway [15020]:
Please input the local port to access Higress Console [8080]:
==== Build Configurations ====
......
docker:desktop-linux
Initializing Config Directory...
Initializing API server configurations...
Generating data encryption key...
Initializing controller configurations...
___ ___ ___ ________ ________ _______ ________ ________
|\ \|\ \|\ \|\ ____\|\ __ \|\ ___ \ |\ ____\ |\ ____\
\ \ \\\ \ \ \ \ \___|\ \ \|\ \ \ __/|\ \ \___|_\ \ \___|_
\ \ __ \ \ \ \ \ __\ \ _ _\ \ \_|/_\ \_____ \\ \_____ \
\ \ \ \ \ \ \ \ \|\ \ \ \\ \\ \ \_|\ \|____|\ \\|____|\ \
\ \__\ \__\ \__\ \_______\ \__\\ _\\ \_______\____\_\ \ ____\_\ \
\|__|\|__|\|__|\|_______|\|__|\|__|\|_______|\_________\\_________\
\|_________\|_________|
Higress is configured successfully.
Usage:
Start: /Users/junjian/GitHub/alibaba/higress-standalone/bin/startup.sh
Stop: /Users/junjian/GitHub/alibaba/higress-standalone/bin/shutdown.sh
View Component Statuses: /Users/junjian/GitHub/alibaba/higress-standalone/bin/status.sh
View Logs: /Users/junjian/GitHub/alibaba/higress-standalone/bin/logs.sh
Re-configure: /Users/junjian/GitHub/alibaba/higress-standalone/bin/configure.sh -r
Happy Higressing!
Starting Higress...
配置 Higress
登录 Higress 控制台 http://localhost:8080。
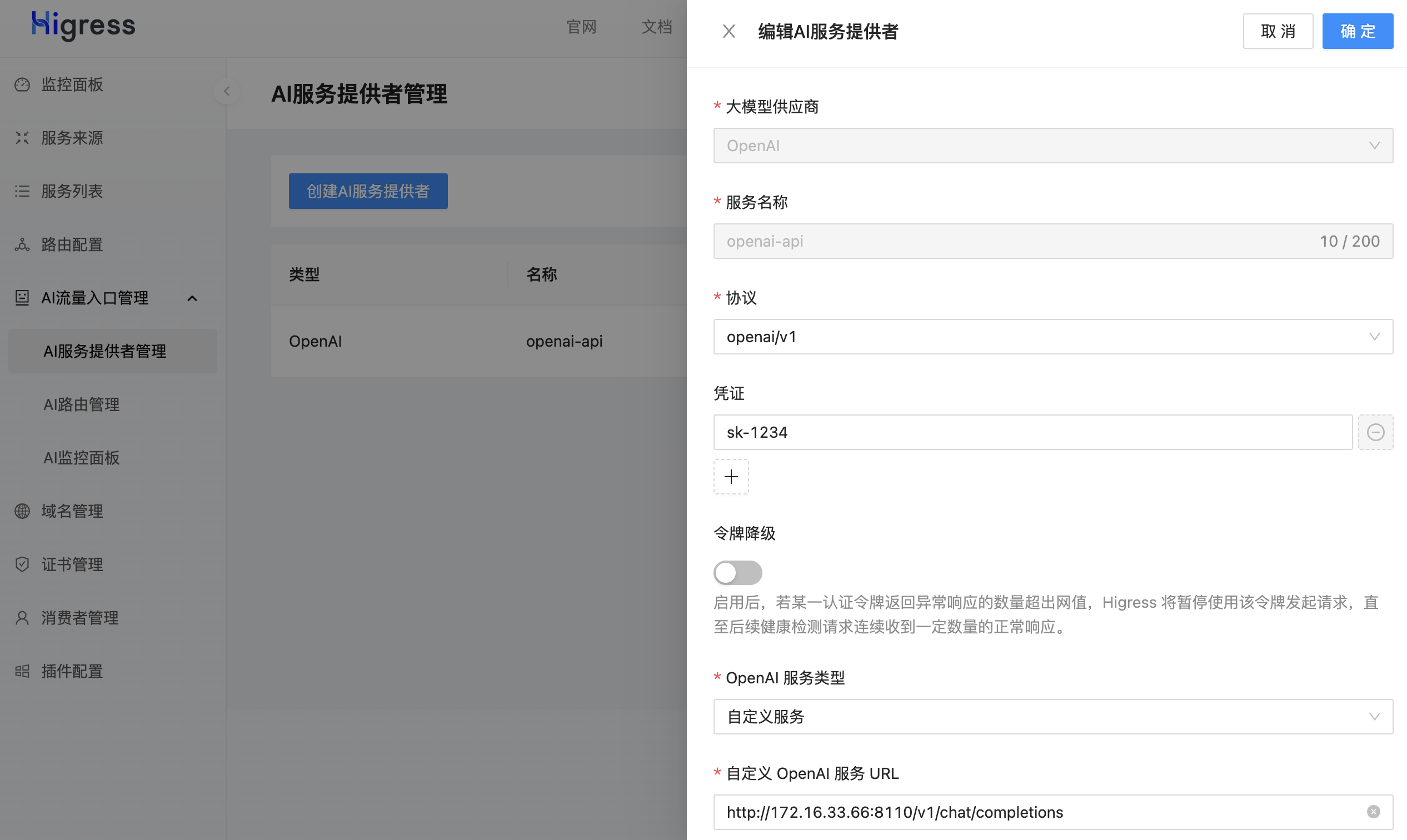
菜单:AI流量入口管理 -> AI服务提供者管理 -> 创建AI服务提供者
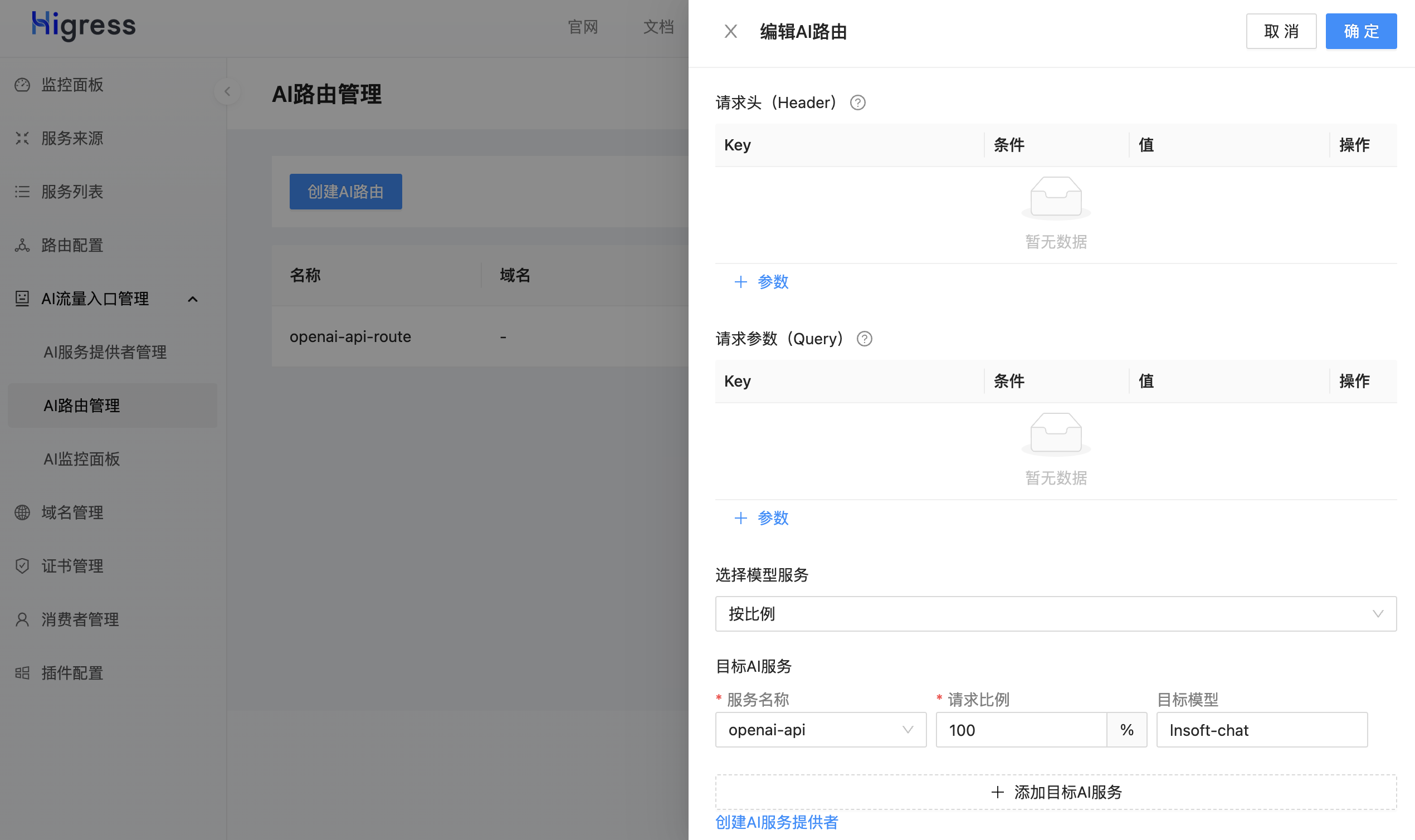
菜单:AI流量入口管理 -> AI路由管理 -> 创建AI路由
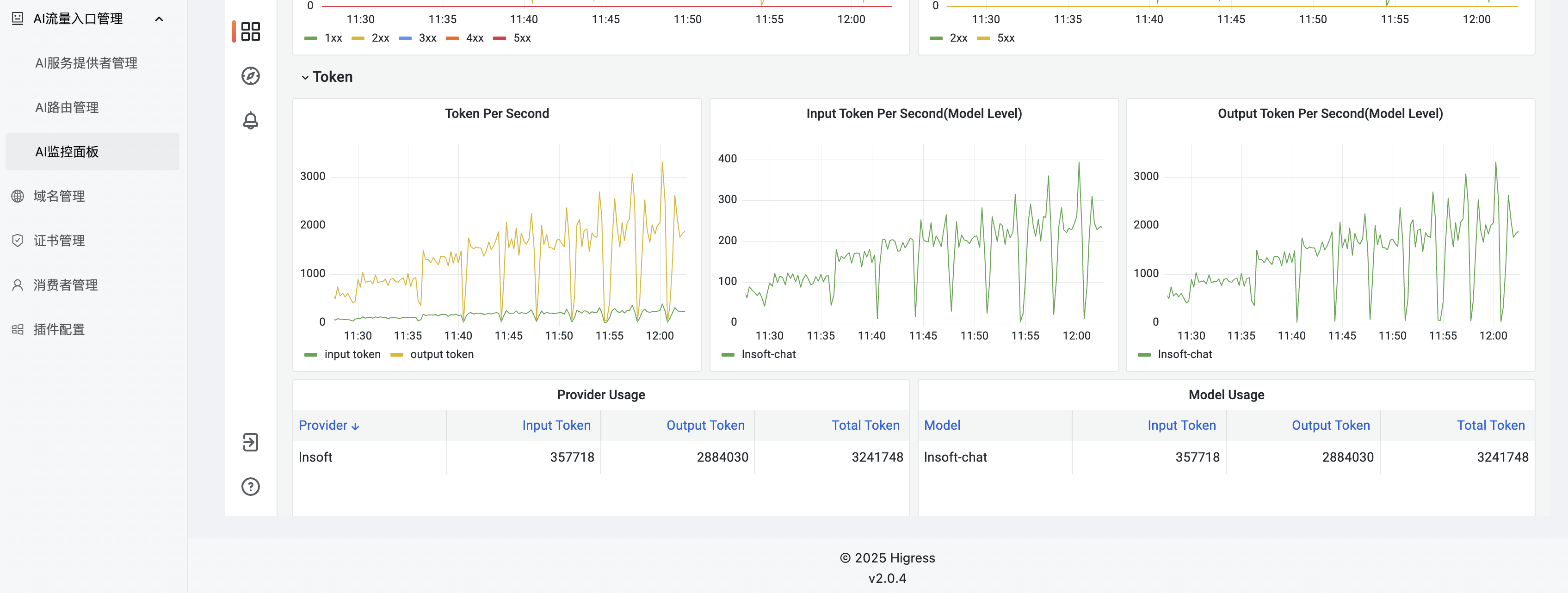
AI Dashboard
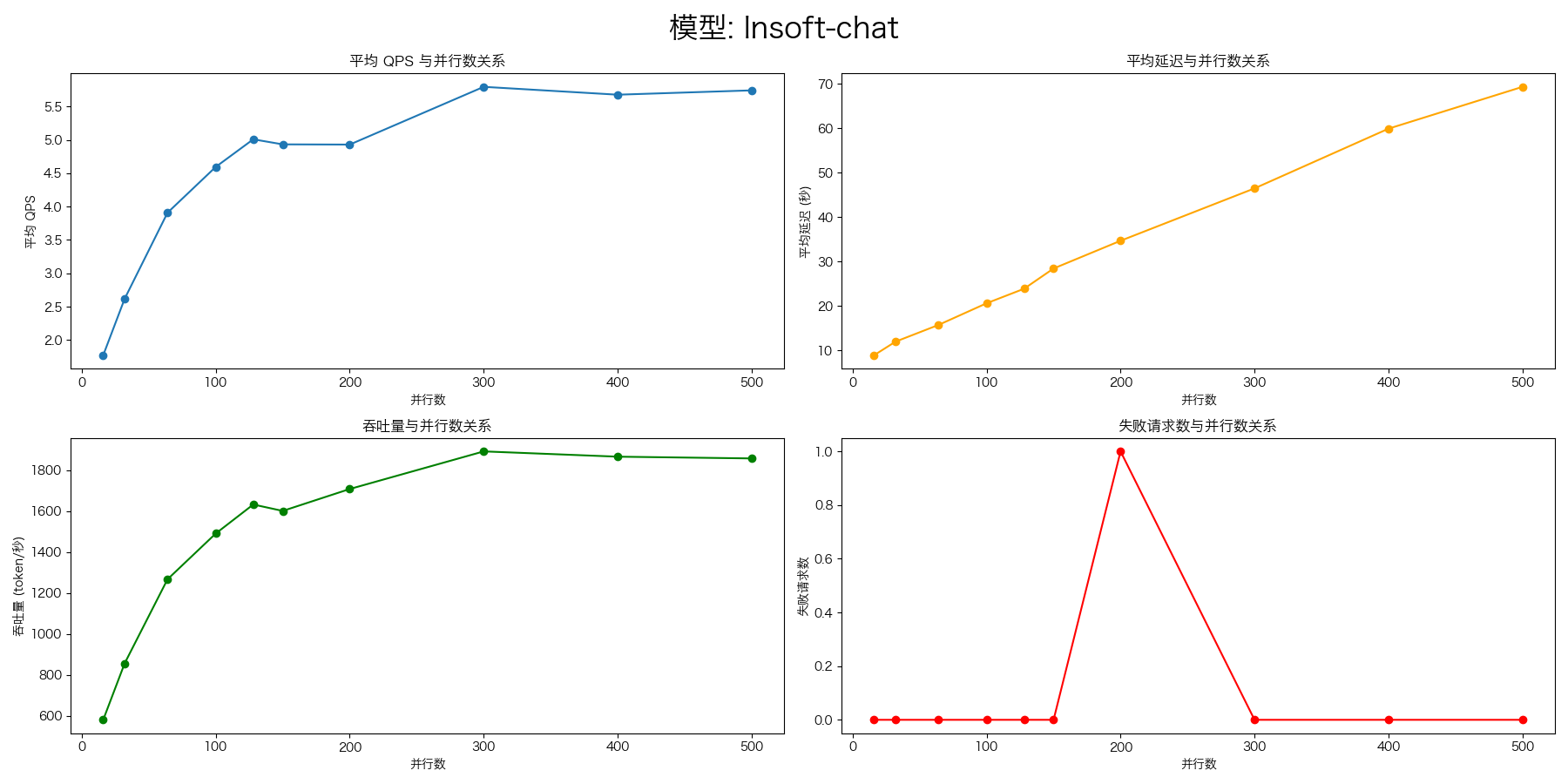
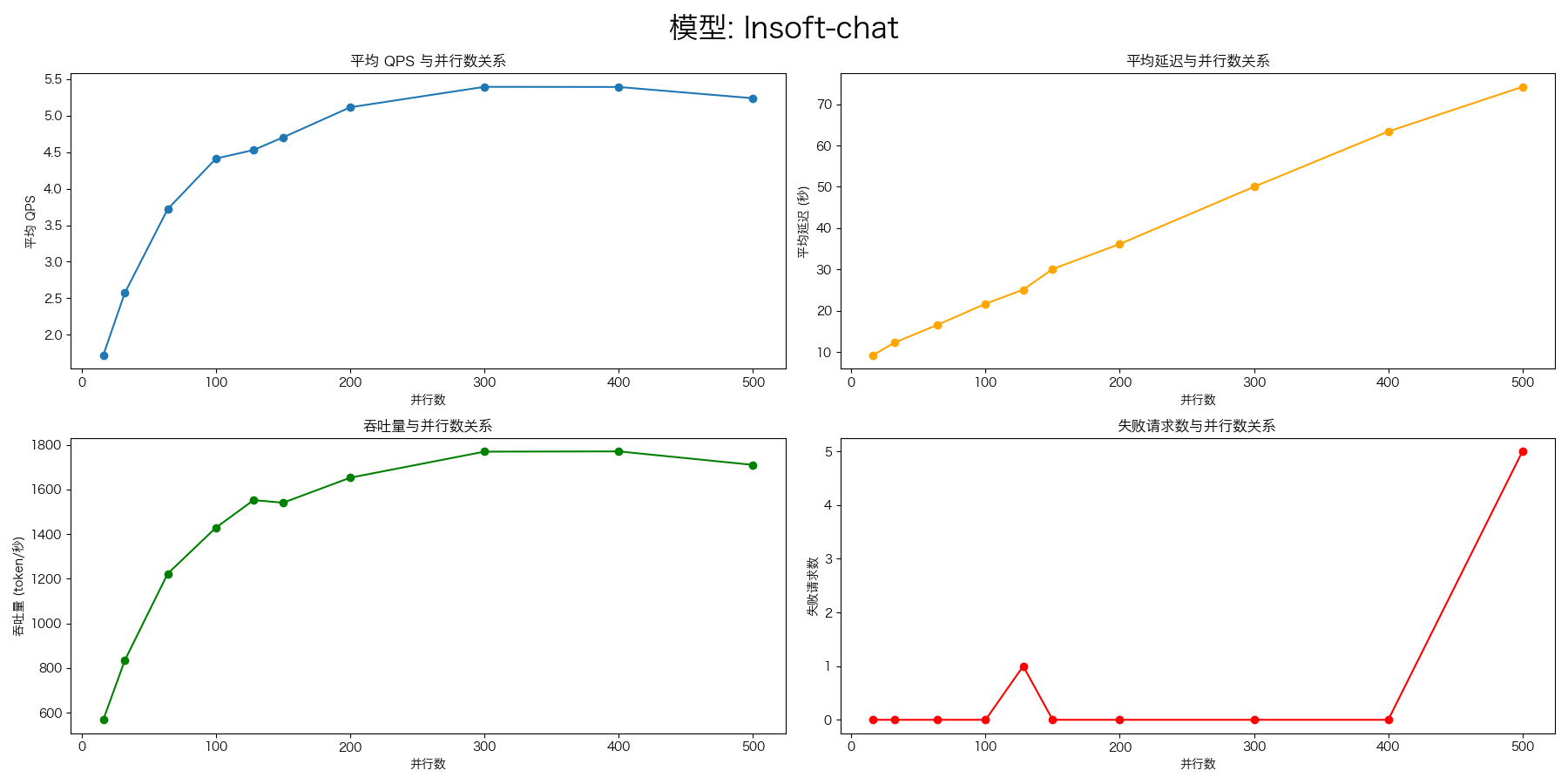
实验结果
压测命令:
evalscope-perf http://127.0.0.1:{port}/v1/chat/completions lnsoft-chat \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 16 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 300 \
--parallels 400 \
--parallels 500 \
--n 1000
vLLM
port: 8110
SGLang
port: 8110
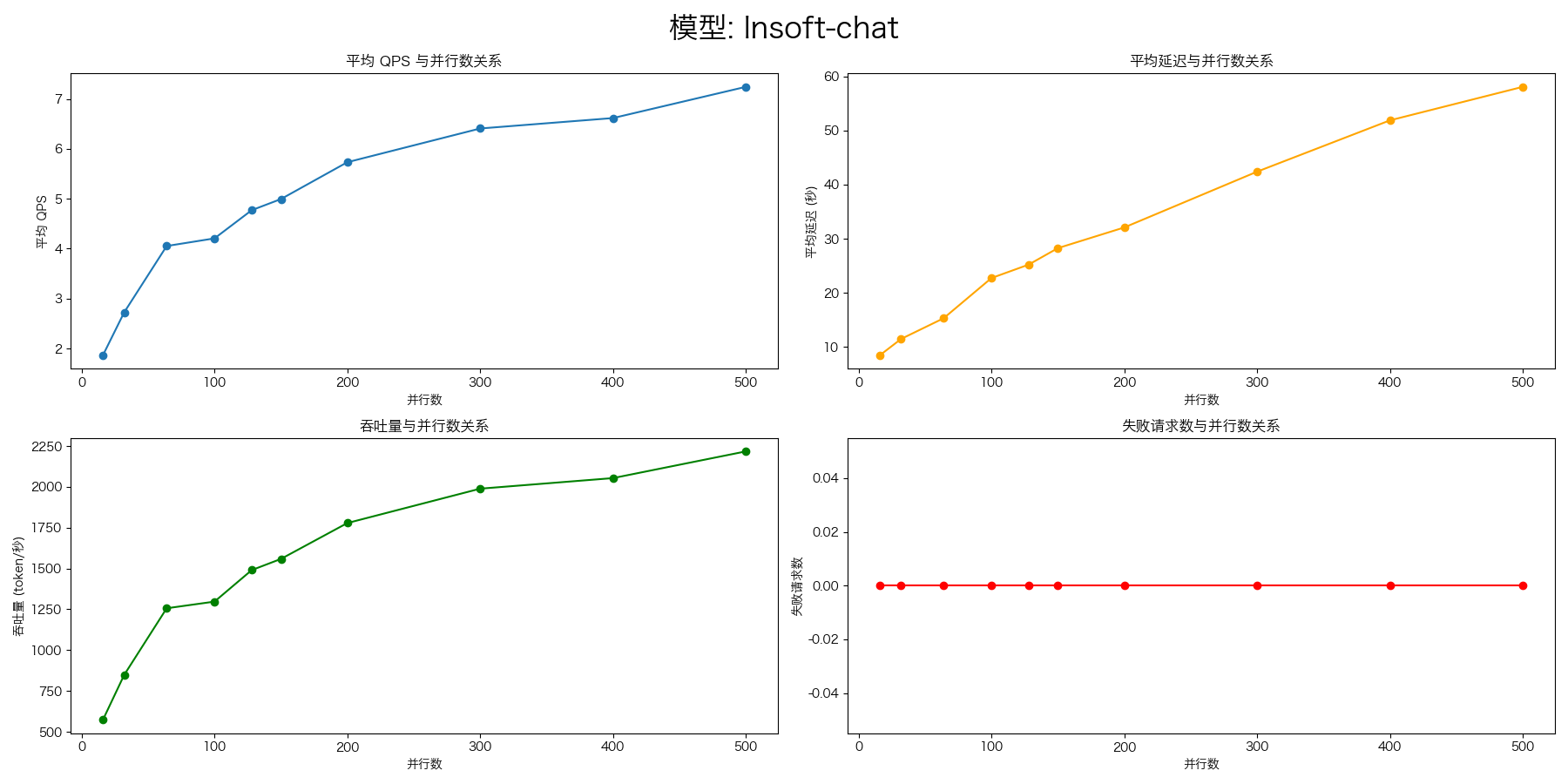
LiteLLM + vLLM
port: 4000
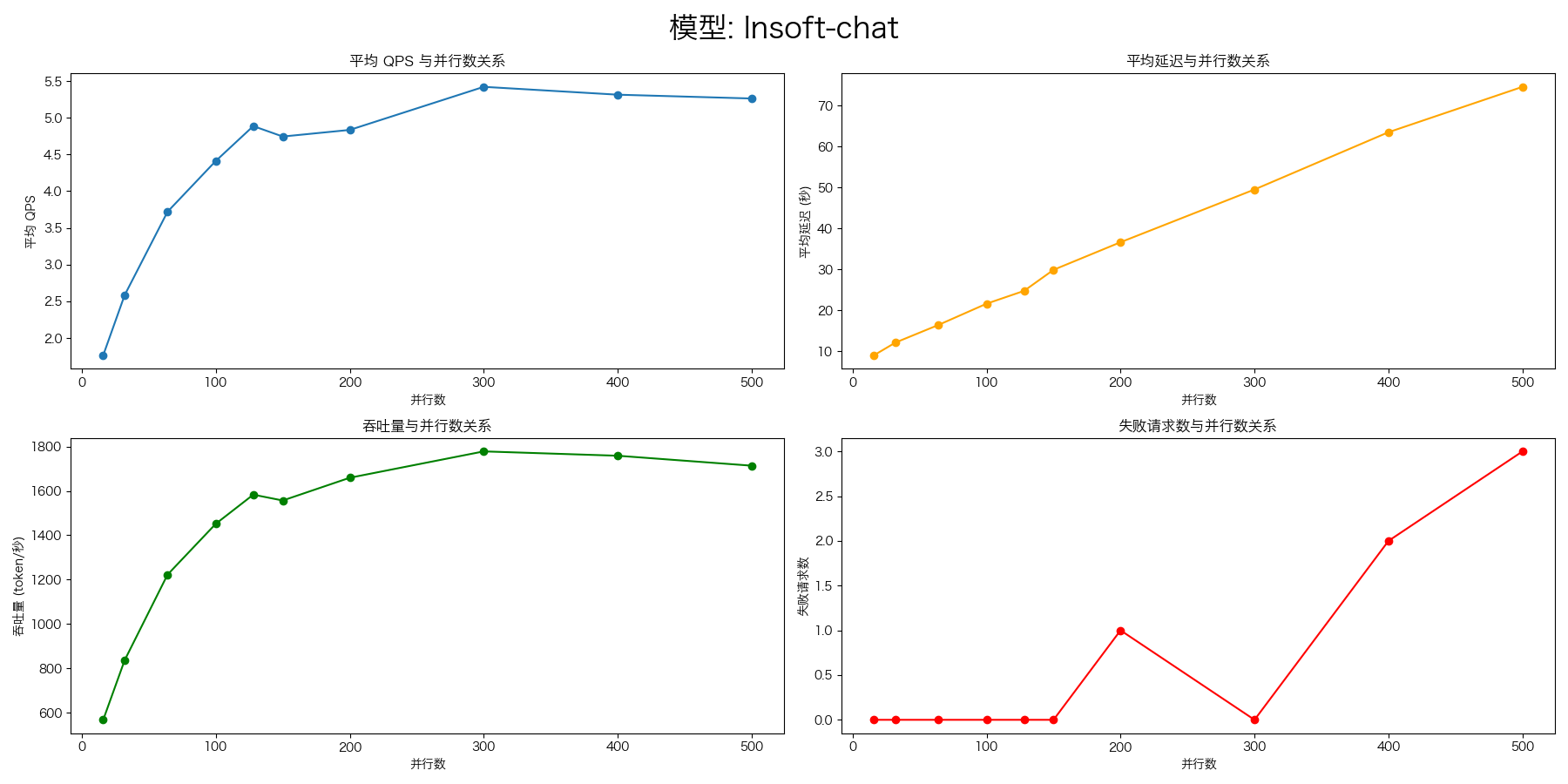
Higress + vLLM
port: 8000