【生成式AI时代下的机器学习(2025)】第九讲:谈谈有关大型语言模型评估的几件事
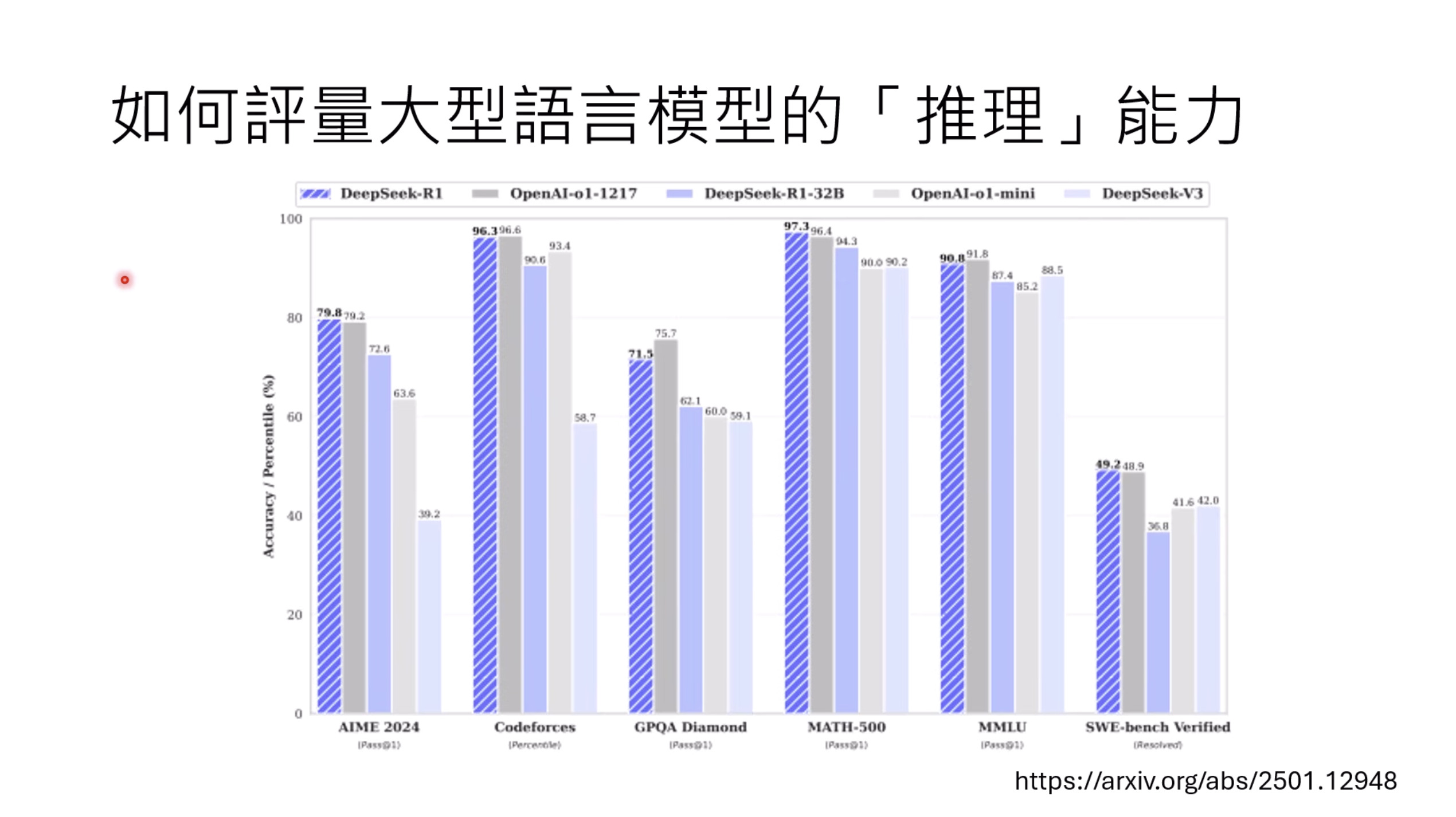
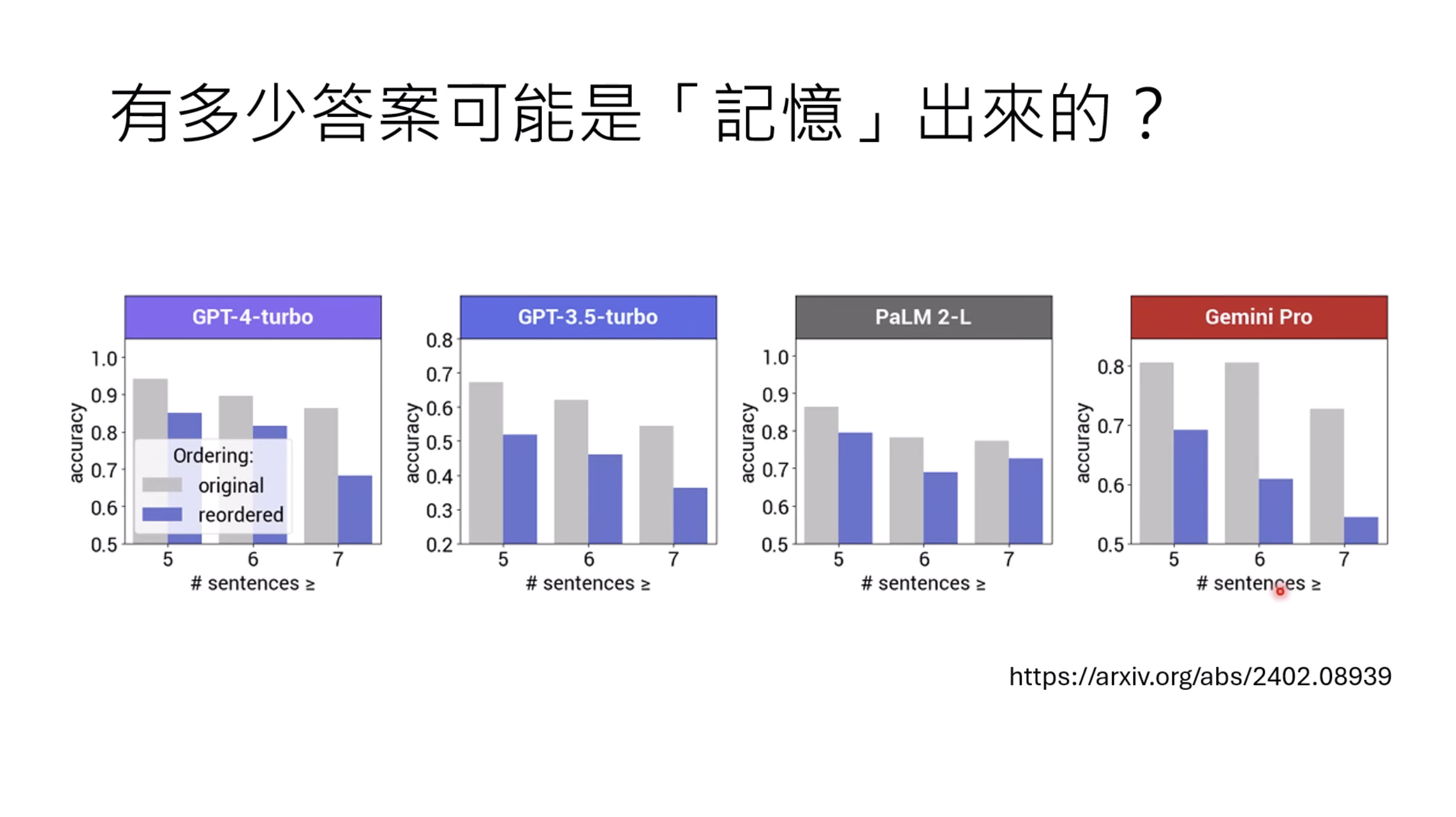
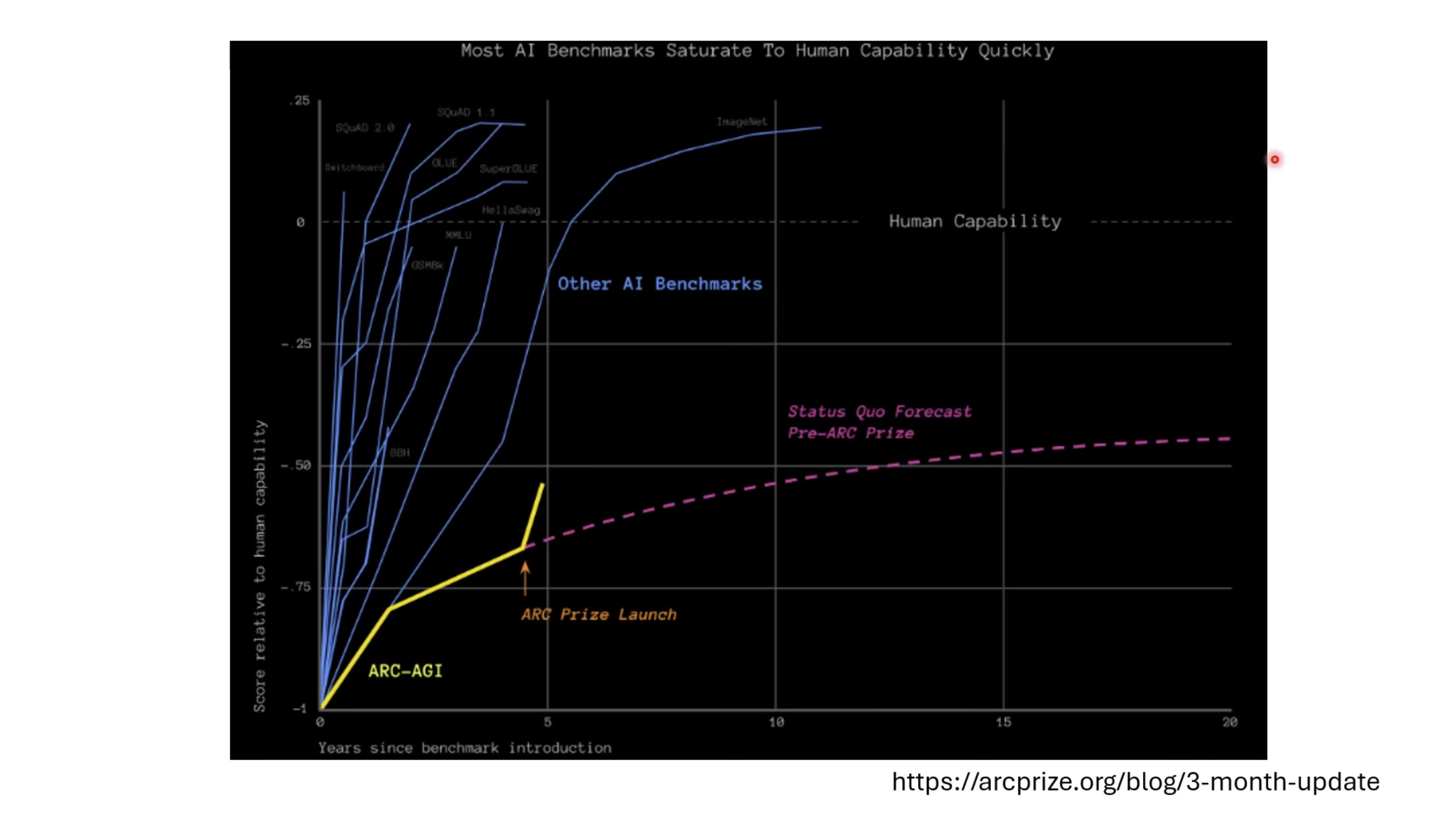
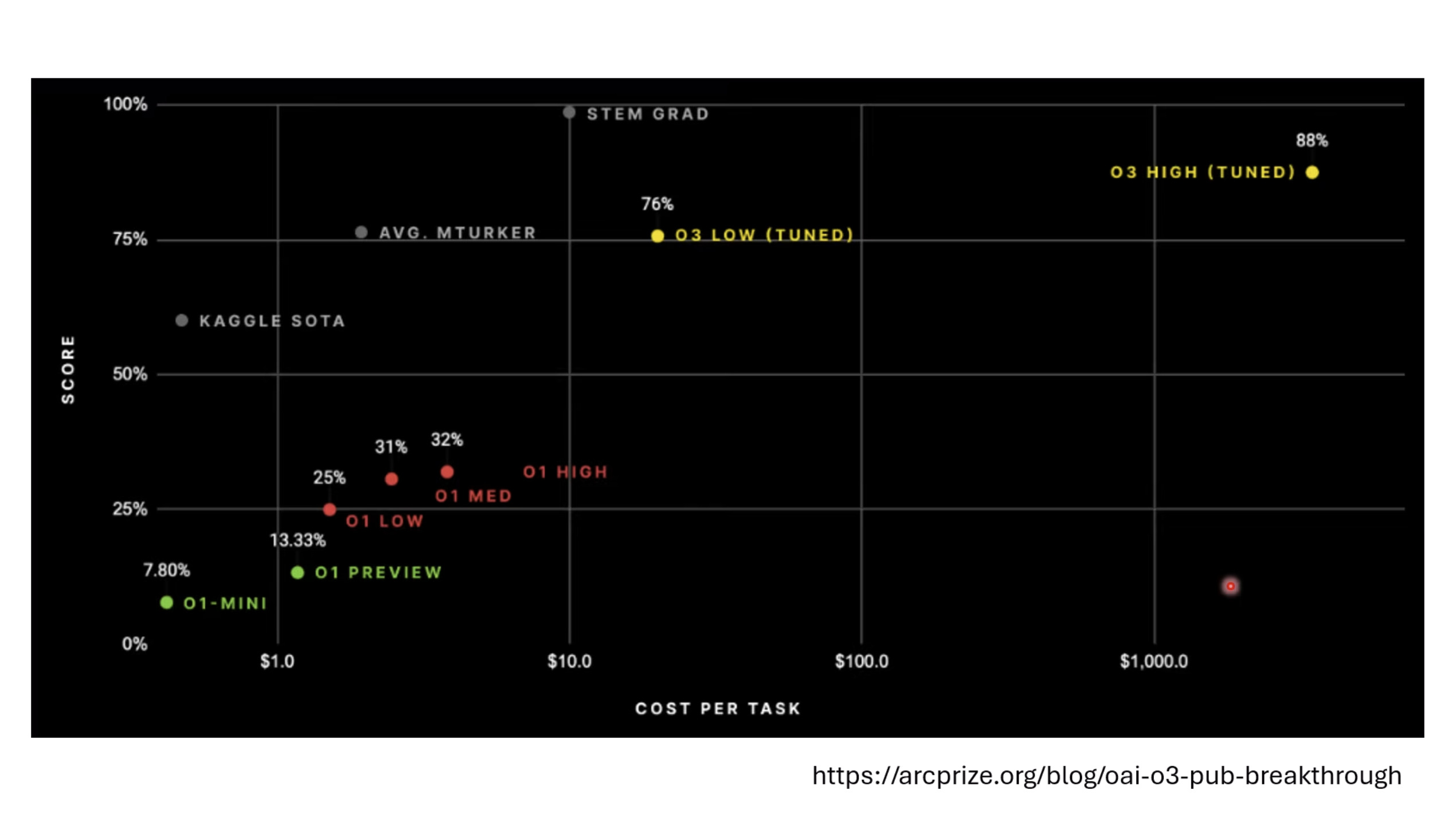
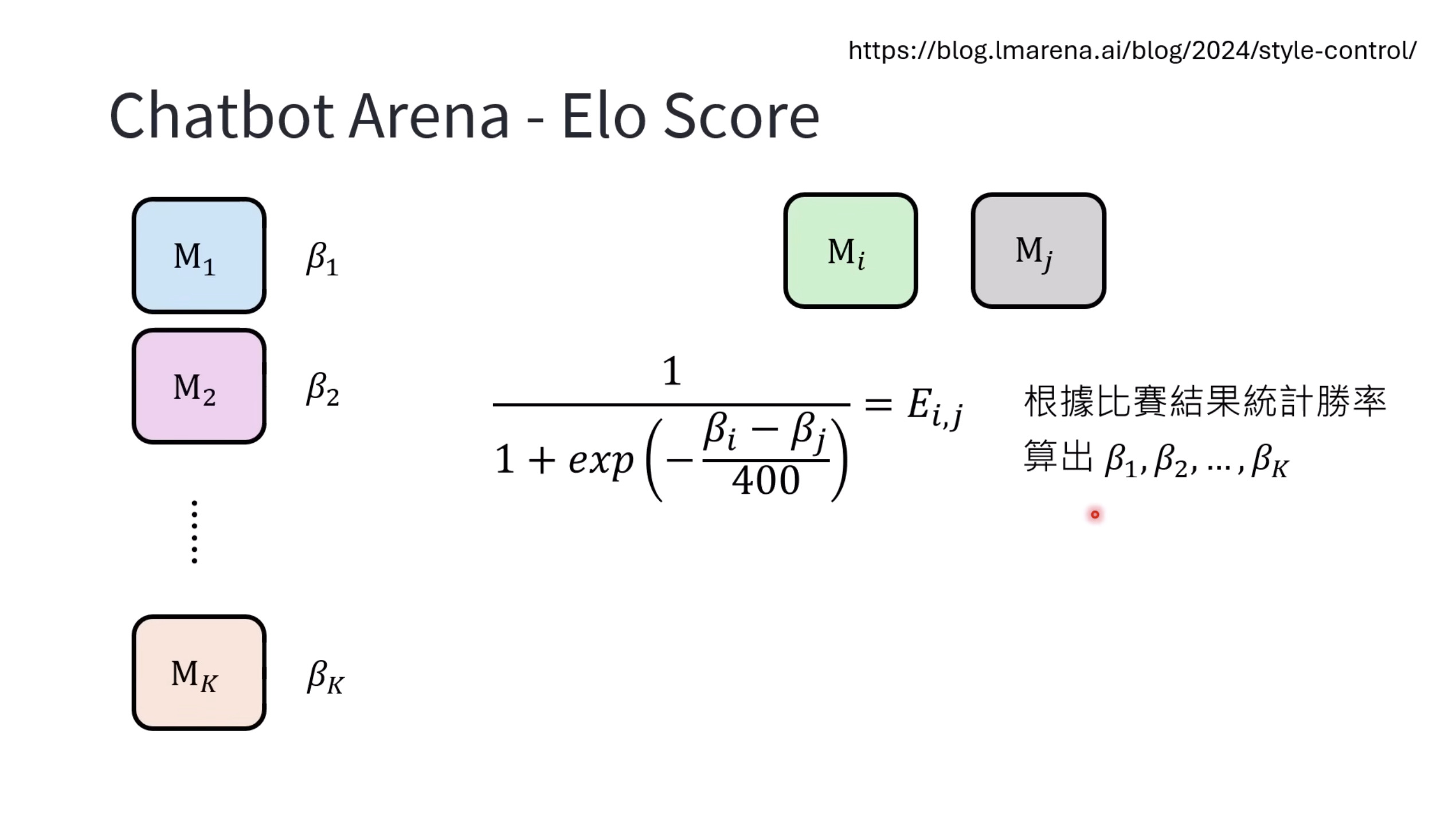
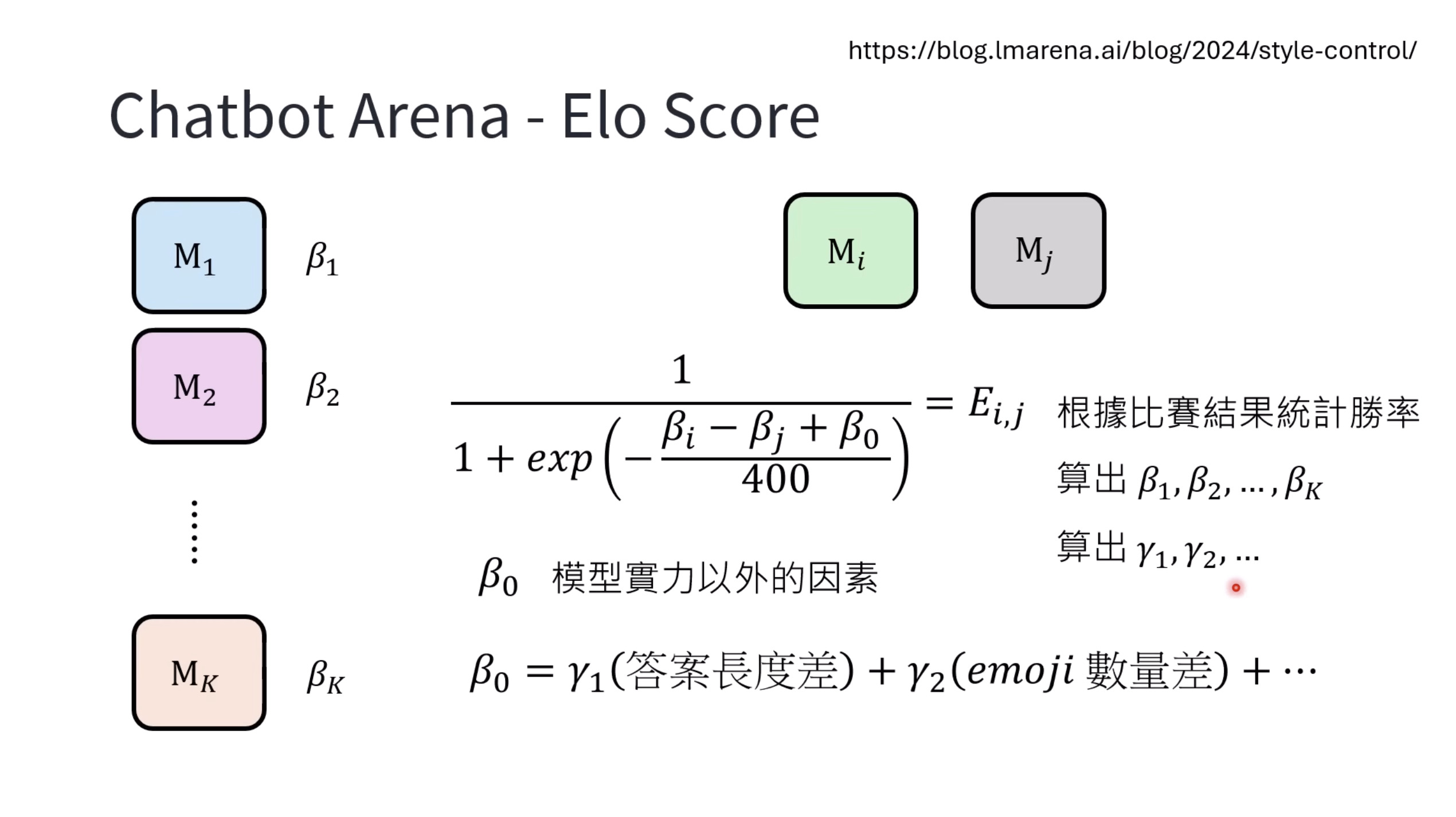
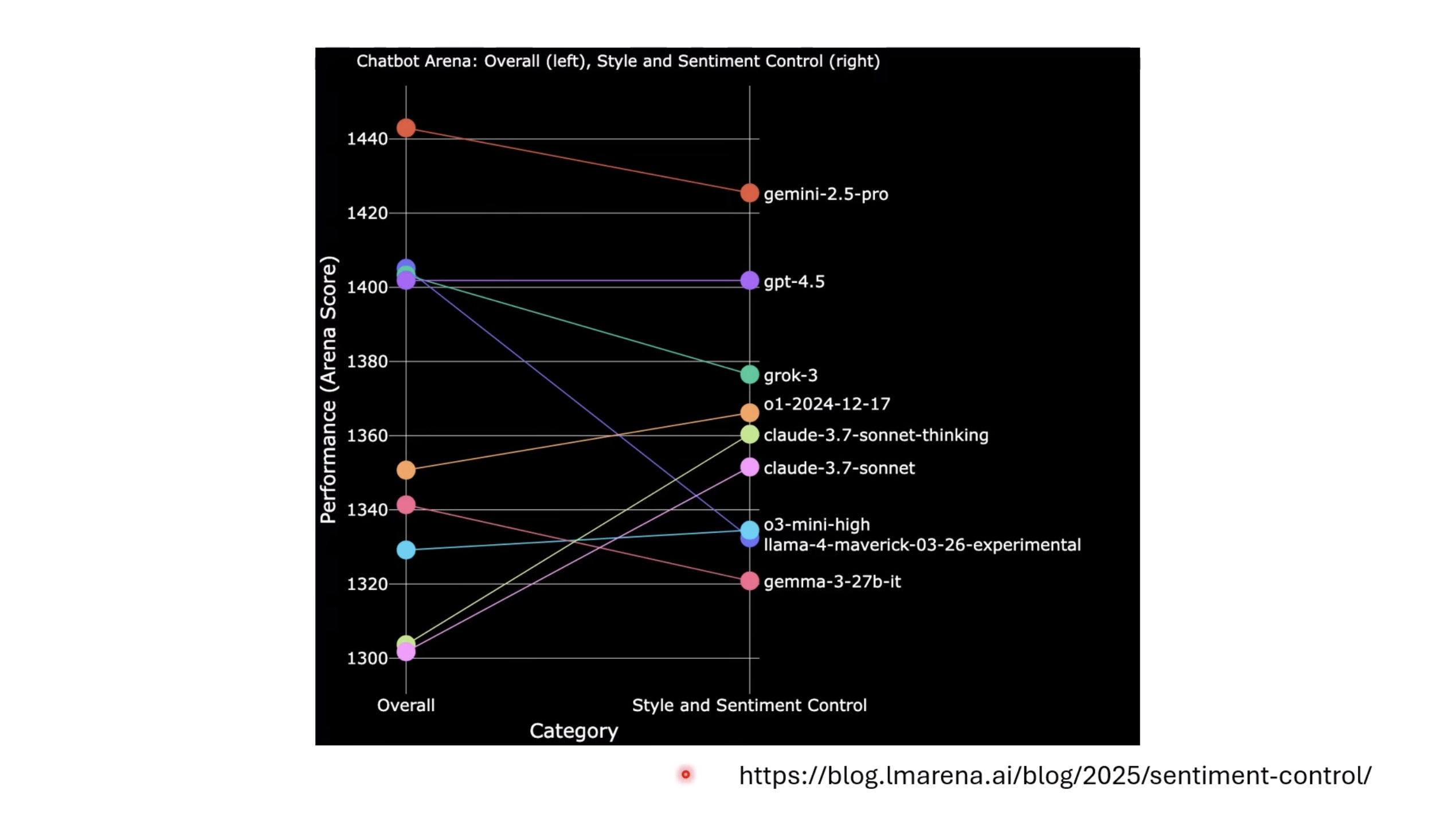
本文档讨论了大型语言模型的评估,重点关注其推理能力和记忆效应。文档展示了不同的基准测试结果,例如DeepSeek和OpenAI模型在推理任务上的表现,以及模型回答可能来自“记忆”而非推理的准确性下降情况。此外,还介绍了人工通用智能(ARC-AGI)的抽象推理语料库作为一种评估框架,并探讨了聊天机器人竞技场(Chatbot Arena)及其Elo评分系统,用于衡量和比较不同模型在实际用户互动中的表现,包括情感和风格控制。