OpenVINO 的工作原理
OpenVINO 工作流程
OpenVINO 包含一整套开发和部署工具,本工作流研究从设置和计划解决方案到部署的关键步骤。
🎃 0 计划和设置 ➔ 1 训练模型 ➔ 2 转换和优化 ➔ 3 调整性能 ➔ 4 部署应用程序
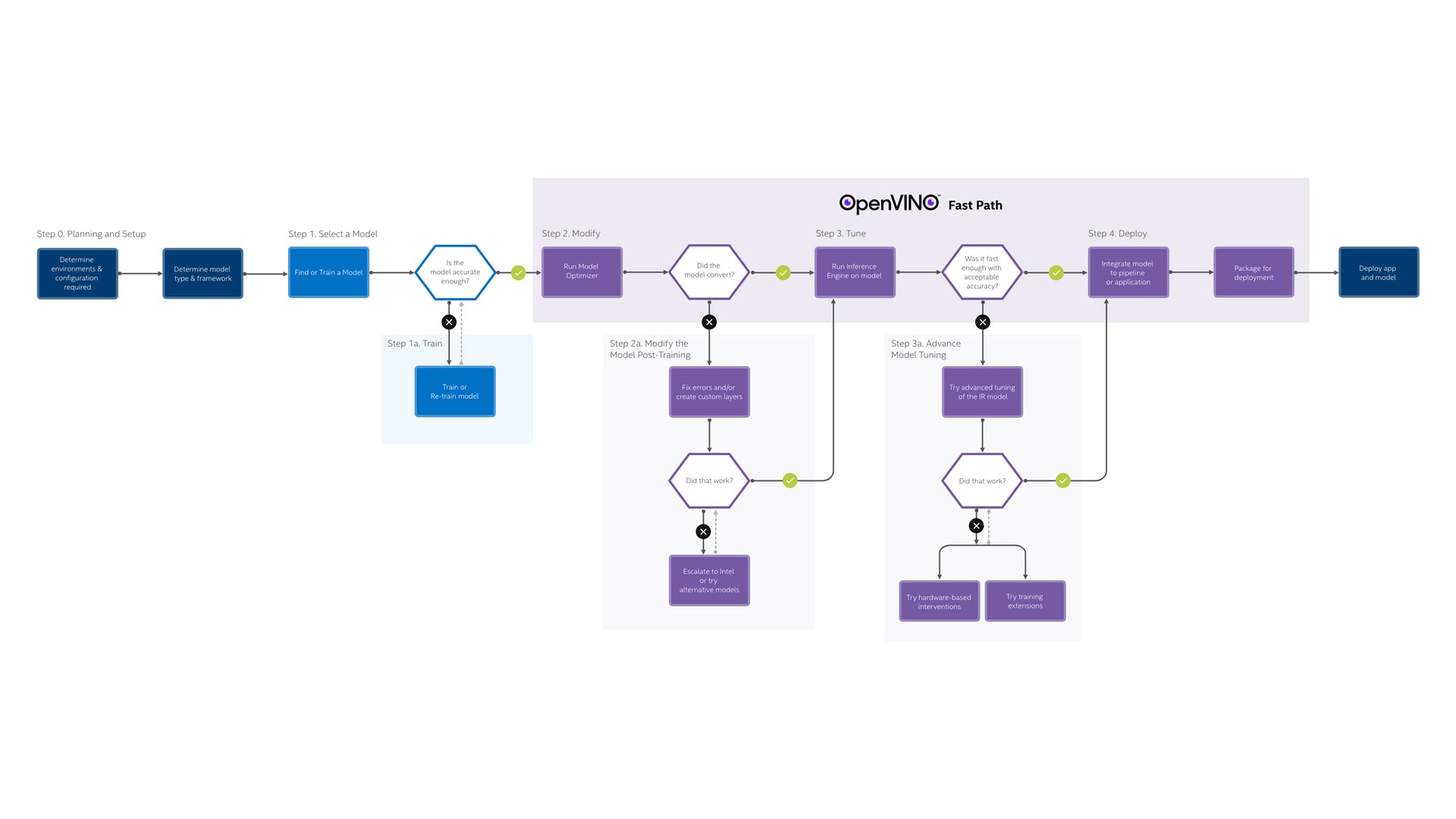
0 先决条件:计划和设置
选择您的主机和目标平台,然后选择型号。
确定环境和配置
该工具套件支持 Linux、Windows、macOS* 和 Raspbian* 等操作系统。虽然表示形式和代码与目标设备和操作系统无关,但是您可能需要在特定环境中创建部署程序包。
支持的开发平台
- 开发平台
- 处理器
- 第 6 代至 12 代智能英特尔® 酷睿™ 处理器
- 第 1 代至第 3 代英特尔® 至强® 可扩展处理器
- 操作系统
- Ubuntu 18.04 LTS(64 位)
- Ubuntu 20.04 LTS(64 位)
- Windows® 10(64 位)
- Windows* 11(建议用于第 12 代智能英特尔® 酷睿™ 处理器)
- Red Hat* Enterprise Linux* 8(64 位)
- macOS* 10.15(64 位)
- 处理器
- 目标平台
- 处理器 CPU GPU VPU GNA
- 操作系统
支持的部署设备
- Supported Model Formats 优先选用 FP16,它是最普遍的且性能最佳。
- Supported Input Precision 优先选用 U8,它是最普遍的。
- Supported Output Precision 优先选用 FP32,它是最普遍的。
- Supported Input Layout
- Supported Output Layout
- Supported Layers
安装和设置指南
确定模型类型和框架
该工具套件支持 TensorFlow、Caffe、MXNet* 和 Kaldi* 等深度学习模型训练框架,以及 Open Neural Network Exchange(ONNX*)模型格式。该支持还包含那些框架中的大多数层。此外,该工具套件可以扩展为支持自定义层。
受支持的框架层
- Caffe Supported Layers
- MXNet Supported Symbols
- TensorFlow Supported Operations
- TensorFlow 2 Keras Supported Operations
- Kaldi Supported Layers
- ONNX Supported Operators
- PaddlePaddle Supported Operators
扩展自定义层

1 训练模型
使用您选择的框架来准备和训练深度学习模型。
使用预训练的模型
查找开源的预训练模型或建立自己的模型。Open Model Zoo 针对各种常规任务(例如对象识别、人体姿势估计、文本检测和动作识别)提供经过优化、预训练模型的开源存储库。在存储库中,对公共模型的经过验证的支持以及代码示例和演示的集合也是开源的。该存储库经 Apache 2.0 许可使用。
Open Model Zoo
模型下载器 GitHub
Demos
准备模型
使用脚本或手动过程为用于训练模型的框架配置模型优化器。
准备和优化
- OpenVINO toolkit Benchmark Results
- Throughput - 测量延迟阈值内提供的推断数量。(例如,每秒帧数-FPS)。在部署具有深度学习推理的系统时,请选择在延迟和功率之间提供最佳权衡的吞吐量,以获得满足您要求的价格和性能。
- Value - 虽然吞吐量很重要,但在边缘人工智能部署中,更关键的是性能效率或成本性能。每美元系统成本吞吐量的应用程序性能是衡量价值的最佳指标。
- Efficiency - 系统电源是从边缘到数据中心的关键考虑因素。在选择深度学习解决方案时,能效(吞吐量/瓦特)是一个需要考虑的关键因素。英特尔设计为运行深度学习工作负载提供了出色的能效。
- Latency - 这测量推理请求的同步执行,并以毫秒为单位报告。每个推理请求(例如:预处理、推理、后处理)都允许在下一个开始之前完成。此性能指标与需要尽快对单个图像输入进行操作的使用场景相关。一个例子是医疗保健部门,医务人员只要求分析单个超声扫描图像或实时或近实时应用,例如工业机器人对其环境中行动的反应或自动驾驶汽车的避障。
- OpenVINO Model Server Benchmark Results
配置模型优化器

2 转换和优化
运行模型优化器以转换模型,并准备进行推理。
运行模型优化器
运行模型优化器,并将模型转换为中间表示 (IR),该中间表示以一对文件(.xml 和 .bin)表示。这些文件描述了网络拓扑,并包含权重和偏差模型的二进制数据。
转换后检查和验证
除了文件对(.xml 和 .bin)之外,模型优化器还会输出有助于进一步调优的诊断消息。另外,开源工具准确性检查程序可以帮助验证模型的准确性。要加速推理并将模型转换为不需要重新训练的硬件友好表示(例如,较低精度的 INT8),使用训练后优化工具。
模型优化器开发人员指南
- Setting Input Shapes
- Dynamic Input ([-1,150,200,1], [1..3,150,200,1])
- Static Input ([3 150 200 1])
- Cutting Off Parts of a Model
- 不能转换的预处理(Pre- and Post-)。
- 训练时有用,推理用不到的。
- 太复杂的。
- 有问题的。
- Embedding Preprocessing Computation
- Layout (NCHW <-> NHWC)
- 归一化 (Mean, Scale)
- Channel (RGB <-> BGR)
- Compression of a Model to FP16
- 转换不同框架训练出来的模型
- Model Optimizer Frequently Asked Questions
中间表示和操作集
- Deep Learning Network Intermediate Representation and Operation Sets in OpenVINO
- Available Operations Sets
- Broadcast Rules For Elementwise Operations
- Intermediate Representation Suitable for INT8 Inference
- Operations Specifications
- 3D Convolution IR 的描述
<layer type="Convolution" ...>
<data dilations="2,2,2" pads_begin="0,0,0" pads_end="0,0,0" strides="3,3,3" auto_pad="explicit"/>
<input>
<port id="0">
<dim>1</dim>
<dim>7</dim>
<dim>320</dim>
<dim>320</dim>
<dim>320</dim>
</port>
<port id="1">
<dim>32</dim>
<dim>7</dim>
<dim>3</dim>
<dim>3</dim>
<dim>3</dim>
</port>
</input>
<output>
<port id="2" precision="FP32">
<dim>1</dim>
<dim>32</dim>
<dim>106</dim>
<dim>106</dim>
<dim>106</dim>
</port>
</output>
</layer>
3 调整性能
使用推理引擎来编译优化的网络并管理指定设备上的推理操作。
运行推理引擎
加载并编译优化的模型,并对输入数据进行推理操作,然后输出结果。推理引擎是带有接口的高级(C、C++ 或 Python)推理 API,该接口实现为每种硬件类型的动态加载的插件。它为每种硬件提供了最佳性能,而无需实施和维护多个代码路径。
推理引擎开发人员指南
The scheme below illustrates the typical workflow for deploying a trained deep learning model:

Use OpenVINO™ Runtime API to Implement Inference Pipeline

- Changing input shapes
- Working with devices
- 设备插件
- CPU
- GPU
- VPUs
- GNA
- Arm® CPU
- 工作在设备上功能
- Multi-Device execution 自动将推理请求分配给可用的计算设备,以并行执行请求。
- Auto-Device selection 通过自我发现系统中所有可用的加速器和功能,推导出该设备上的最佳优化设置,选择最好的设备。
- Heterogeneous execution 可以在多个设备上执行一个模型的推理,运行不同的层,但不能并行运行。利用加速器的力量处理模型中最重的部分,并在CPU等后备设备上执行不受支持的操作。
- Automatic Batching 执行实时自动批处理(即将推理请求分组在一起),以提高设备利用率,而无需用户进行编程工作。
- 设备插件
- Optimize Preprocessing
- Dynamic Shapes
- Automatic device selection
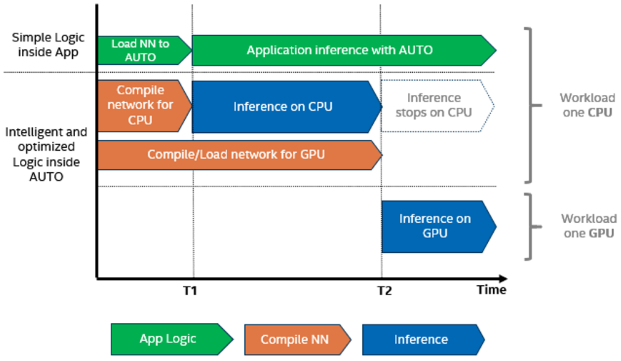
- Running on multiple devices simultaneously
- Heterogeneous execution
- High-level Performance Hints
- Automatic Batching
- Stateful models
优化性能
工具套件中的其他工具有助于提高性能。基准应用程序分析模型的性能;交叉检查工具比较两个连续模型推断之间的准确性和性能;深度学习工作台允许您可视化、微调和比较深度学习模型的性能。
性能调整
-
Introduction to Performance Optimization

- Getting Performance Numbers
-

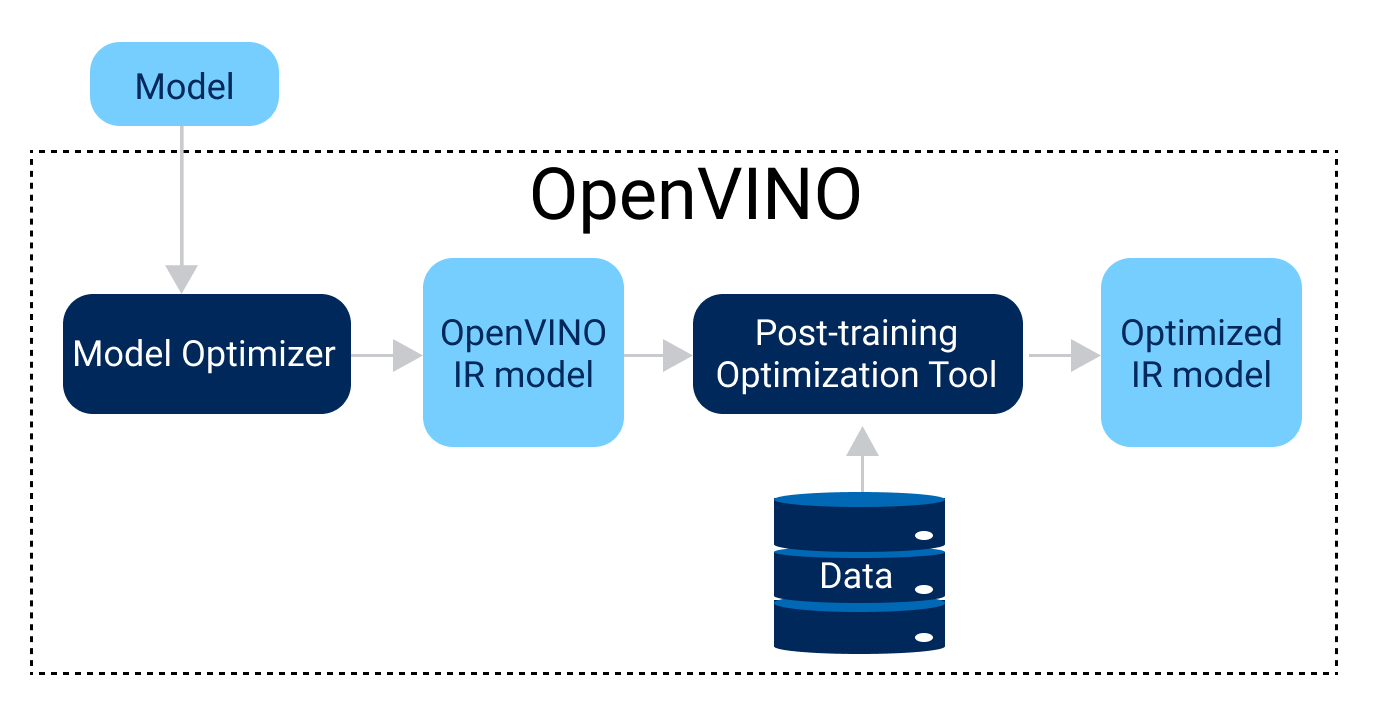
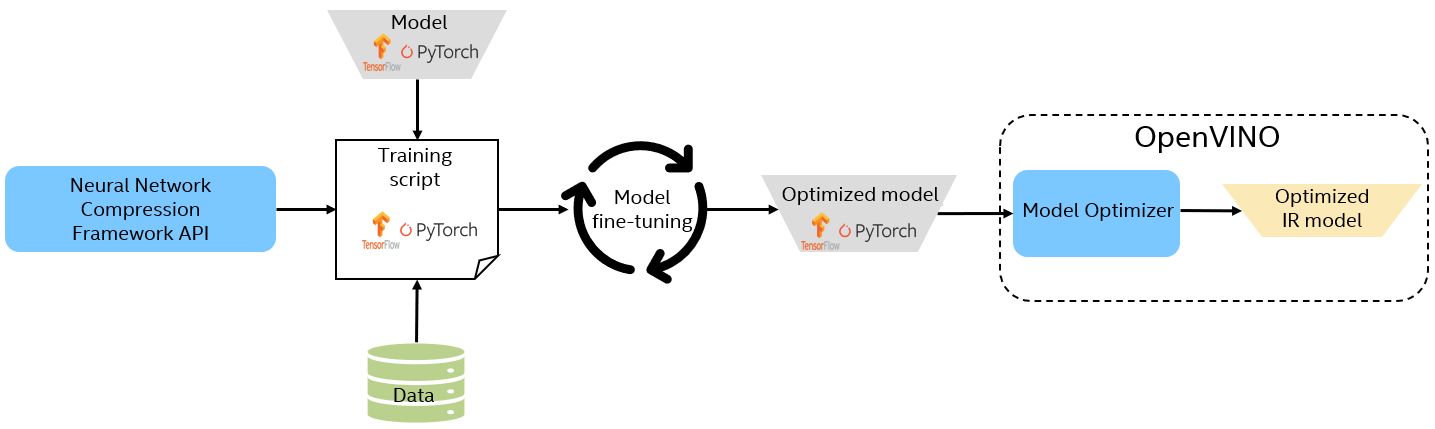
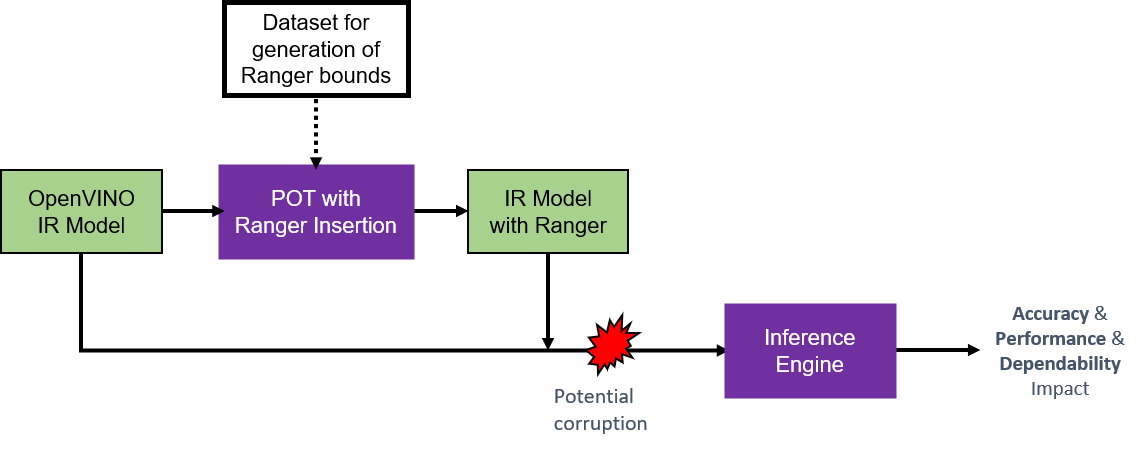
- Runtime Inference Optimizations
- Tuning Utilities
- Performance Benchmarks
基准 Python 应用
基准 C++ 应用
交叉检查工具
深度学习工作台
- Install DL Workbench
- DL Workbench 工作流程

- Get a quick overview of the workflow in the DL Workbench User Interface
{kind=link}
4 部署应用程序
使用推理引擎来部署您的应用程序。
调用推理引擎
使用推理引擎时,可以将其称为具有扩展名的核心对象,然后将优化的 nGraph 网络模型加载到特定的目标设备。加载网络后,推理引擎可接受数据和请求,以运行推理并传递输出数据。
推理引擎开发人员指南
将推理引擎集成到您的应用程序中
部署到运行时环境
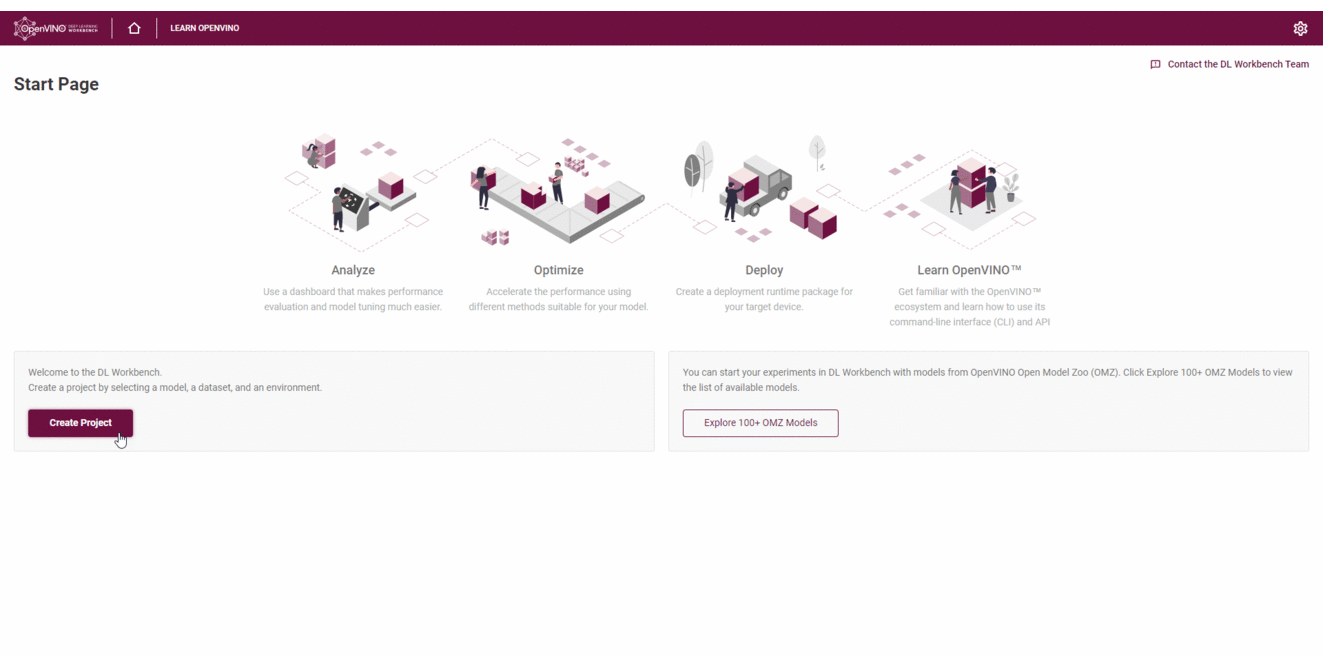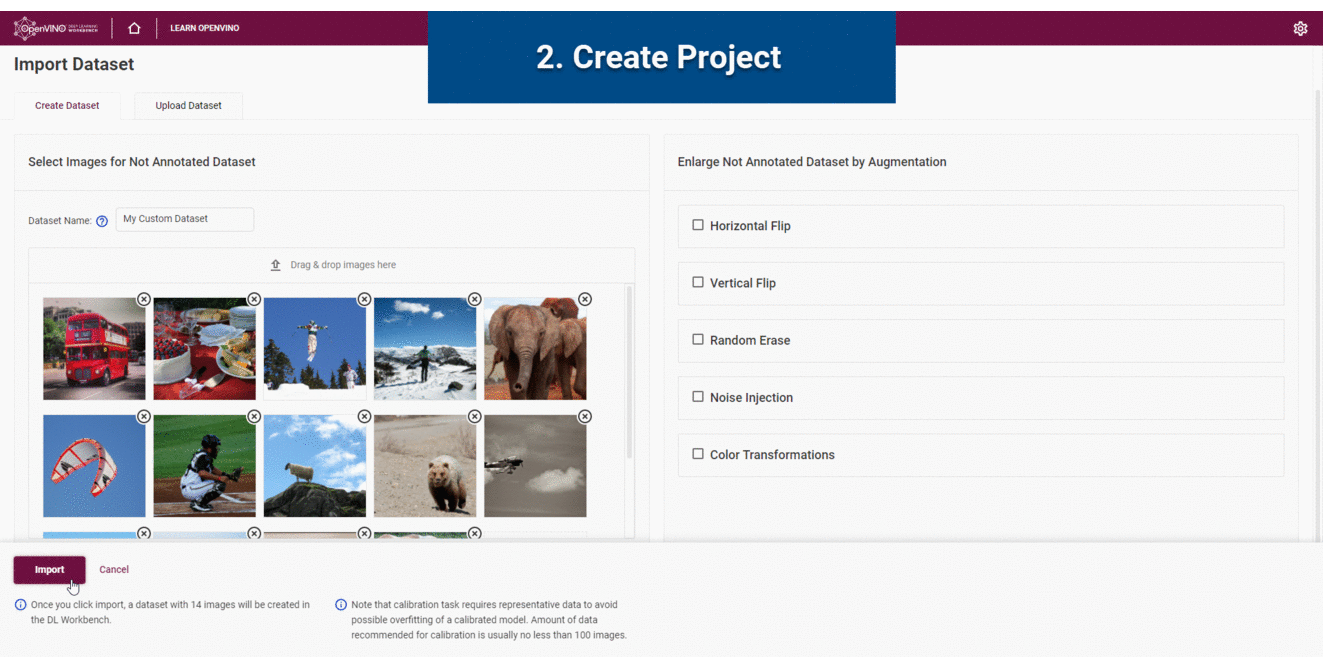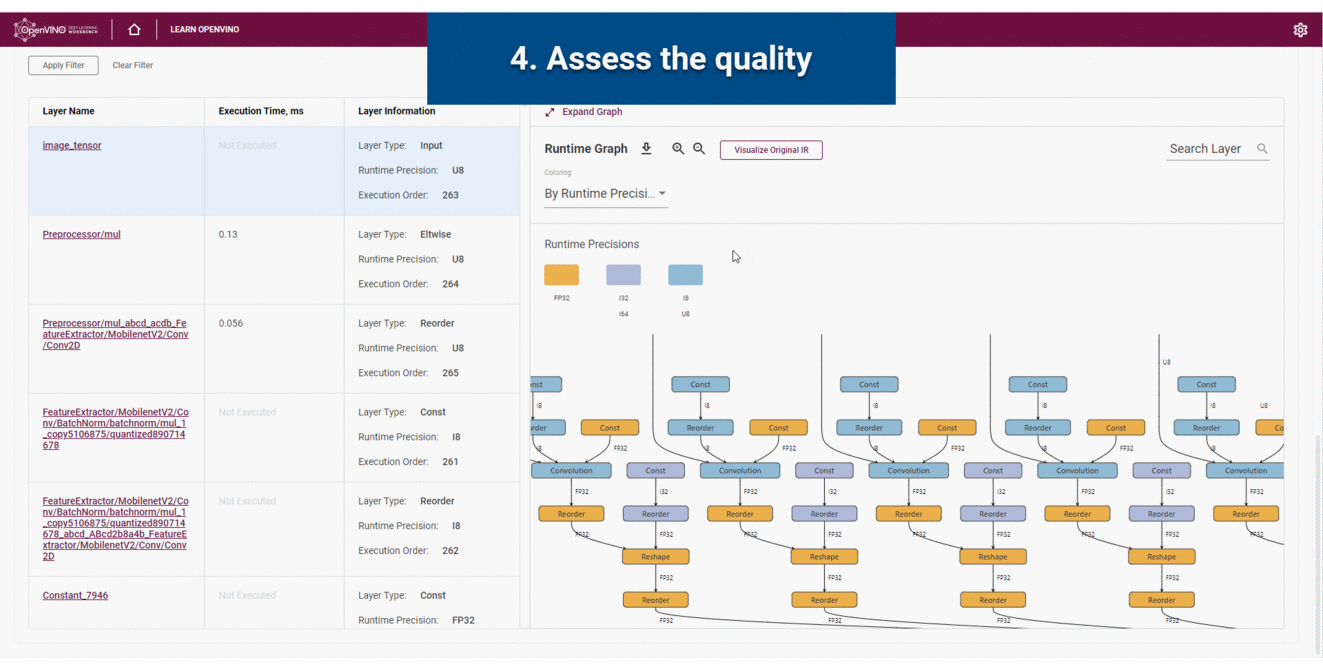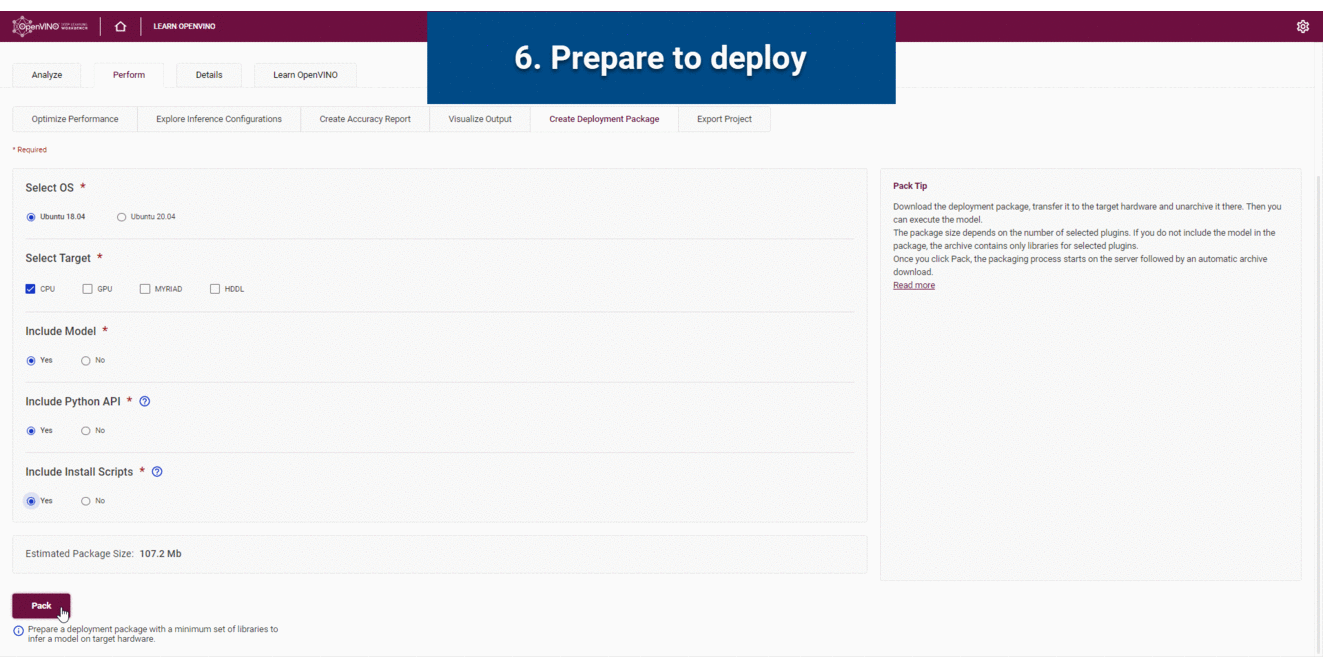
通过将模型、IR 文件、您的应用程序以及相关的依赖项组装到目标设备的运行时程序包中,使用部署管理器来创建部署程序包。
部署管理器
- Prerequisites
- Intel® Distribution of OpenVINO™ toolkit
- To run inference on a target device other than CPU, device drivers must be pre-installed.
- Create Deployment Package Using Deployment Manager
- Deploy Package on Target Systems
工具套件插件
计算机视觉注释工具
这个基于 Web 的工具可在训练模型之前帮助注释视频和图像。
数据集管理框架
使用此插件可以构建、转换和分析数据集。
深度学习流媒体播放器
考虑使用此分析框架,以使用英特尔发行版 OpenVINO 工具套件创建和部署复杂的媒体分析管道。
神经网络压缩框架
使用此基于 PyTorch 的框架进行量化感知训练。
OpenVINO™ 模型服务器
该可扩展推理服务器用于服务通过英特尔® 发行版 OpenVINO™ 工具套件优化的模型。
OpenVINO™ 安全附加组件
支持采用基于内核的虚拟机 (KVM) 和 Docker* 容器进行安全封装和灵活部署。与 OpenVINO 模型服务器兼容。
训练扩展
访问可训练的深度学习模型,使用自定义数据进行训练。