华为 Atlas 800I A2 大模型部署实战(十):GlusterFS 构建高性能共享存储
本文档首先比较了 NFS、GlusterFS、Ceph 和 HDFS 四种分布式文件系统的优缺点及适用场景,强调了 GlusterFS 在无元数据服务器、高可用性和横向扩展方面的优势。Gluster 是一个可扩展的分布式文件系统,它将来自多个服务器的磁盘存储资源聚合成一个单一的全局命名空间。文档提供了在多台服务器上准备环境、安装 GlusterFS、配置信任池、创建和启动分布式复制卷的详尽步骤,并指导如何在客户端挂载和测试 GlusterFS 卷。最后,文档通过网络带宽和磁盘读写性能测试,对 GlusterFS 的实际表现进行了评估,指出当前网络带宽可能是性能瓶颈,建议使用更高速的网络接口(25 GbE)以提升性能。
服务器配置
AI 服务器:华为 Atlas 800I A2 推理服务器 X 5
| 组件 | 规格 |
|---|---|
| CPU | 鲲鹏 920(5250) |
| NPU | 昇腾 910B4(8X32G) |
| 内存 | 1024GB |
| 硬盘 | 系统盘:450GB SSDX2 RAID1 数据盘:3.5TB NVME SSDX4 |
| 操作系统 | openEuler 22.03 LTS |
分布式文件系统对比分析:
NFS (Network File System)
NFS 是一种传统的客户端-服务器架构文件共享协议,而不是一个真正的分布式文件系统。它允许客户端通过网络访问远程服务器上的文件,就像访问本地文件一样。
- 优点:
- 简单易用:部署和配置都非常简单,是许多Linux和Unix环境下的标准组件。
- 成熟稳定:作为一种历史悠久的协议,NFS非常成熟和可靠。
- 广泛兼容:支持标准的POSIX接口,几乎所有操作系统都能使用。
- 缺点:
- 单点故障:传统NFS依赖单个服务器,一旦服务器宕机,所有客户端都无法访问数据。
- 扩展性差:扩展能力有限,难以应对大规模集群的存储需求。
- 性能瓶颈:服务器会成为性能瓶颈,尤其是在高并发读写场景下。
GlusterFS
GlusterFS 是一个可扩展的分布式文件系统,它通过将多个存储节点(称为“brick”)聚合起来,形成一个统一的全局命名空间。GlusterFS没有元数据服务器,这使得它没有单点故障。
- 优点:
- 高可用性:无元数据服务器设计,避免了单点故障,可以容忍节点失效。
- 横向扩展:可以轻松地通过添加新节点来扩展存储容量和性能。
- 灵活性:支持多种卷类型,如条带化(Striped)、副本(Replicated)等,可以根据应用需求选择。
- 缺点:
- 小文件性能:对于海量小文件的读写性能相对较弱。
- 不适合数据库:由于文件锁机制的限制,通常不适合作为数据库的底层存储。
Ceph
Ceph 是一个功能强大的统一存储系统,它提供了对象存储(RADOS)、块存储(RBD)和文件系统(CephFS)三种接口。Ceph的核心是其CRUSH算法,能够智能地分布和管理数据。
- 优点:
- 三合一:一个系统同时提供对象、块和文件存储,满足不同应用场景的需求。
- 自动管理:具备自我修复和自我管理的特性,能够自动处理节点故障和数据平衡。
- 极高的可扩展性:设计之初就考虑了大规模集群,可以轻松扩展到PB甚至EB级别。
- 性能优异:特别是其RBD(块存储),在虚拟化和数据库场景下表现出色。
- 缺点:
- 架构复杂:相比NFS或GlusterFS,Ceph的部署和运维更为复杂,需要专业的知识。
- 硬件要求高:为了获得最佳性能,通常需要专用的硬件配置,如SSD作为OSD。
- CephFS的成熟度:相较于其对象和块存储功能,CephFS虽然在持续改进,但在某些场景下可能不如专用的文件系统。
HDFS (Hadoop Distributed File System)
HDFS 是为大数据处理而生的分布式文件系统,它是Apache Hadoop生态系统的核心组件。它的设计目标是支持大规模数据集的批处理,而不是通用的文件系统。
- 优点:
- 高吞吐量:专为大规模文件的顺序读写设计,能够提供极高的数据吞吐量。
- 高容错性:通过数据块的多副本机制,能够自动从节点故障中恢复,数据可靠性高。
- 数据本地性:通过将计算任务移动到数据所在的节点,减少网络传输,提高效率。
- 缺点:
- 不适合低延迟访问:不适合需要低延迟、随机读写和实时访问的应用。
- 不适合小文件:存储大量小文件会给元数据服务器(NameNode)带来巨大压力,导致性能瓶颈。
- 不支持随机修改:文件写入后只能追加,不能随机修改。
总结与对比
| 特性 | NFS | GlusterFS | Ceph | HDFS |
|---|---|---|---|---|
| 应用场景 | 小型文件共享、通用文件服务 | 高性能计算、媒体流、通用文件服务 | 统一存储、虚拟化、容器、数据库 | 大数据分析、批处理、机器学习 |
| 架构 | 客户端-服务器 | 无元数据服务器 | 统一存储,有元数据服务 | 主-从架构(NameNode-DataNode) |
| 可扩展性 | 差 | 强 | 极强 | 极强 |
| 可用性 | 差(单点故障) | 强(无元数据服务器) | 极强(自我修复) | 强(NameNode单点故障是风险) |
| 性能 | 通用,依赖服务器 | 大文件表现优异 | 综合性能强,块存储尤其突出 | 高吞吐量,不适合随机读写 |
| 易用性 | 简单 | 较简单 | 复杂 | 较简单 |
| 文件锁 | 支持 | 支持 | 支持 | 不支持 |
在您的AI服务器集群中,考虑到您需要构建一个高性能的共享存储来支持深度学习训练,Ceph 和 GlusterFS 是非常值得考虑的选择。如果您对部署和运维有较高要求,并希望获得更强大的功能和统一存储,Ceph是理想的选择;如果您更看重部署的简便性,且主要处理大文件读写,GlusterFS会是一个不错的方案。
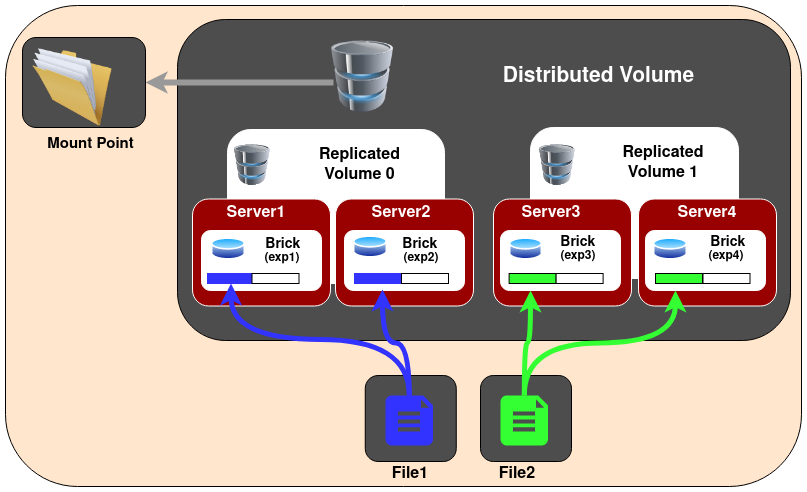
GlusterFS 架构
![]()
Gluster 卷是一组属于可信存储池(Trusted Storage Pool)的服务器集合。在每台服务器上都运行着一个管理守护进程(glusterd),它负责管理一个数据块进程(glusterfsd)。该数据块进程则会将底层磁盘存储(XFS 文件系统)导出。
客户端进程挂载此卷,并将所有数据块的存储空间作为一个单一的统一存储命名空间呈现给访问它的应用程序。客户端和数据块进程的栈中加载了各种转换器(translators)。应用程序的 I/O 操作会通过这些转换器被路由到不同的数据块。
准备服务器环境
在每台服务器上执行以下操作:
更新系统
- openEuler
yum update -y --nobest - CentOS/RHEL
yum update -y - Ubuntu/Debian
apt update && sudo apt upgrade -y
禁用 SELinux
为了简化部署,您可以暂时禁用SELinux。生产环境中,建议配置SELinux策略。
- 临时禁用 SELinux(立即生效,重启后失效)
sudo setenforce 0 - 永久禁用 SELinux(需重启生效)
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
防火墙配置
- openEuler/CentOS/RHEL
```bash
停止防火墙服务(立即生效)
systemctl stop firewalld
禁用防火墙开机自启
systemctl disable firewalld
- Ubuntu/Debian
```bash
# 关闭 ufw 防火墙
ufw disable
安装 GlusterFS
搜索 YUM 软件仓库中所有与 glusterfs 相关的软件包
yum search glusterfs
Last metadata expiration check: 0:06:40 ago on Mon 04 Aug 2025 04:56:59 PM CST.
======================================================== Name Exactly Matched: glusterfs =========================================================
glusterfs.aarch64 : Distributed File System
glusterfs.src : Distributed File System
======================================================= Name & Summary Matched: glusterfs ========================================================
glusterfs-cli.aarch64 : GlusterFS CLI
glusterfs-client-xlators.aarch64 : GlusterFS client-side translators
glusterfs-debuginfo.aarch64 : Debug information for package glusterfs
glusterfs-debugsource.aarch64 : Debug sources for package glusterfs
glusterfs-events.aarch64 : GlusterFS Events
glusterfs-geo-replication.aarch64 : GlusterFS Geo-replication
glusterfs-help.aarch64 : Including man files for glusterfs.
glusterfs-resource-agents.noarch : OCF Resource Agents for GlusterFS
glusterfs-thin-arbiter.aarch64 : GlusterFS thin-arbiter module
libglusterfs-devel.aarch64 : GlusterFS libglusterfs library
libglusterfs0.aarch64 : GlusterFS libglusterfs library
============================================================ Name Matched: glusterfs =============================================================
glusterfs-cloudsync-plugins.aarch64 : Cloudsync Plugins
glusterfs-extra-xlators.aarch64 : Extra Gluster filesystem Translators
glusterfs-fuse.aarch64 : Fuse client
glusterfs-server.aarch64 : Clustered file-system server
=========================================================== Summary Matched: glusterfs ===========================================================
libgfapi0.aarch64 : GlusterFS api library
libgfchangelog-devel.aarch64 : GlusterFS libchangelog library
libgfchangelog0.aarch64 : GlusterFS libchangelog library
libgfrpc-devel.aarch64 : GlusterFS libgfrpc library
libgfrpc0.aarch64 : GlusterFS libgfrpc0 library
libgfxdr-devel.aarch64 : GlusterFS libgfxdr library
libgfxdr0.aarch64 : GlusterFS libgfxdr0 library
libglusterd0.aarch64 : GlusterFS libglusterd library
python3-gluster.aarch64 : GlusterFS python library
安装 GlusterFS 服务端组件
- openEuler
yum install -y glusterfs-server glusterfs-fuse glusterfs-cli - CentOS/RHEL
# 添加仓库 yum install -y centos-release-gluster # 安装 GlusterFS yum install -y glusterfs-server glusterfs-client - Ubuntu/Debian
sudo apt install -y glusterfs-server glusterfs-client
启动 GlusterFS 服务并设置开机自启动
systemctl start glusterd
systemctl enable glusterd
创建 GlusterFS 存储目录
在每台存储服务器上创建 /data/gluster_brick 目录作为 GlusterFS 的 brick。我们这里使用了 172.16.33.107, 172.16.33.108, 172.16.33.109, 172.16.33.110 四台服务器做为存储。
mkdir -p /data/gluster_brick
配置 GlusterFS 信任池
在其中一台服务器上(例如,172.16.33.106),执行以下命令将所有4台服务器(172.16.33.107, 172.16.33.108, 172.16.33.109, 172.16.33.110)添加到 GlusterFS 信任池中。
gluster peer probe 172.16.33.107
gluster peer probe 172.16.33.108
gluster peer probe 172.16.33.109
gluster peer probe 172.16.33.110
验证所有节点是否已加入信任池:
gluster peer status
Number of Peers: 4
Hostname: 172.16.33.107
Uuid: cc7974f7-1f93-4b13-a105-1fcca4ff10c4
State: Peer in Cluster (Connected)
Hostname: 172.16.33.108
Uuid: 261c5014-66dc-4190-a796-d0f7bd7e8e84
State: Peer in Cluster (Connected)
Hostname: 172.16.33.109
Uuid: a5fafd1a-8efc-4403-b474-a04430a53244
State: Peer in Cluster (Connected)
Hostname: 172.16.33.110
Uuid: 00a19dda-ad2a-46c5-ad3a-8fcec14ce987
State: Peer in Cluster (Connected)
创建分布式复制卷
这里使用 2 个副本,数据会分布在 4 台服务器上。虽然有 5 台服务器,但是 brick 数量必须是 replica 数量的整数倍。
gluster volume create models_volume replica 2 \
172.16.33.107:/data/gluster_brick \
172.16.33.108:/data/gluster_brick \
172.16.33.109:/data/gluster_brick \
172.16.33.110:/data/gluster_brick \
force
models_volume: GlusterFS 卷的名称。replica 2: 数据副本数为 2。- 后面跟着的是每台服务器上的
brick 路径。
启动 GlusterFS 卷
gluster volume start models_volume
验证 GlusterFS 卷状态
查看卷的配置信息
gluster volume info models_volume
Volume Name: models_volume
Type: Distributed-Replicate
Volume ID: f16fee21-b19b-4176-858d-facf77ab1e87
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: 172.16.33.107:/data/gluster_brick
Brick2: 172.16.33.108:/data/gluster_brick
Brick3: 172.16.33.109:/data/gluster_brick
Brick4: 172.16.33.110:/data/gluster_brick
Options Reconfigured:
cluster.granular-entry-heal: on
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
查看卷的运行状态
gluster volume status models_volume
Status of volume: models_volume
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick 172.16.33.107:/data/gluster_brick 59069 0 Y 3443914
Brick 172.16.33.108:/data/gluster_brick 52520 0 Y 1211093
Brick 172.16.33.109:/data/gluster_brick 60671 0 Y 642639
Brick 172.16.33.110:/data/gluster_brick 56807 0 Y 3732388
Self-heal Daemon on localhost N/A N/A Y 2554341
Self-heal Daemon on 172.16.33.108 N/A N/A Y 1211135
Self-heal Daemon on 172.16.33.107 N/A N/A Y 3443956
Self-heal Daemon on 172.16.33.110 N/A N/A Y 3732430
Self-heal Daemon on 172.16.33.109 N/A N/A Y 642681
Task Status of Volume models_volume
------------------------------------------------------------------------------
There are no active volume tasks
确保所有bricks都显示为Online。
客户端挂载 GlusterFS 卷
现在,您可以在需要访问大模型权重文件的服务器上(这可以是您当前的5台AI服务器自身,或者其他需要访问的客户端)挂载这个 GlusterFS 卷。
安装 GlusterFS 客户端
在需要挂载卷的服务器上(如果是这5台AI服务器自身,则已经安装)。
- CentOS/RHEL
yum install -y glusterfs glusterfs-fuse - Ubuntu/Debian
apt install -y glusterfs-client
创建挂载点
mkdir -p /data/models
挂载 GlusterFS 卷
选择集群中的任意一台服务器的IP地址(这里使用 172.16.33.106)作为挂载点。
mount -t glusterfs 172.16.33.106:/models_volume /data/models
编辑 /etc/fstab,重启后 GlusterFS 卷能够自动挂载。
172.16.33.106:/models_volume /data/models glusterfs defaults,_netdev 0 0
_netdev选项确保在网络可用后才尝试挂载。
测试 GlusterFS
挂载完成后,您可以进行简单的测试:
创建文件
在 /data/models 目录下创建文件。
touch /data/models/test_model_weight.bin
echo "This is a test file for AI model weights." > /data/models/another_test.txt
验证文件复制
在其他任意一台 GlusterFS 服务器上,检查 models_volume 的 brick目录(例如 /data/gluster_brick)中是否能找到这些文件。由于是分布式复制卷,文件会分布在不同的 brick 上,并且每个文件都有两个副本。
性能分析
网络带宽性能测试
- 在一个节点上启动服务端
iperf3 -s```bash ———————————————————– Server listening on 5201 (test #1) ———————————————————– Accepted connection from 172.16.33.109, port 53886 [ 5] local 172.16.33.110 port 5201 connected to 172.16.33.109 port 53888 [ ID] Interval Transfer Bitrate [ 5] 0.00-1.00 sec 112 MBytes 940 Mbits/sec
[ 5] 1.00-2.00 sec 112 MBytes 942 Mbits/sec
[ 5] 2.00-3.00 sec 111 MBytes 934 Mbits/sec
[ 5] 3.00-4.00 sec 112 MBytes 941 Mbits/sec
[ 5] 4.00-5.00 sec 112 MBytes 941 Mbits/sec
[ 5] 5.00-6.00 sec 112 MBytes 940 Mbits/sec
[ 5] 6.00-7.00 sec 112 MBytes 941 Mbits/sec
[ 5] 7.00-8.00 sec 112 MBytes 942 Mbits/sec
[ 5] 8.00-9.00 sec 112 MBytes 941 Mbits/sec
[ 5] 9.00-10.00 sec 111 MBytes 932 Mbits/sec
[ 5] 10.00-10.00 sec 384 KBytes 1.19 Gbits/sec -
[ ID] Interval Transfer Bitrate [ 5] 0.00-10.00 sec 1.09 GBytes 939 Mbits/sec receiver ———————————————————– Server listening on 5201 (test #2) ———————————————————– ```
- 在另一个节点运行客户端
iperf3 -c 172.16.33.110 -t 10```bash Connecting to host 172.16.33.110, port 5201 [ 5] local 172.16.33.109 port 53888 connected to 172.16.33.110 port 5201 [ ID] Interval Transfer Bitrate Retr Cwnd [ 5] 0.00-1.00 sec 114 MBytes 955 Mbits/sec 0 396 KBytes
[ 5] 1.00-2.00 sec 112 MBytes 942 Mbits/sec 0 396 KBytes
[ 5] 2.00-3.00 sec 112 MBytes 935 Mbits/sec 0 479 KBytes
[ 5] 3.00-4.00 sec 112 MBytes 942 Mbits/sec 0 479 KBytes
[ 5] 4.00-5.00 sec 112 MBytes 942 Mbits/sec 0 479 KBytes
[ 5] 5.00-6.00 sec 112 MBytes 941 Mbits/sec 0 479 KBytes
[ 5] 6.00-7.00 sec 112 MBytes 943 Mbits/sec 0 479 KBytes
[ 5] 7.00-8.00 sec 112 MBytes 943 Mbits/sec 0 479 KBytes
[ 5] 8.00-9.00 sec 112 MBytes 942 Mbits/sec 0 479 KBytes
[ 5] 9.00-10.00 sec 111 MBytes 929 Mbits/sec 0 515 KBytes -
[ ID] Interval Transfer Bitrate Retr [ 5] 0.00-10.00 sec 1.10 GBytes 941 Mbits/sec 0 sender [ 5] 0.00-10.00 sec 1.09 GBytes 939 Mbits/sec receiver
iperf Done.
### 磁盘读写性能测试
- 写文件
```bash
dd if=/dev/zero of=/data/gluster_brick/test bs=1M count=1024 oflag=direct conv=fdatasync
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.552574 s, 1.9 GB/s
- 读文件
dd if=/data/gluster_brick/test of=/dev/null bs=1M iflag=direct1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.534011 s, 2.0 GB/s
GlusterFS 读写性能测试
- 写文件
dd if=/dev/zero of=/data/models/test bs=1M count=1024 oflag=direct conv=fdatasync1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 18.3127 s, 58.6 MB/s - 读文件
dd if=/data/models/test of=/dev/null bs=1M iflag=direct1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 9.7396 s, 110 MB/s
总结
| 测试项 | 吞吐(写) | 吞吐(读) | 网络带宽 |
|---|---|---|---|
| 本地磁盘 | 1.9 GB/s | 2.0 GB/s | — |
| GlusterFS(2 副本) | 58.6 MB/s | 110 MB/s | 939 Mb/s ≈ 118 MB/s |
| 网络(iperf) | — | — | 118 MB/s |
- 网络带宽是千兆网卡(1 GbE)是瓶颈,25 GbE 是更好的选择。