MiniCPM-Llama3-V 2.5 端侧可用的 GPT-4V 级多模态大模型
MiniCPM-Llama3-V 2.5
MiniCPM-Llama3-V 2.5 是 MiniCPM-V 系列的最新版本模型,基于 SigLip-400M 和 Llama3-8B-Instruct 构建,共 8B 参数量,相较于 MiniCPM-V 2.0 性能取得较大幅度提升。MiniCPM-Llama3-V 2.5 值得关注的特点包括:
-
🔥 领先的性能。 MiniCPM-Llama3-V 2.5 在综合了 11 个主流多模态大模型评测基准的 OpenCompass 榜单上平均得分 65.1,以 8B 量级的大小超过了 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等主流商用闭源多模态大模型,大幅超越基于Llama 3构建的其他多模态大模型。
-
💪 优秀的 OCR 能力。 MiniCPM-Llama3-V 2.5 可接受 180 万像素的任意宽高比图像输入,OCRBench 得分达到 725,超越 GPT-4o、GPT-4V、Gemini Pro、Qwen-VL-Max 等商用闭源模型,达到最佳水平。基于近期用户反馈建议,MiniCPM-Llama3-V 2.5 增强了全文 OCR 信息提取、表格图像转 markdown 等高频实用能力,并且进一步加强了指令跟随、复杂推理能力,带来更好的多模态交互体感。
-
🏆 可信行为。 借助最新的 RLAIF-V 对齐技术(RLHF-V [CVPR’24]系列的最新技术),MiniCPM-Llama3-V 2.5 具有更加可信的多模态行为,在 Object HalBench 的幻觉率降低到了 10.3%,显著低于 GPT-4V-1106 (13.6%),达到开源社区最佳水平。
-
🌏 多语言支持。 得益于 Llama 3 强大的多语言能力和 VisCPM 的跨语言泛化技术,MiniCPM-Llama3-V 2.5 在中英双语多模态能力的基础上,仅通过少量翻译的多模态数据的指令微调,高效泛化支持了德语、法语、西班牙语、意大利语、俄语等 30+ 种语言的多模态能力,并表现出了良好的多语言多模态对话性能。查看所有支持语言
-
🚀 高效部署。 MiniCPM-Llama3-V 2.5 较为系统地通过模型量化、CPU、NPU、编译优化等高效加速技术,实现高效的终端设备部署。对于高通芯片的移动手机,我们首次将 NPU 加速框架 QNN 整合进了 llama.cpp。经过系统优化后,MiniCPM-Llama3-V 2.5 实现了多模态大模型端侧语言解码速度 3 倍加速、图像编码 150 倍加速的巨大提升。
总结
能力有限,主要是基于图像的文字识别,简单表格的识别,手写文字识别等。
手写文字识别

提示词:对图像文字进行识别
标题:I think student have many after-school classes is don’t good for them. So I thing the student don’t have many after-school classes.
正文: On school, student have many classes, many home work and compare with classmates. And after st school, they are 7:00 p.m go home and they can do housework and do homework. It is so tired but it they have many st after-school classes, they don’t go home of quickly and they don’t have enough st sleep, so that they don’t go for to school. After-school classes is don’t So student don’t have many after-school classes. Student have after-school classes for a student, but student have many after-school classes, don’t good for student. Student don’t have many after-school classes.
提示词:这张图片上写了什么?
这张图片上写着一篇关于学校课程安排的文章。作者认为学生有很多课不一定是好事,因为他们可能没有足够的时间去做家务、休息或回家。作者还提到,如果学生们在上学后仍然有很多课,他们可能会放弃去学校的想法,导致他们错过了学习和社交的机会。最后,作者认为如果学生有足够的课,可以留在学校,但如果他们太多,学生就不会喜欢上学了。
提示词:图像中的手写英文是什么?
这张图片包含一段关于学生对课后学校类别的看法的手写英文。整体信息是学生对课后学校类别持有负面看法,认为它们没有必要,并且可能会阻碍他们参加其他活动或休息。
👍 提示词:识别图像中的手写英文
我认为学生很多后校班是不好的,给他们。所以我想,学生很多后学校班,学校有很多班,很多作业和联系。和同学一起做作业,7:00下午回家和他们做家务和做作业。是的,如果他们有很多后校班,他们不回家和他们不做家务和做作业。是的,如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班,他们不回家和他们不做家务和做作业。所以如果他们有很多后校班
表格
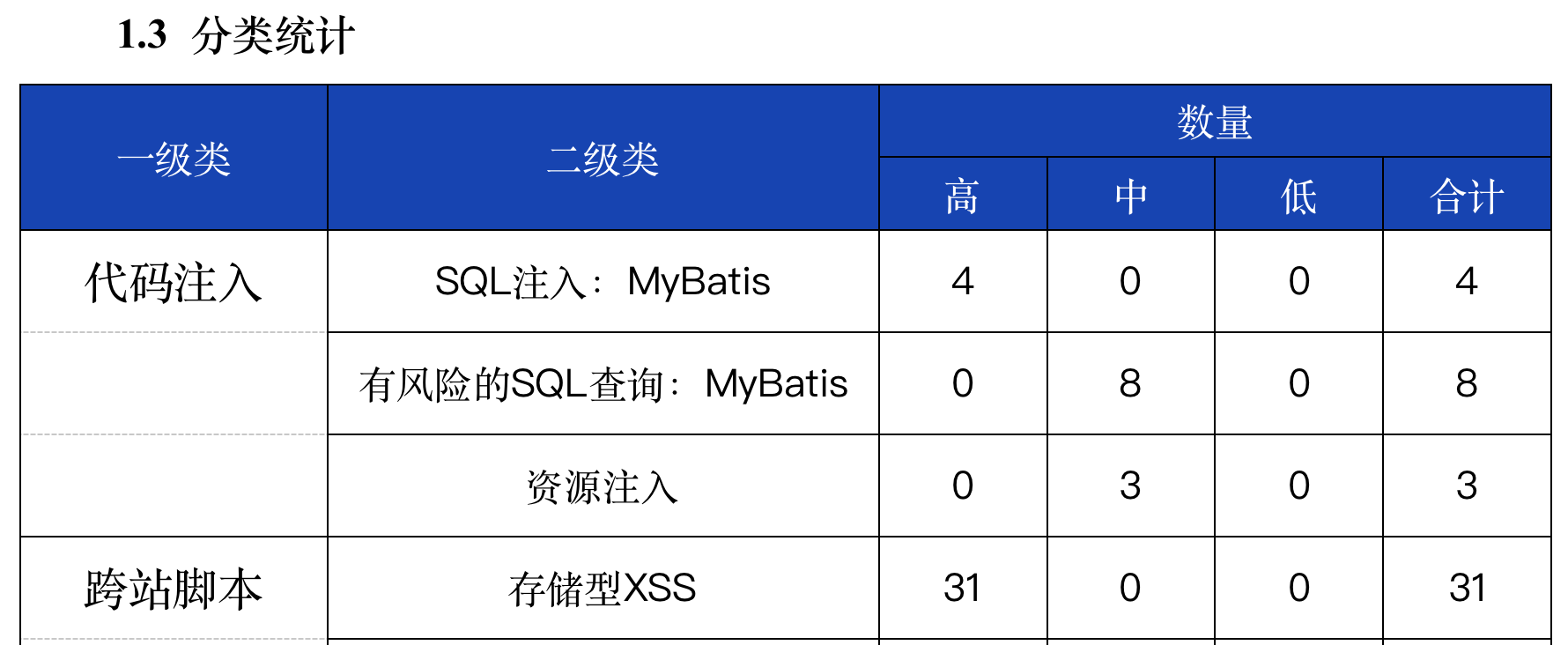
❌ 提示词:将表格的文字识别转换为markdown格式输出
- 表格样式没有识别好,导致内容错位 ❌
另外的表格样式
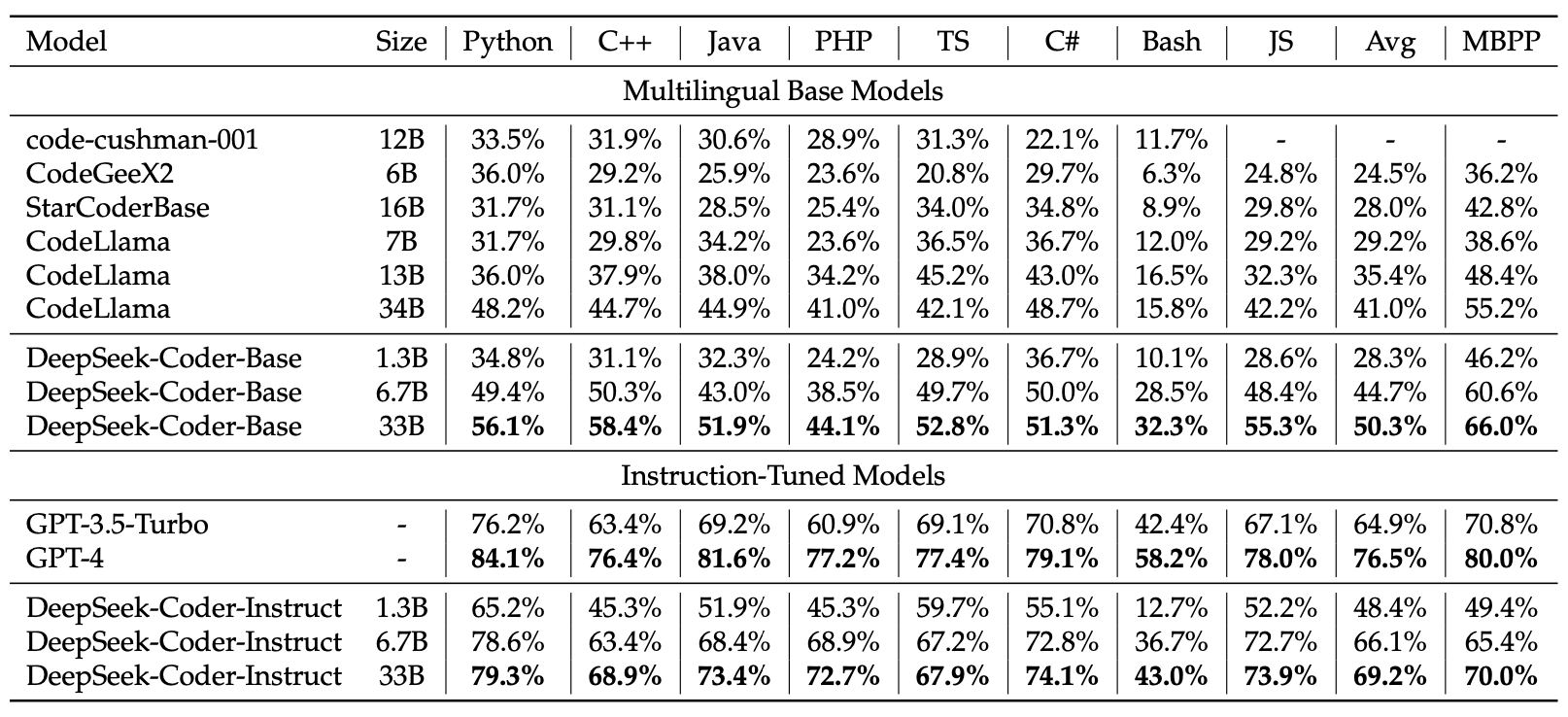
❌ 提示词:将表格的文字识别转换为markdown格式输出
| Model | Size | Python C++ | Java | PHP | TS | C# | Bash | JS | Avg | MBPP |
|---|---|---|---|---|---|---|---|---|---|---|
| code-cushman-001 | 12B | 33.5% | 31.9% | 30.6% | 28.9 | 31.3 | 22.1 | 11.7% | 24.8% | - |
| CodeGeeX2 | 6B | 36.0% | 29.2% | 25.9% | 23.6 | 20.8 | 29.7 | 6.3% | 24.5% | 36.2% |
| StarCodeBase | 16B | 31.7% | 31.1% | 28.5% | 25.4 | 34.0 | 34.8 | 8.9% | 29.8% | 42.8% |
| CodeLlama | 7B | 31.7% | 29.8% | 34.2% | 23.6 | 36.5 | 36.7 | 12.0% | 29.2% | 38.6% |
| CodeLlama | 13B | 36.0% | 37.9% | 38.0% | 34.2 | 45.3 | 43.0 | 16.5% | 32.3% | 48.4% |
| CodeLlama | 34B | 48.2% | 44.7% | 44.9% | 41.0 | 42.1 | 48.7 | 15.8% | 42.2% | 55.0% |
| DeepSeek-Coder-Base | 1.3B | 34.8% | 51.3% | 52.3% | 24.2 | 28.9 | 36.7 | 10.1% | 28.6% | 46.2% |
| DeepSeek-Coder-Base | 6.7B | 49.4% | 50.3% | 43.0% | 38.5 | 49.7 | 50.0 | 28.5% | 48.4% | 60.6% |
| DeepSeek-Coder-Base | 33B | 56.1% | 58.4% | 51.9% | 44.1 | 52.8 | 51.3 | 32.3% | 55.3% | 66.0% |
| GP’3.5-Turbo | 76.2 | 63.4% | 69.2% | 60.9% | 69.1 | 70.8 | 42.4 | 67.1% | 64.9% | 70.8% |
| GP’4 | 84.1 | 76.4% | 81.6% | 77.2% | 77.4 | 79.1 | 58.2 | 78.0% | 76.5% | 80.0% |
| DeepSeek-Coder-Inst | 1.3B | 65.2% | 45.3% | 51.9% | 45.3 | 59.7 | 55.1 | 12.7% | 52.2% | 49.4% |
| DeepSeek-Coder-Inst | 6.7B | 78.6% |
手机充值

❌ 提示词:读取图像中的充值号码,商品总价,订单编号,下单时间,充值金额。
充值金额:15552561555元
商品总价:¥199.80
订单编号:RP140913230130203408654
下单时间:2023-01-30 20:34:08
充值号码:6222****3080
这些信息是根据图片中显示的内容提取的。
火车票

提示词:识别火车票上的信息
火车票上的信息显示了以下内容:车次为K1348,出发地是广州站,目的地是西安站。车票上印有日期和时间,日期是2019年08月27日,时间是10:08开,07车048号,价格是236.0元。还有关于乘车的说明,比如限乘当日当次车,以及一个条形码和一个二维码,用于扫描或验证。
提示词:识别火车票上的信息:车次、始发站、到达站、日期、车厢号、金额、姓名。
火车票上的信息如下:
- 车次:K1348
- 始发站:广州
- 到达站:西安
- 日期:2019年08月27日,10:08开
- 车厢号:07车 048号
- 金额:¥236.0元
- 姓名:张润宇 请注意,姓名部分可能是打印错误或是未填写完整,因为它与车票上其他信息的格式不同。
👍 提示词:读取图像中的车次、始发站、到达站、日期、车厢号、金额、姓名。
车次:K1348
始发站:广州站
到达站:西安站
日期:2019年08月27日
车厢号:07车048号
金额:¥236.0元
姓名:张润宇
👍 提示词:读取图像中的火车票信息,返回姓名、车次、始发站、到达站、日期、车厢号、金额。使用 json 格式输出。
{
"姓名": "张润宇",
"车次": "K1348",
"始发站": "广州站",
"到达站": "西安站",
"日期": "2019年08月27日 10:08",
"车厢号": "07车 048号",
"金额": "¥236.0元"
}
化学

提示词:文字识别
- 识别的内容不够准确 ❌
这张图片包含了化学题目的选择题和答案。题目分为多个部分,每个部分都有不同的题号和选项。以下是整合后的文本内容及其结构:
标题: 单项选择题
副标题: 1-5 DAB 6-10 BBCAD
正文:
多项选择题
11.CD 12.ABC 13.BD 14.ACD 15.BC
三、非选择题
16.(1)①Hz②SO3③Cu(OH)2④ZnCl2
17.(1)①B②Cl2+HzO=HCl+HCO3③CaCO3+2HzO=2H2O+O2④带火星⑤偏大
18.(1)①干燥二氧化碳②CaCO3+2Hz=H2O+CO2+CaCl2
19.(1)①Fe②D
20.(1)①Na2CO3②饱和氯水呈碱性,更易吸收二氧化碳③不饱正溶液质量:25.9g+200g+208g-23.3g=410.6g
答案:
11.CD 12.ABC 13.BD 14.ACD 15.BC
三、非选择题
16.(1)①Hz②SO3③Cu(OH)2④ZnCl2
17.(1)①B②Cl2+HzO=HCl+HCO3③CaCO3+2Hz=H2O+CO2+CaCl2
18.(1)①BCD②2H2O=2H2O+O2③带火星④偏大
19.(1)①NH3②K2CO3③K+Na④K2SO4+Ba(Na2O3)=BaSO4↓+2KNO3
20.(1)①Na2CO3②饱和氯水呈碱性,更易吸收二氧化碳③不饱正溶液质量:25.9g+200g+208g-23.3g=410.6g
这张图片主要用于教育或考试目的,展示了化学题目的解析和答案。
数学

提示词:答题
- 解题了,但没有选择答案(ABCD)。
答案如下:
👍 (4分) 6的算术平方根是√6 ❌ (4分) 已知水星的半径约为24400000米,用科学记数法表示为2.44×10^6米。
英语

❌ 提示词:下面空白处应该填写什么单词
空白处应该填写 'happy' 这个单词。
提示词:对图像的文字进行识别
标题: 阅读下面短文,在空白处填入1个适当的单词或括号内单词的正确形式。(共10小题; 每小题1.5分, 满分15分)
副标题: Last Sunday, I had a perfect day My aunt came to my home ___ 6 ___ her six-year-old daughter Alice in the morning. While my aunt was talking with my mom at home, my cousin felt a bit ___ 67 ___ (boring). So I took Alice to the park near my home. There we bought two kites and started flying ___ 68 ___ (they). While we were doing that, Alice jumped up and down and I knew she was truly having great fun. Later, we ___ 69 ___ (sit) down on a bench and looked at the gardens. As we were sitting there, Alice looked up at me ___ 70 ___ (great day today!) "I smiled at her and agreed. We did something quite common, yet we were very happy.
正文:
Many people wait for their "best days". But I think today is our perfect day. As adults, we often make plans ___ 71 ___ (careful) in order to have a great day. Some people think that making a lot of money ___ 72 ___ (make) them have a nice day. I think we should be more like ___ 73 ___ (child). They don't think about money ___ 74 ___ (what will happen tomorrow. They really live in the moment and enjoy the moment!
We often hear the expression that we should live in the present. Yesterday is a history. Tomorrow is a mystery. Today is a gift. That's why it ___ 75 ___ (call) present. So seize the day
标题: VI. 阅读下面短文,在空白处填入1个适当的单词或括号内单词的正确形式。(共10小题; 每小题1.5分, 满分15分)
正文:
Last Sunday, I had a perfect day My aunt came to my home 6_ her six-year-old daughter Alice in the morning. While my aunt was talking with my mom at home, my cousin felt a bit 67_ (boring). So I took Alice to the park near my home. There we bought two kites and started flying 68_ (they). While we were doing that, Alice jumped up and down and I knew she was truly having great fun. Later, we 69_ (sit) down on a bench and looked at the gardens. As we were sitting there, Alice looked up at me and said, "What 70_ great day today!" I smiled at her and agreed. We did something quite common, yet we were very happy.
Many people wait for their "best days." But I think today is our perfect day. As adults, we often make plans 71_ (careful) in order to have a great day. Some people think that making a lot of money 72_ (make) them have a nice day. I think we should be more like 73_ (child). They don't think about money 74_ what will happen tomorrow. They really live in the moment and enjoy the moment!
We often hear the expression that we should live in the present. Yesterday is a history. Tomorrow is a mystery. Today is a gift. That's why it 75_ (call) present. So seize the day
图像生成代码
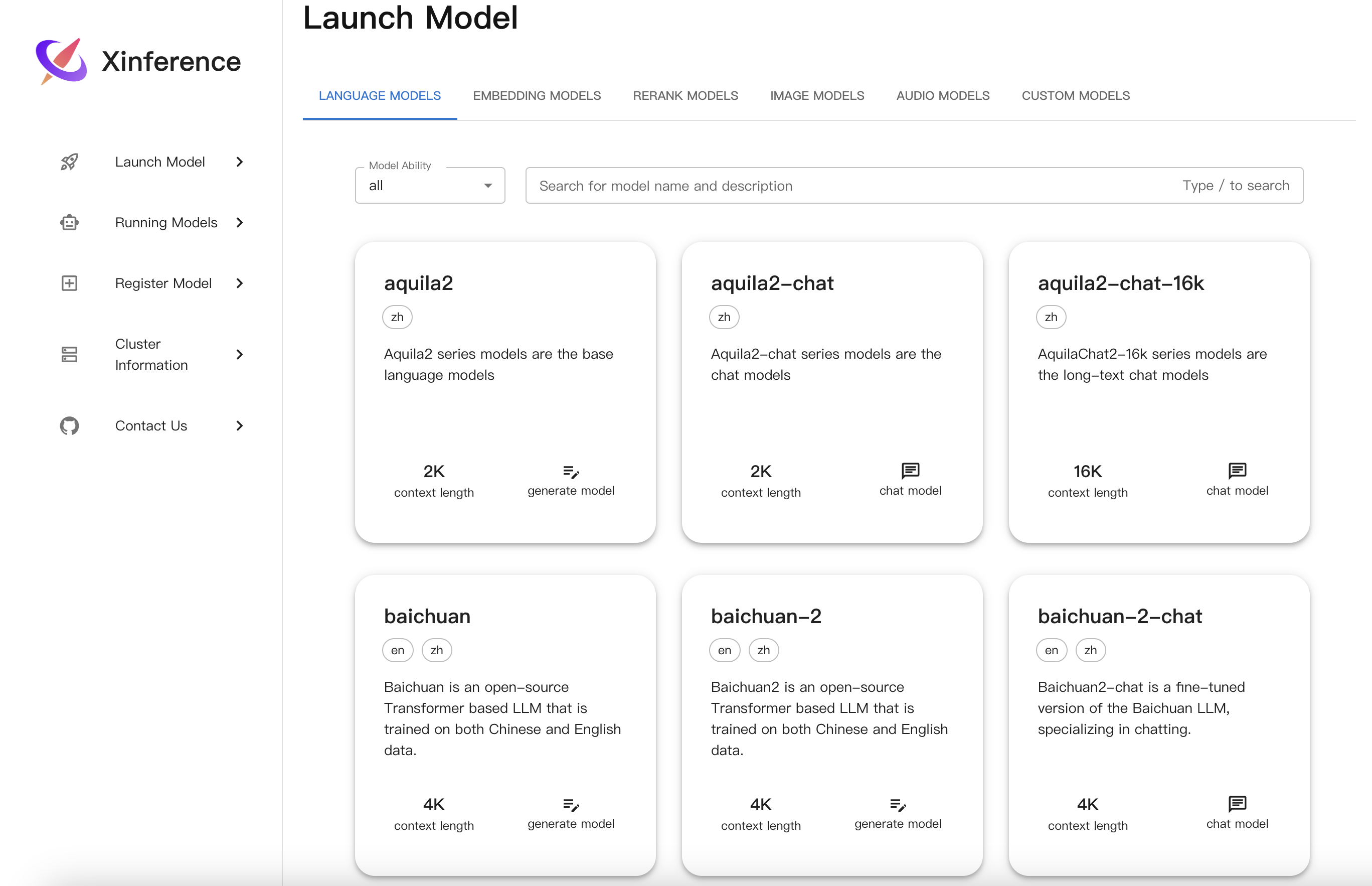
提示词:将图像转换成HTML代码
以下是从图像中提取的结构化元数据的HTML代码:
<html>
<head>
<title>Launch Model</title>
</head>
<body>
<div class="header">
<h1>Launch Model</h1>
</div>
<div class="menu">
<ul>
<li>Launch Model</li>
<li>Running Models</li>
<li>Register Model</li>
<li>Cluster Information</li>
<li>Contact Us</li>
</ul>
</div>
<div class="search-bar">
<input type="text" placeholder="Search for model name and description" />
</div>
<div class="content">
<div class="model-list">
<h2>Model List</h2>
<div class="filter">
<select>
<option>Model Ability</option>
<option>zh</option>
<option>en</option>
<option>zh</option>
</select>
</div>
<div class="models">
<div class="model-card">
<h3>aquila2</h3>
<p>Aquila2 series models are the base language models</p>
<button>2K</button>
<button>context length</button>
</div>
<div class="model-card">
<h3>aquila2-chat</h3>
<p>Aquila2 series chat models are the long-text chat models</p>
<button>16K</button>
<button>context length</button>
</div>
<div class="model-card">
<h3>baichuan-2</h3>
<p>Baichuan is an open-source Transformer based LLM that is trained on both Chinese and English data.</p>
<button>4K</button>
<button>context length</button>
</div>
</div>
</div>
</div>
</body>
</html>
此代码包括一个基本的HTML布局,包含一个标题、菜单栏、搜索栏和模型列表。它还包括按钮和选项,以表示每个模型的大小和上下文长度。

数数

❌ 提示词:图像中有多少开关?
为了确定图像中开关的数量,我们需要数一数每一个单独的开关。由于我无法直接操作图像或对其进行分析,我将依赖于描述来估计数量。如果图像是一个连续的排列没有明显的间隙,那么我们可以简单地数一数每个开关。如果有空缺或重复,可能会影响总数。在实际情况下,可以通过查看图像并逐行或逐列计算开关来获得准确的数量。
选择题



上面的选择题探索后,发现不能识别。
提示词:根据图像中涂的 ABCD,来判断用户的回答。
图像中显示的 ABCD 字母序列没有提供任何上下文或参考物来推断用户的回答。这些字母是单独呈现的,没有与任何已知单词或短语关联,这些关联可能会让人推测出一个答案。要准确回答,需要知道问题或用户意图所指的背景。因此,基于这幅图像,无法给出一个明确的答案。
提示词:根据图像中填涂的 ABCD,来判断用户的选择,图像中有5题,答案:
根据填涂的 ABCD,可以判断用户的选择。图像中有5题,答案是:A B A B D。
提示词:根据图像中的填涂,来判断用户的选择(A,B,C,D),图像中有5道题,答案分别是多少?
要确定用户在图像中选择的答案,我们需要查看每个选项框是否被填涂。根据提供的信息,无法确切地回答,因为没有具体说明哪些选项被填涂或未填涂。然而,如果我们假设黑色表示已填涂的选项,那么第1题的答案是A,第2题的答案是B,第3题的答案是D,第4题的答案是C,第5题的答案是A。如果您提供了哪些选项被填涂的详细信息,我可以给出更准确的答案。
提示词:图像中用户填涂的选项是?
用户填涂的选项是'AC'。
试卷分数
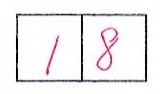
👍 提示词:请输出图像中的分数
18
提示词:图像中红色数字是老师打的分数,请输出分数
在给定的图片中,老师打的分数是18。这个数字用红色标记,并且是图片中唯一的文字内容,因此输出分数为18。
图像描述

提示词:图像中描述的是什么?
这幅图像描述了一只小狗和一只小猫。狗看起来是幼犬,毛色浅褐,眼睛黑色,表情专注。它的耳朵竖立着,目光直视前方。小猫似乎正在喵叫,有点张开嘴,暗示着活泼或兴奋。它的毛色为灰色和白色混合,耳朵尖尖。两只动物都在白色背景上,这可能表明这是一个受控环境,比如摄影棚。它们之间的互动似乎是友好而有趣的。
提示词:图像中有几只猫
图像中有一只猫。
提示词:图像中有几只动物
图像中有两只动物:一只狗和一只猫。
👍 提示词:图像包含的每个动物的坐标 [[x0,y0,x1,y1]] ?
狗的坐标是 [[0,9,572,952]],猫的坐标是 [[520,215,950,937]]。
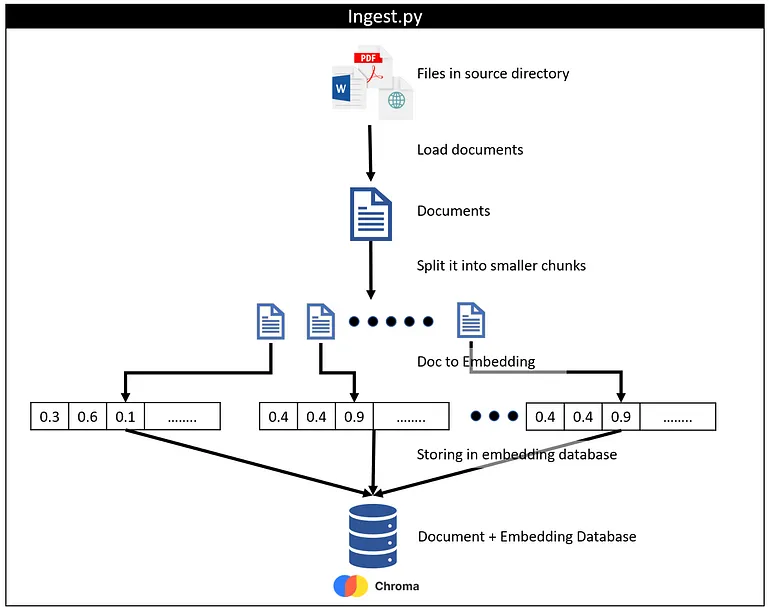
提示词:图像中描述的是什么?
该图像是一张流程图,展示了Python代码中的数据处理和嵌入过程。它显示了一个开始点,标记为’Ingest.py’,从那里,文件被导入源目录。然后将这些文件加载到内存中,并拆分成较小的块。这些块进一步转换为文档嵌入,表示为一系列数值,可能是通过向量空间模型或类似的技术生成的。最后,这些嵌入存储在嵌入数据库中,具体来说是在称为’Chroma’的数据库中。这表明该图像描述了数据预处理和特征提取阶段,在自然语言处理任务中使用Python进行编码。
提示词:解释一下图像中的工作流程
图像显示了一个工作流程,涉及将数据从源目录加载到文档嵌入数据库中。该过程由一个带有红色标志的文件图标开始,表示输入文档。这些文档似乎被分成较小的块进行处理,这可能是为了提高效率或减少内存使用量。
在此阶段之后,文档被传输到另一个阶段,标记为“文档到嵌入”。这表明文档正在被分析或转换,以便用于文档嵌入,这是一种通过计算机程序生成的向量来捕捉文档内容的方法。
最终,文档被存储在嵌入式数据库中,如图中所示的柱状图和数据库图标所示。这暗示了一个数据存储系统,其中文档的内容以可比较且可用于机器学习或其他分析目的的形式被保存。
整体流程似乎是一个自动化的数据预处理步骤,旨在准备文档用于进一步的自然语言处理或信息检索任务。