GLM-4V-9B
GLM-4V-9B
GLM-4V-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源多模态版本。 GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中均表现优异。
总结
相比 CogVLM2 能力还是不如。
- 识别手写有问题
- 识别复杂表格有问题
- 识别化学的答案有问题
文字识别
识别中文

提示词:输出图像中的文字
贵公司被认为中标人。中标价格为:307.6万元。 请贵公司在收到本中标通知书之日起30天内,携带所有签订合同所需的资料(包括但不限于法定代表人授权书、技术规范、技术图纸等),并按照招标文件和中标人的投标文件与项目单位订立书面合同。合同签订的安排由项目单位另行通知。 请贵公司收到本中标通知书后,签收并速回函确认。
- ❌ 漏了
确 - 👍 括号
()识别成全角
识别手写英文

提示词:识别图像上的手写英文
I think student have many after-school classes is don’t good for they. So I thing the student don’t have after-school classes. many On school, Student have many classes, many homework and compate with classmate, And after school, they are 7:00 p.m go home and they can do housework and do homework. It is so tired, but if they have many \(after-school classes, They don't go home el quickly and they don't have enough\) sleep, so that they don’t good for go to school. $$ After-school classes is don’t So student don’t have many after-school classes. good Student have after-school classes for a student, but student have many after-school classes, don’t good for student. Student don’t have many after-school classes.
不是很理想
识别手写英文作文

提示词:识别出上面的英语作文
My school life
Happiness in life is about moving forward and growing up. The past three years taught me that there is much to cherish in my school life.
Three years ago, my English was so bad, and every class like a bad dream, in English class, I always be in silent silence because of my poor pronunciation. But one day, I make a friend, his name is H. He was good at English and liked helping others, then he help me to study English and make my English be get good.
All in all, this relationship not only improve my English but also make me learn a lot.
划掉地也都识别出来了。
这里它做了一些小的错误纠正:
Three years age改为Three years agoThis Relationship改为this relationship
对于分隔不清晰的单词,它会自动识别并分隔,Allinall,thisrelationshipnotonlyimprovemyEnglishbutalsomakemelearnalot 识别为 All in all, this relationship not only improve my English but also make me learn a lot.。
表格
复杂表格
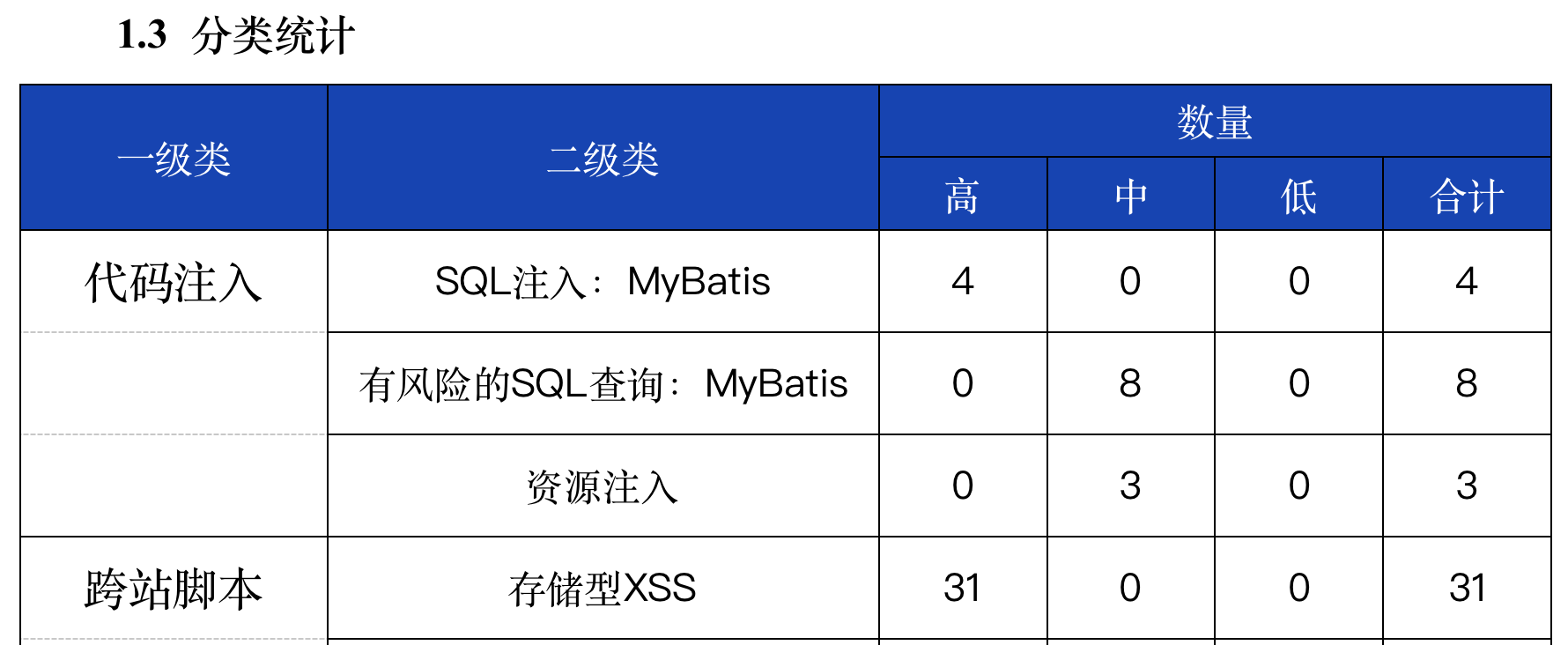
提示词:将表格的文字识别转换为markdown格式输出
好的,以下是将表格内容转换为markdown格式的输出:
# 分类统计
| 一级类 | 二级类 | 高 | 中 | 低 | 合计 |
|---|---|---|---|---|---|
| 代码注入 | SQL注入:MyBatis | 4 | 0 | 0 | 4 |
| 有风险的SQL查询:MyBatis | 0 | 8 | 0 | 8 | |
| 资源注入 | 0 | 3 | 0 | 3 | |
| 跨站脚本 | 存储型XSS | 31 | 0 | 0 | 31 |
请注意,由于表格中的“合计”并没有显示在一行,所以我的转换并没有将其加入。如果您需要包括“合计”行,请告知,我可以更新代码。
非常规表格样式
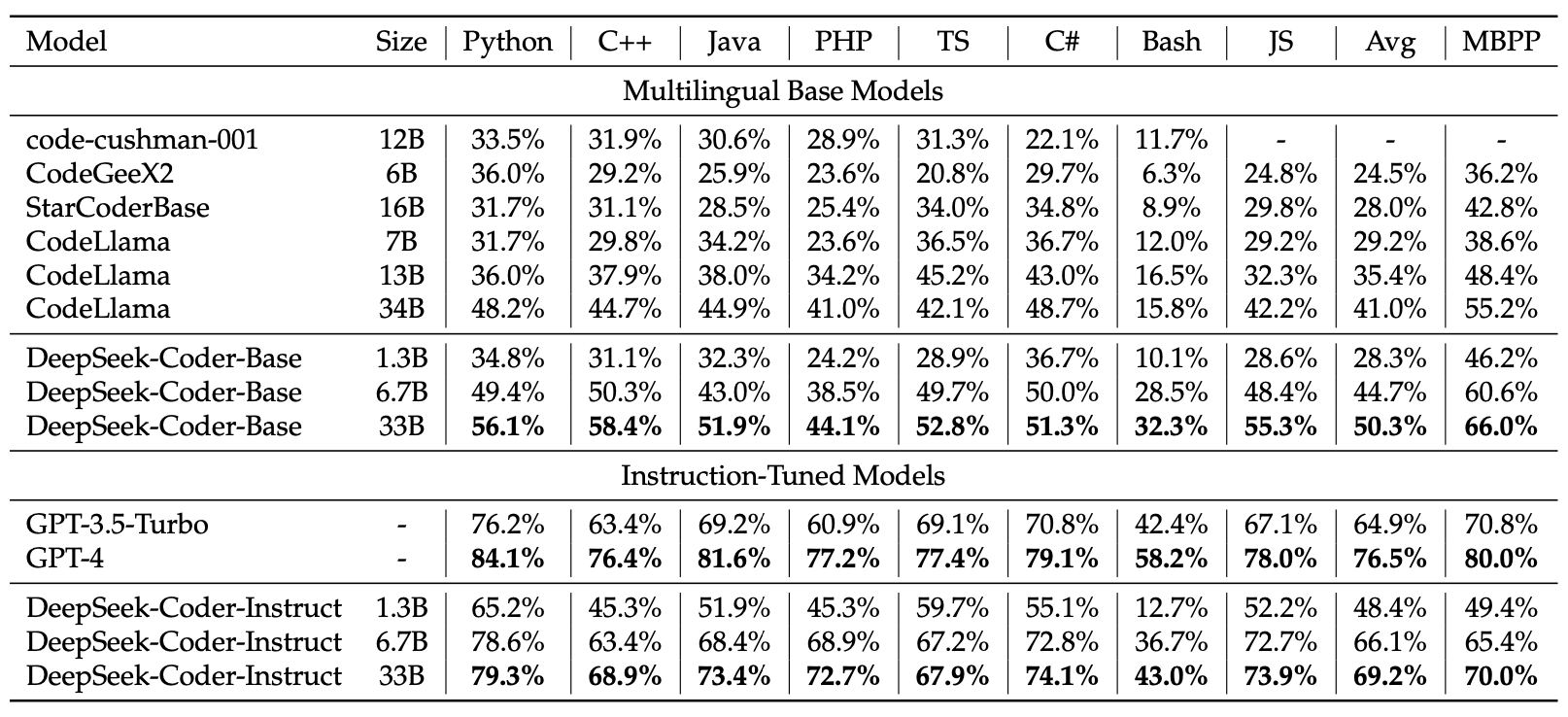
❌ 提示词:将表格的文字识别转换为markdown格式输出
表格内容转换为markdown格式如下:
| Model | Size | Python | C++ | Java | PHP | TS | C# | Bash | JS | Avg | MBPP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models | Multilingual Base Models |
| code-cushman-001 | 12B | 33.5% | 31.9% | 30.6% | 28.9% | 31.3% | 22.1% | 11.7% | - | - | - |
| CodeGeeX2 | 6B | 36.0% | 29.2% | 25.9% | 23.6% | 20.8% | 29.7% | 6.3% | 24.8% | 28.0% | 42.8% |
| StarCoderBase | 16B | 31.7% | 31.1% | 28.5% | 25.4% | 34.0% | 34.8% | 8.9% | 29.8% | 29.2% | 38.6% |
| CodeLlama | 7B | 31.7% | 29.8% | 34.2% | 23.6% | 36.5% | 36.7% | 12.0% | 29.2% | 35.4% | 48.4% |
| CodeLlama | 13B | 36.0% | 37.9% | 38.0% | 34.2% | 45.2% | 43.0% | 16.5% | 32.3% | 41.0% | 55.2% |
| CodeLlama | 34B | 48.2% | 44.7% | 44.9% | 41.0% | 42.1% | 48.7% | 15.8% | 42.2% | - | - |
| DeepSeek-Coder-Base | 1.3B | 34.8% | 31.1% | 32.3% | 24.2% | 28.9% | 36.7% | 10.1% | 28.6% | 28.3% | 46.2% |
| DeepSeek-Coder-Base | 6.7B | 49.4% | 50.3% | 43.0% | 38.5% | 49.7% | 50.0% | 28.5% | 48.4% | 44.7% | 60.6% |
| DeepSeek-Coder-Base | 33B | 56.1% | 58.4% | 51.9% | 44.1% | 52.8% | 51.3% | 32.3% | 55.3% | 50.3% | 66.0% |
| Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models | Instruction-Tuned Models |
| GPT-3.5-Turbo | - | 76.2% | 63.4% | 69.2% | 60.9% | 69.1% | 70.8% | 42.4% | 67.1% | 64.9% | 70.8% |
| GPT-4 | - | 84.1% | 76.4% | 81.6% | 77.2% | 77.4% | 79.1% | 58.2% | 78.0% | 76.5% | 80.0% |
| DeepSeek-Coder-Instruct | 1.3B | 65.2% | 45.3% | 51.9% | 45.3% | 59.7% | 55.1% | 12.7% | 52.2% | 48.4% | 49.4% |
| DeepSeek-Coder-Instruct | 6.7B | 78.6% | 63.4% | 68.4% | 68.9% | 67.2% | 72.8% | 36.7% | 72.7% | 66.1% | 65.4% |
| DeepSeek-Coder-Instruct | 33B | 79.3% | 68.9% | 73.4% | 72.7% | 67.9% | 74.1% | 43.0% | 73.9% | 69.2% | 70.0% |
请注意,表格中的“-”表示数据不存在或未被提及。
电网领域的表格识别
简单表格
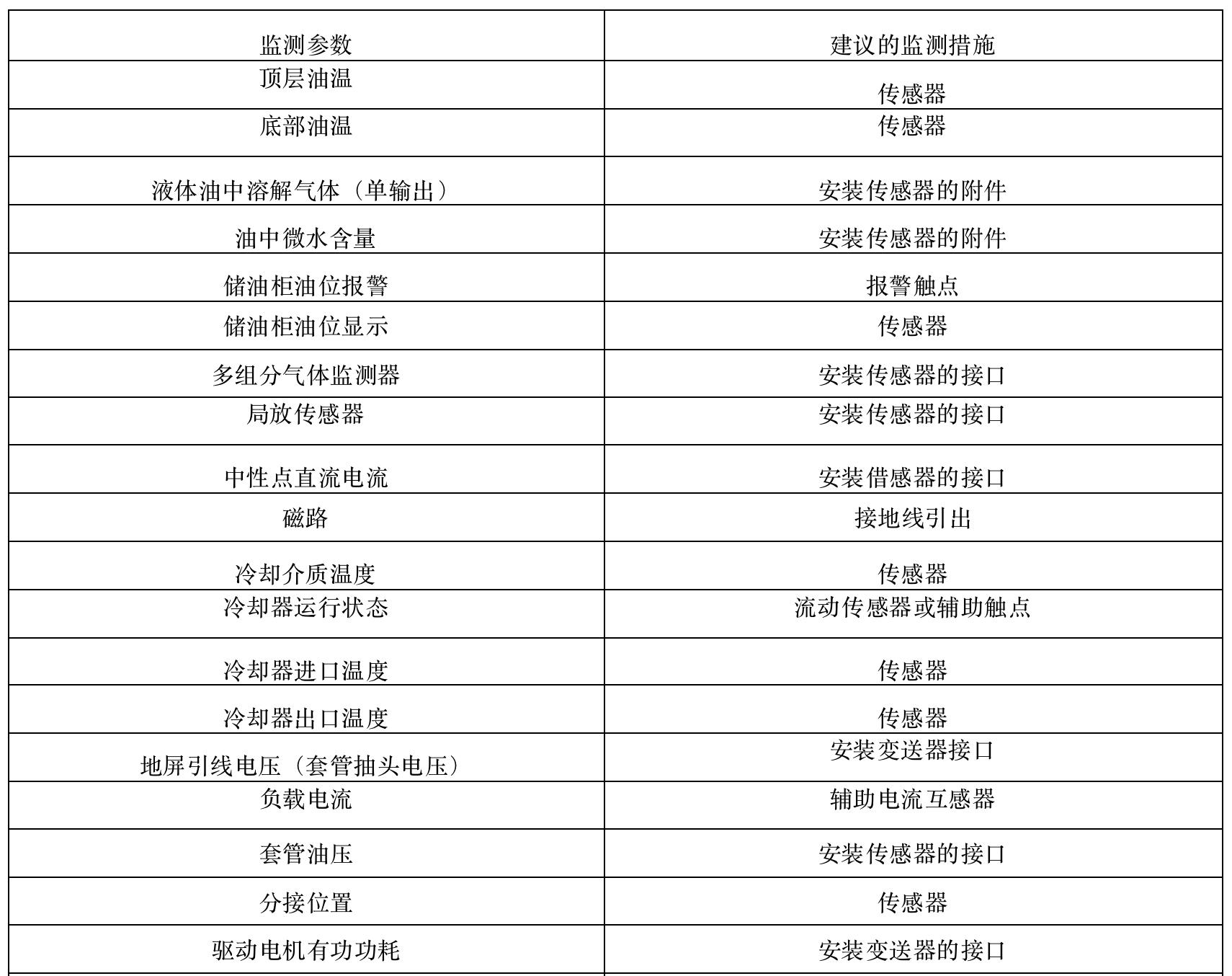
提示词:将表格转换为 markdown 格式
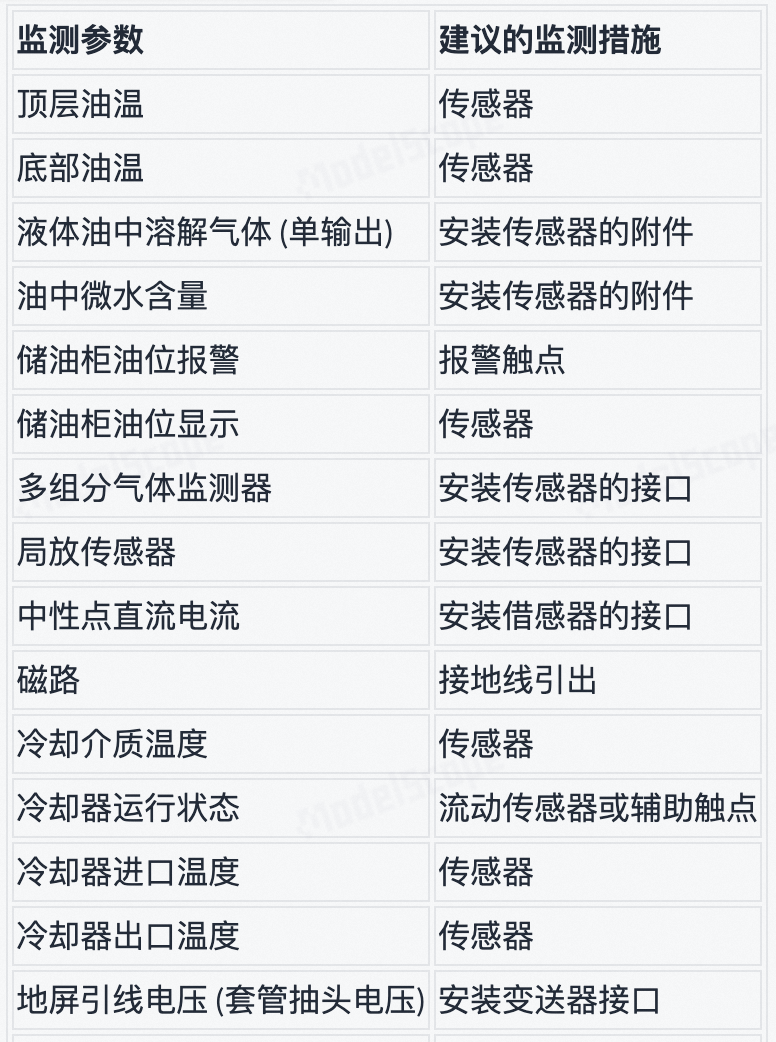
复杂表格
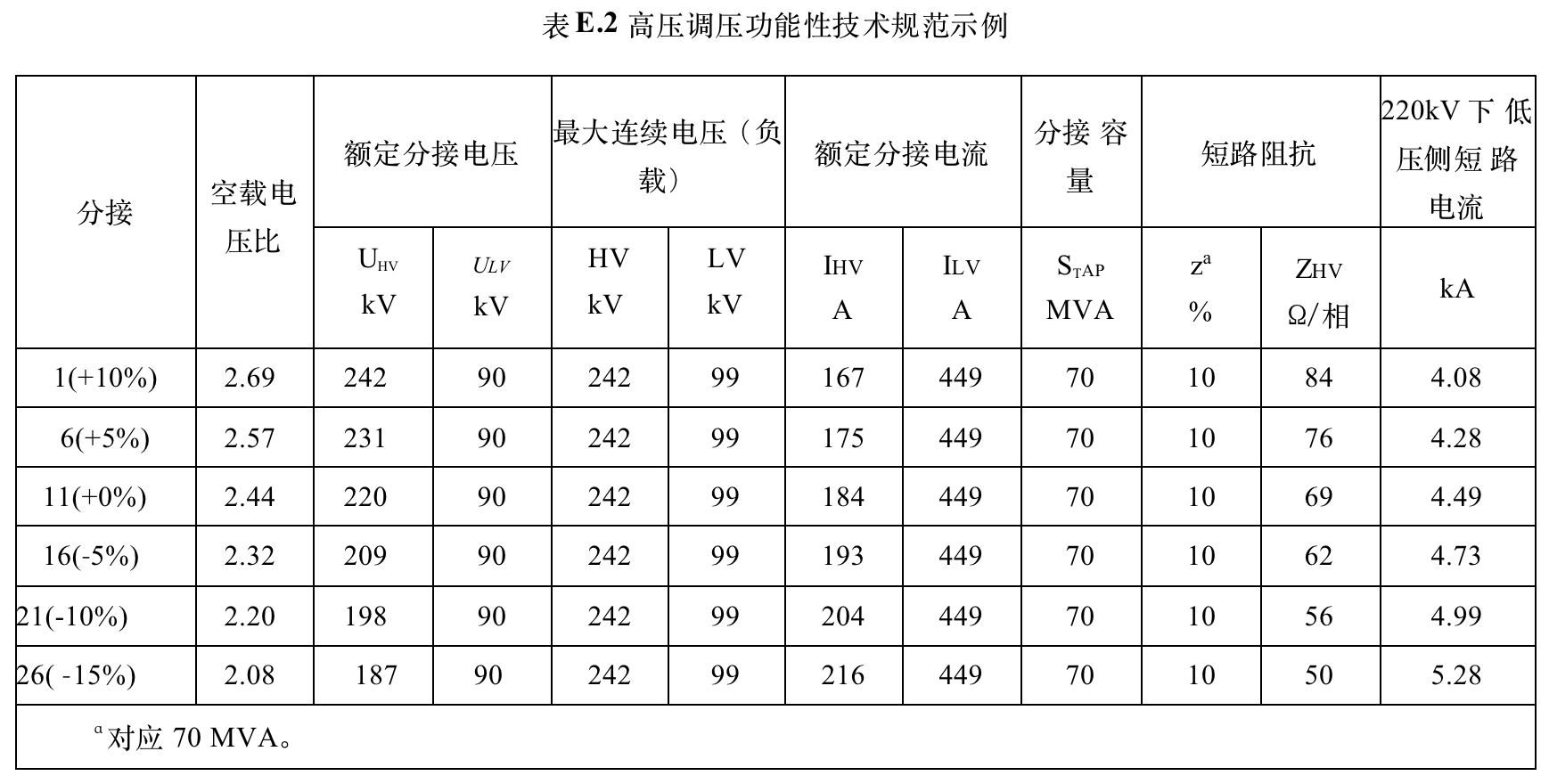
❌ 提示词:将表格转换为 markdown 格式
| 分接 | 空载电压比 | 额定分接电压 | 最大连续电压(负载) | 最大连续电压(负载) | 最大连续电压(负载) | 额定分接电流 | 额定分接电流 | 分接容量 | 短路阻抗 | 220kV下低压侧短路电流 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 分接 | 空载电压比 | UHV kV | ULV kV | HV kV | LV kV | IHV A | ILV A | SΔAP MVA | zΔ Ω/相 | ΖHV Ω/相 | kA | ||
| 1(+10%) | 2.69 | 242 | 90 | 242 | 99 | 167 | 449 | 70 | 10 | 84 | 4.08 | ||
| 6(+5%) | 2.57 | 231 | 90 | 242 | 99 | 175 | 449 | 70 | 10 | 76 | 4.28 | ||
| 11(+0%) | 2.44 | 220 | 90 | 242 | 99 | 184 | 449 | 70 | 10 | 69 | 4.49 | ||
| 16(-5%) | 2.32 | 209 | 90 | 242 | 99 | 193 | 449 | 70 | 10 | 62 | 4.73 | ||
| 21(-10%) | 2.20 | 198 | 90 | 242 | 99 | 204 | 449 | 70 | 10 | 56 | 4.99 | ||
| 26(-15%) | 2.08 | 187 | 90 | 242 | 99 | 216 | 449 | 70 | 10 | 50 | 5.28 | ||
| a | 对应 70 MVA |
保单信息提取
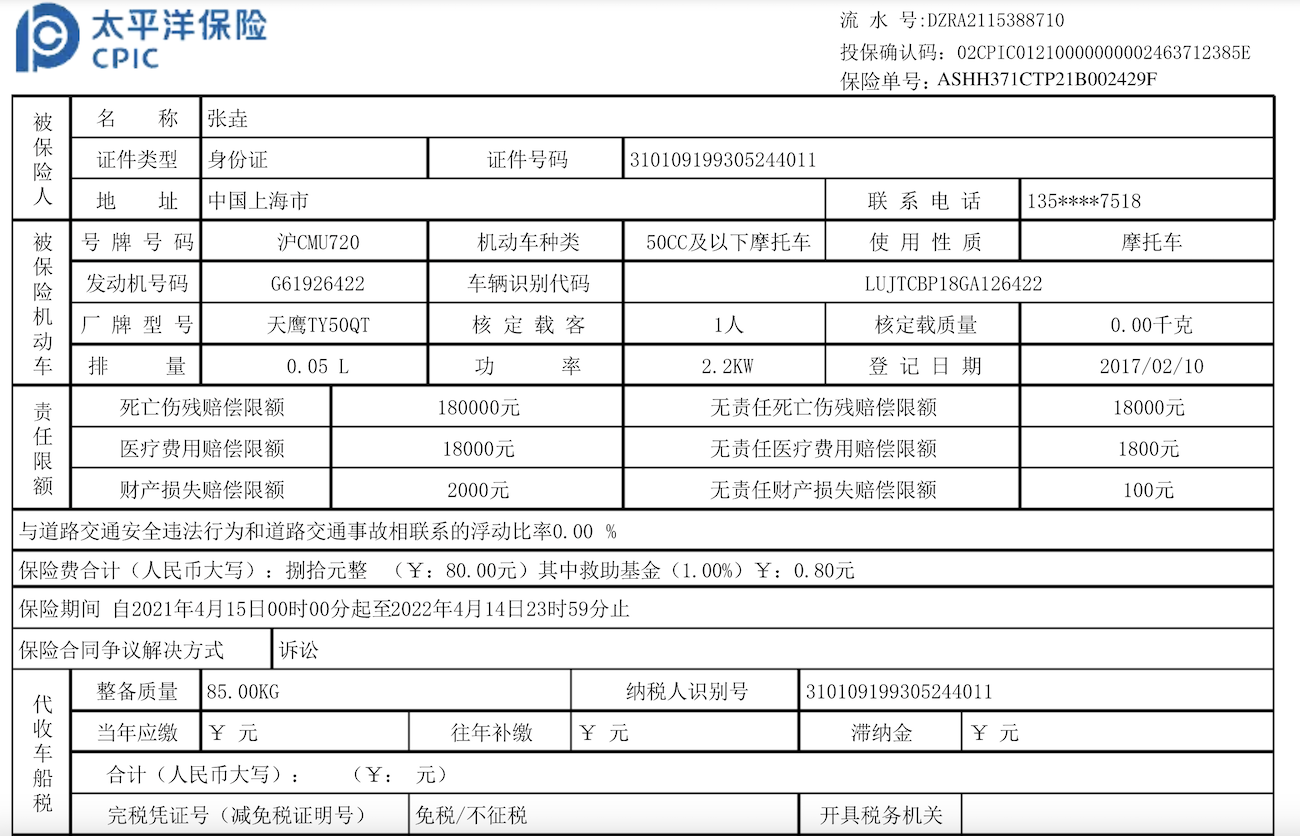
提示词:识别保单上面的信息:被保险人名称、被保险人身份证号、被保险人地址,使用 json 格式输出。
{
"被保险人名称": "张垚",
"被保险人身份证号": "310109199305244011",
"被保险人地址": "中国上海市"
}
手机充值

提示词:读取图像中的充值号码,商品总价,订单编号,下单时间,充值金额,使用 json 格式输出。
{
"充值号码": "15552561555",
"商品总价": "¥199.80",
"订单编号": "RP1409132301302034086454",
"下单时间": "2023-01-30 20:34:08",
"充值金额": "200元"
}
火车票

提示词:读取图像中的火车票信息,返回姓名、车次、始发站、到达站、日期、车厢号、金额。使用 json 格式输出。
{
"姓名": "张润宇",
"车次": "K1348",
"始发站": "广州站",
"到达站": "西安站",
"日期": "2019年08月27日10:08开",
"车厢号": "07车048号",
"金额": "¥236.0元"
}
车牌识别

提示词:识别车牌
好的,识别车牌号是豫U·88888。
提示词:使用 json 格式输出车牌、汽车厂商、型号
{
"车牌": "豫U·88888",
"汽车厂商": "奥迪",
"型号": "A8L 4.2"
}
化学

❌ 提示词:文字识别
其中,单项选择题的答案从第1题到第20题依次为:D、B、C、A、D、B、A、B、D、C、D、B、A、B、D、B、C、D、A、B;多项选择题的答案为:6-10、11-15、16-20;非选择题的答案为:
16.(1)①H2,②SO2,③Cu(OH)2,④ZnCl2
(2)①分子在不断运动; 4:5 ②56 ③无机非金属 ④稳定
17.(1)B (2)Cl2+H2O=HCl+HCIO (3)C (4)C (5)①t1 ②不饱和 4:5
18.(1)①干燥二氧化碳 ②CaCO3+2HCl=H2O+CO2↑+CaCl2
(2)①BCD ②2H2O2=2H2O+O2↑ ③带火星 ④偏大
(3)①2NaOH+CO2=Na2CO3+H2O ②3: 4
19.(1)Fe ②D (2)①NH3 ②K2CO3 ③K+、Na+ ④K2SO4+Ba(NO3)2=BaSO4↓+2KNO3
(5)MH4Cl、NH4NO3:取少量溶液E 于试管中,滴加足量的稀硝酸和AgNO3溶液,若有白色沉淀生成,则溶液B中一定有NH4Cl,若无明显次泉,则溶液B中一定有NH4NO3
20.(1)①Na2CO3 ②饱和氨盐水呈碱性,更易吸收二氧化碳
(2)①$\rm Cl^{-}$、$\rm SO_4^{2-}$ ②14.2 ③不饱正溶液质量:25.9g+200g+208g-23.3g=410.6g
英语

提示词:对图像的文字进行识别
好的,图片中的文字为:
VI.阅读下面短文,在空白处填入1个适当的单词或括号内单词的正确形式。(共 10小题;每小题1.5分,满分15分)
Last Sunday, I had a perfect day! My aunt came to my home66 her six-year-old
daughter Alice in the morning. While my aunt was talking with my mom at home, my cousin felt a
bit67(boring). So I took Alice to the park near my home. There we bought two kites and
started flying68(they). While we were doing that, Alice jumped up and down and I knew
she was truly having great fun. Later, we69(sit) down on a bench and looked at the gardens.
As we were sitting there, Alice looked up at me and said, "What70great day today!" I
smiled at her and agreed. We did something quite common, yet we were very happy.
Many people wait for their "best days". But I think today is our perfect day. As adults, we often
make plans71(careful) in order to have a great day. Some people think that making a lot of
money72(make) them have a nice day. I think we should be more like 73(child).
They don't think about money 74 what will happen tomorrow. They really live in the moment
and enjoy the moment!
We often hear the expression that we should live in the present. Yesterday is a history.
Tomorrow is a mystery. Today is a gift. That's why it75(call) present. So seize the day!
图像描述
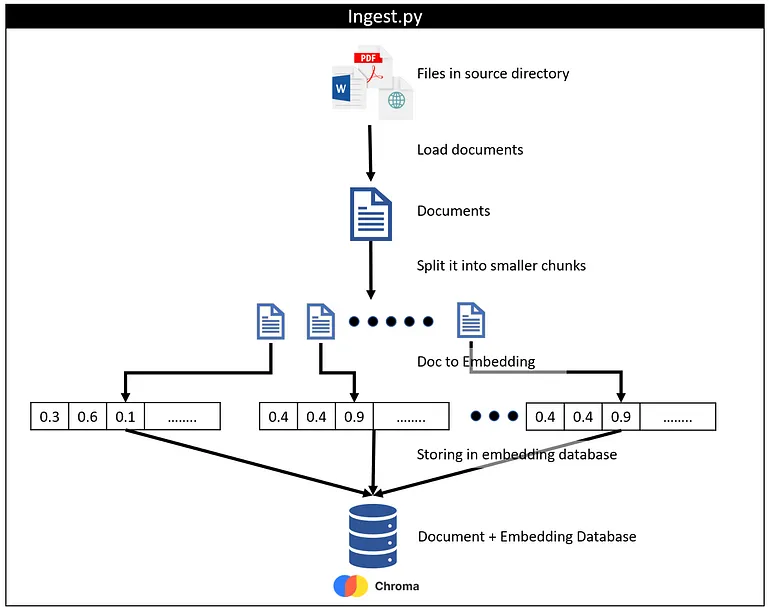
提示词:图像中描述的是什么?
这张图片展示了一个Python脚本(Ingest.py)的工作流程,它将source目录中的文件加载并处理,将其分割成小块,并为每个小块生成嵌入向量(embedding),最后将文件及其嵌入向量存储在数据库中。
工作流程的详细步骤如下:
- 读取source目录中的文件。
- 将每份文件分割成更小的chunk。
- 对每个chunk应用doc to embedding转换,生成嵌入向量。
- 将生成的嵌入向量与原始文档信息一起存储在Document + Embedding数据库中。
- 整个流程使用Chroma库进行操作。
这个流程图清晰地展示了如何将原始文档数据转换为结构化的嵌入式数据,以便于后续的分析和处理。