华为 Atlas 800I A2 大模型部署实战(八):GPUStack 实现 GPU 集群化管理
本文章详细介绍了华为 Atlas 800I A2 推理服务器上部署大型AI模型的实践过程,重点围绕GPUStack这一开源GPU集群管理工具。文章首先阐述了GPUStack的核心特性,包括其广泛的兼容性、对多种模型和推理框架的支持、灵活的部署能力以及智能管理功能。随后,文档提供了在主服务器和从服务器上安装、配置和使用GPUStack的详尽步骤,并展示了如何通过NFS实现模型文件的统一存储,以优化多服务器集群中的模型调度效率。文中还包含了GPUStack用户界面的截图,帮助读者直观理解其各项功能。
服务器配置
AI 服务器:华为 Atlas 800I A2 推理服务器 X 5
| 组件 | 规格 |
|---|---|
| CPU | 鲲鹏 920(5250) |
| NPU | 昇腾 910B4(8X32G) |
| 内存 | 1024GB |
| 硬盘 | 系统盘:450GB SSDX2 RAID1 数据盘:3.5TB NVME SSDX4 |
| 操作系统 | openEuler 22.03 LTS |
GPUStack 介绍
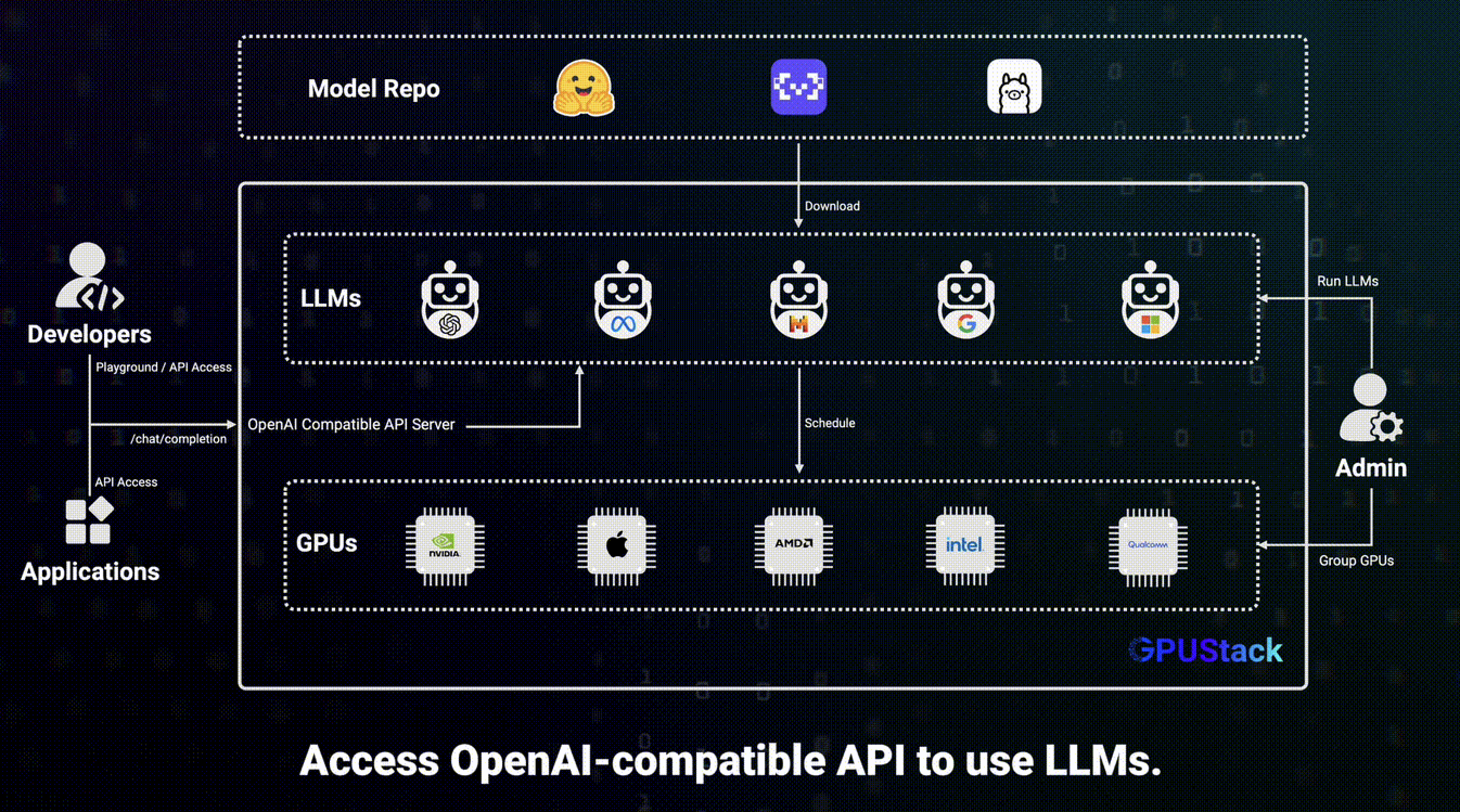
GPUStack 是一款开源的 GPU 集群管理器,专为运行 AI 模型设计,其核心特点如下:
- 广泛的兼容性:支持多厂商 GPU,覆盖苹果 Mac、Windows 电脑及 Linux 服务器,还能适配多种推理后端(如 vLLM、Ascend MindIE 等),并可同时运行多个版本的推理后端,满足不同模型的运行需求。
- 丰富的模型支持与灵活部署:支持 LLM、VLM、图像模型、音频模型等多种类型模型,可实现单节点和多节点多 GPU 推理,包括跨厂商和不同运行环境的异构 GPU,且能通过添加更多 GPU 或节点轻松扩展架构。
- 稳定与智能管理:具备自动故障恢复、多实例冗余和推理请求负载均衡功能,保障高可用性;能自动评估模型资源需求、兼容性等部署相关因素,还可基于可用资源动态分配模型。
- 实用的附加功能:采用轻量级 Python 包,依赖少、运维成本低;提供与 OpenAI 兼容的 API,便于无缝集成;支持用户及 API 密钥管理,可实时监控 GPU 性能、利用率以及令牌使用量和 API 请求速率。
操作系统支持
- Linux
- macOS
- Windows
加速框架支持
- NVIDIA CUDA (Compute Capability 6.0 以上)
- Apple Metal (M 系列芯片)
- AMD ROCm
- 昇腾 CANN
- 海光 DTK
- 摩尔线程 MUSA
- 天数智芯 Corex
- 寒武纪 MLU
推理框架支持
- vLLM
- Ascend MindIE
- llama-box(基于 llama.cpp 和 stable-diffusion.cpp)
- vox-box
模型来源
- Hugging Face
- ModelScope
- 本地文件路径
架构图
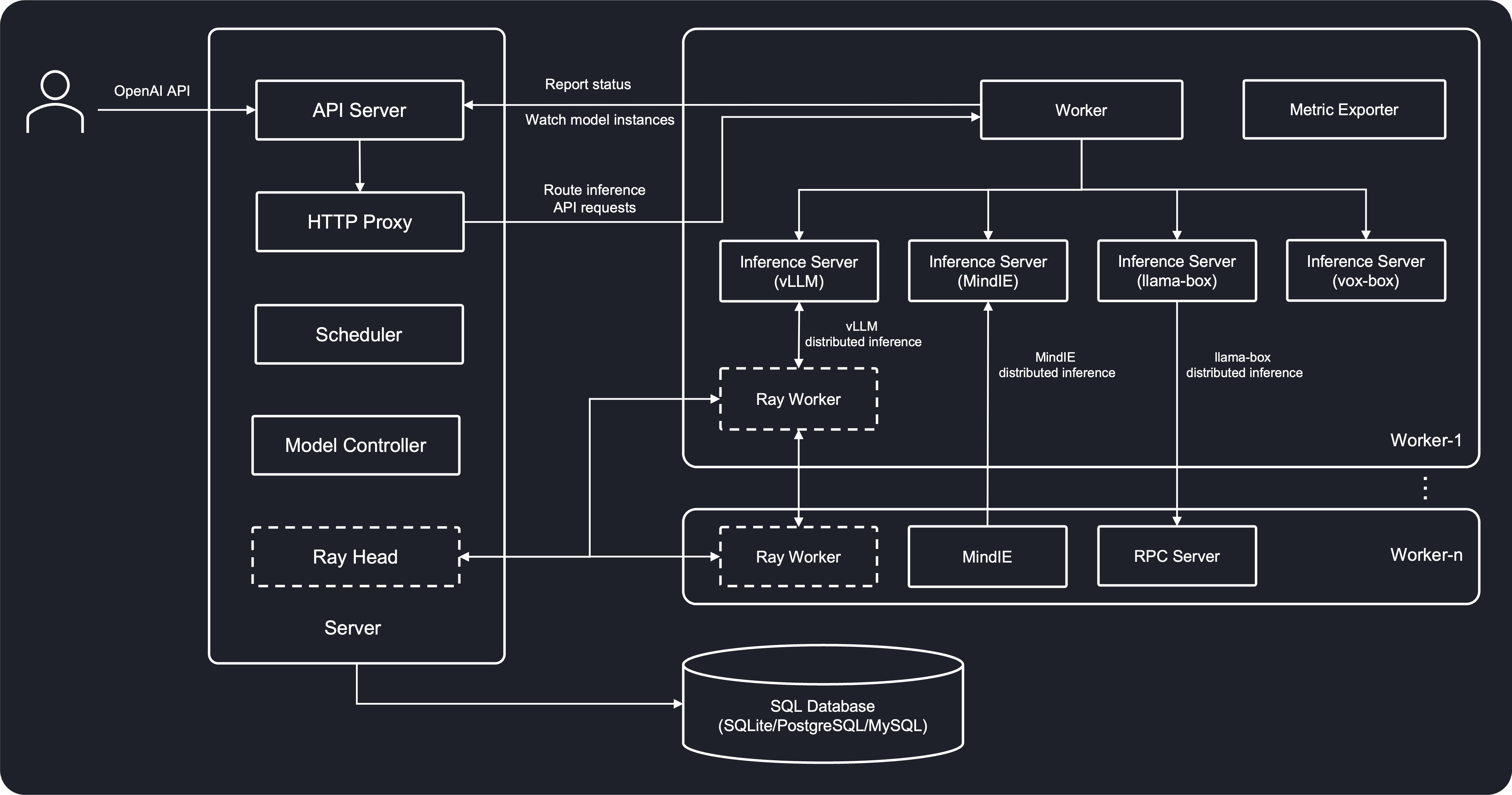
安装 GPUStack
启动 GPUStack
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /data/models:/models \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack:latest-npu \
--port 8080
gpustack-data是一个命名卷。不存在会自动创建。--port 8080: 默认服务器端口 80
容器正常运行后,执行以下命令获取默认密码:
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password
在浏览器中打开 http://172.16.33.106:8080,访问 GPUStack 界面。使用 admin 用户名和默认密码登录 GPUStack。
要获取用于添加 Worker 的令牌,请在 GPUStack 服务器节点上运行以下命令:
docker exec -it gpustack cat /var/lib/gpustack/token
e6342ab3eeafb1e44da8db7e9eb2c077
添加 Worker
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /data/models:/models \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack:latest-npu \
--server-url http://172.16.33.106:8080 \
--token e6342ab3eeafb1e44da8db7e9eb2c077
GPUStack 使用
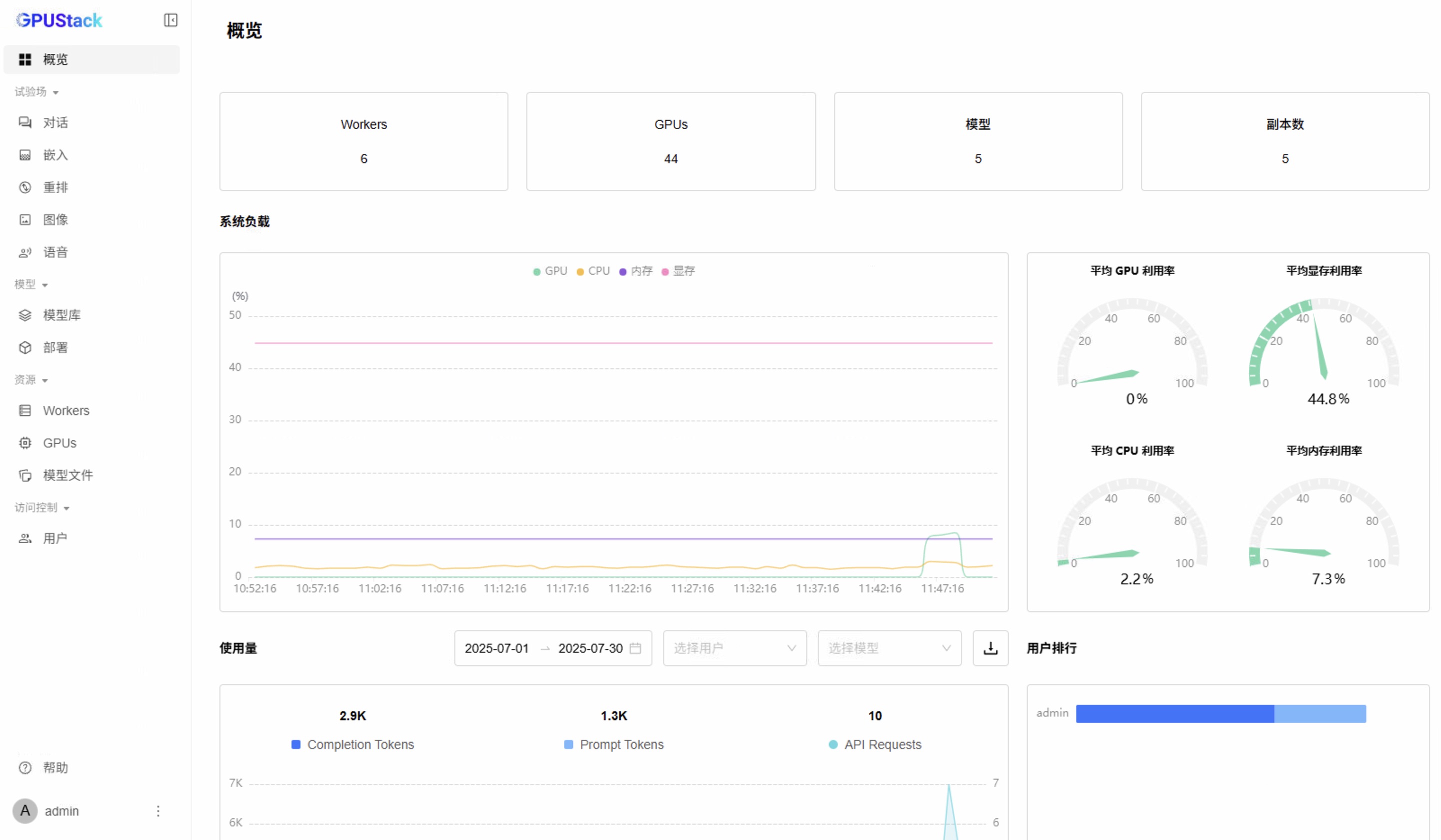
概览
模型库
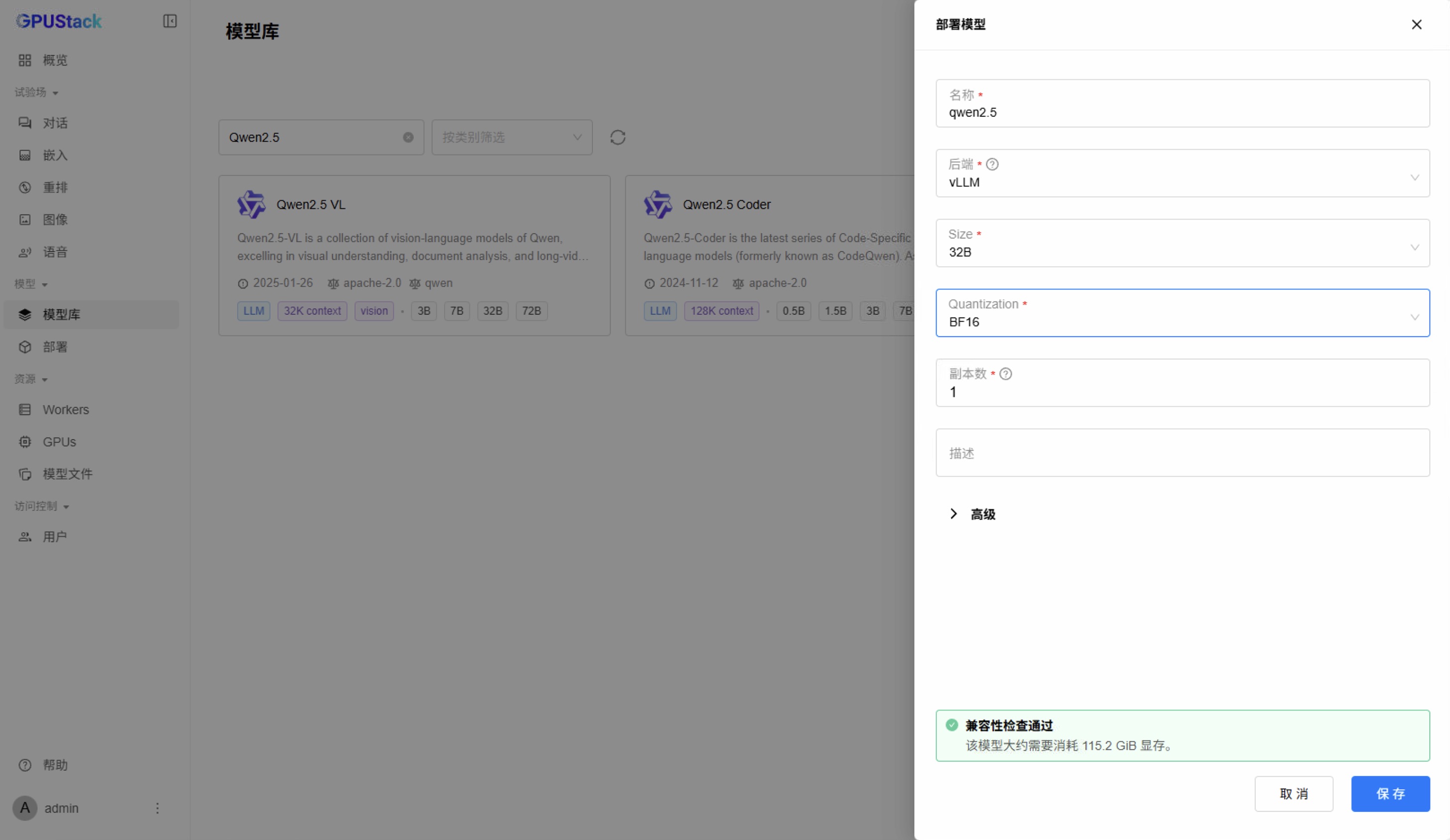
部署模型
Playground
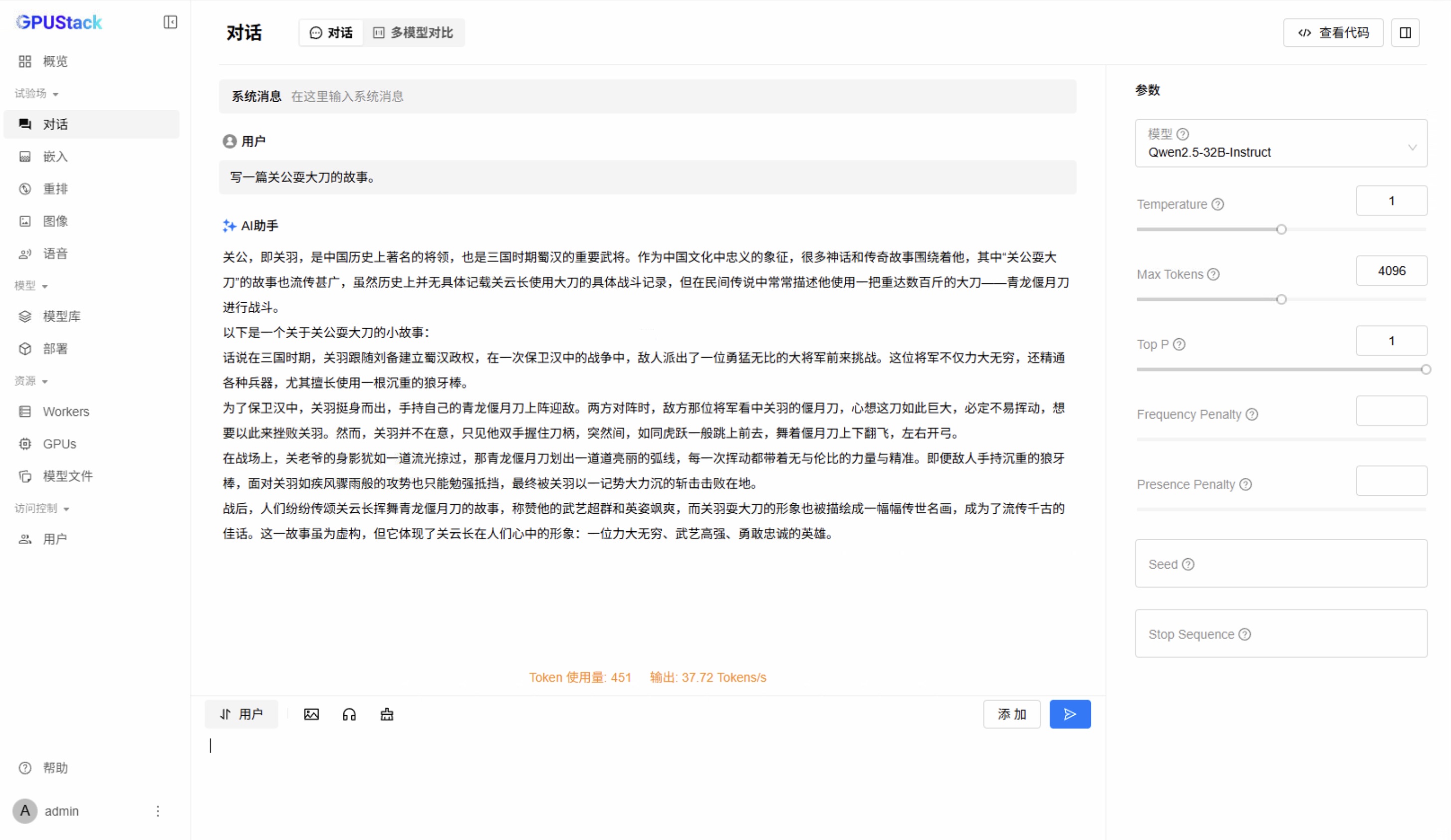
📌 vLLM 比 MindIE 的速度快 10%。vLLM 使用 4 卡和 8 卡的速度是一样的,没有出现像在 Nvidia GPU 上的线性加速现象。
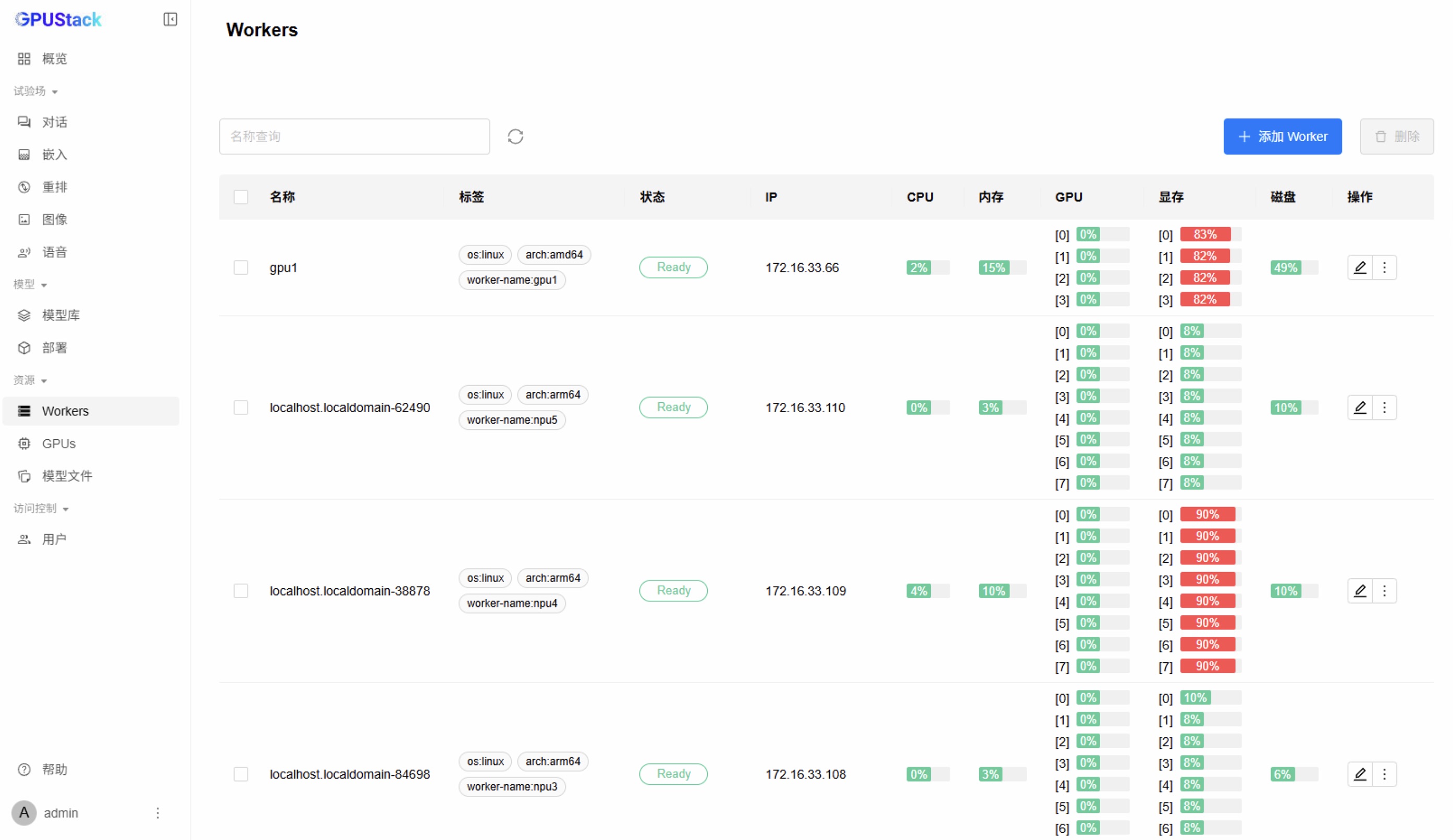
Workers
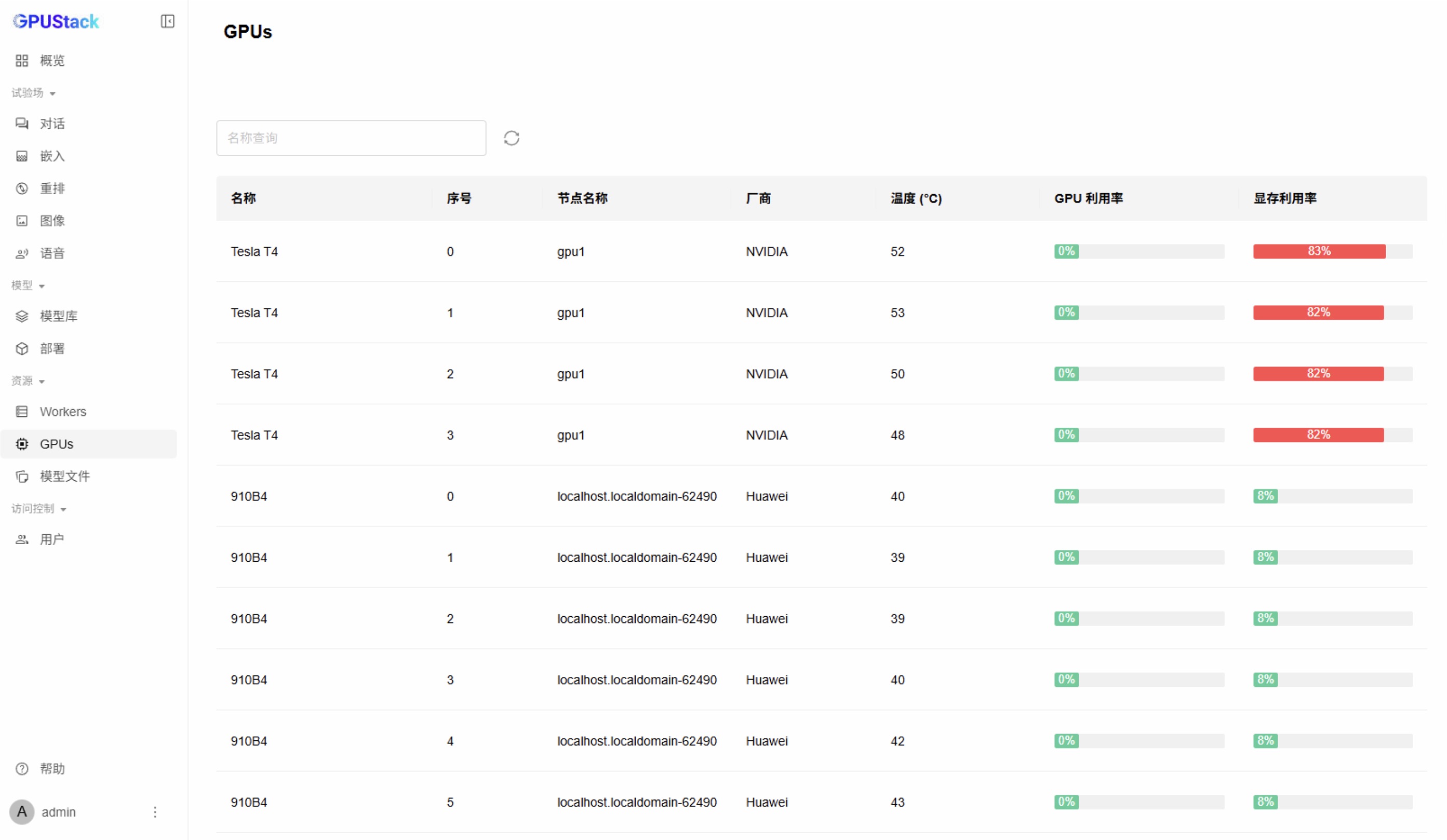
GPUs
模型文件
模型统一存储
GPUStack 部署模型时,调度到不同的服务器上,就需要重新下载模型(如果第一次在这台服务器上部署该模型)。
我们自己下载的模型,还要同步到每台服务器上,才能达到理想效果。
服务器集群信息
| 服务器 | 角色 | 我们下载的模型目录 | GPUStack 下载的模型目录 |
|---|---|---|---|
| 172.16.33.106 | 主 | /data/models | /data/models/gpustack-cache |
| 172.16.33.107 | 从 | /data/models(mount) | /data/models/gpustack-cache |
| 172.16.33.108 | 从 | /data/models(mount) | /data/models/gpustack-cache |
| 172.16.33.109 | 从 | /data/models(mount) | /data/models/gpustack-cache |
| 172.16.33.110 | 从 | /data/models(mount) | /data/models/gpustack-cache |
主服务器上运行
- 创建 GPUStack 模型缓存目录
mkdir -p /data/models/gpustack-cache
- 启用 NFS 服务
- 启动 NFS 服务
systemctl start nfs-server - 设置开机自启
systemctl enable nfs-server - 检查状态,确认是否已运行
systemctl status nfs-server
- 启动 NFS 服务
- 配置
/etc/exportscat >> /etc/exports <<'EOF' /data/models 172.16.33.0/24(rw,sync,no_root_squash,no_subtree_check) EOF - 导出 NFS 共享目录
exportfs -ra - 验证导出
exportfs -v
从服务器上运行
- 查看远程共享目录
showmount -e 172.16.33.106 - 创建本地挂载点
mkdir -p /data/models
- 挂载共享目录
mount -t nfs -o vers=3,hard,intr,timeo=600,retrans=3 172.16.33.106:/data/models /data/models
| 字段 | 解释 |
|---|---|
mount |
Linux 的挂载命令,用来把一个文件系统(本地或远程)挂接到目录树。 |
-t nfs |
指定文件系统类型为 NFS(Network File System)。 |
-o … |
后面跟挂载选项,多个选项用逗号分隔。 |
vers=3 |
强制使用 NFS 第 3 版。版本 3 兼容性好、状态简单,跨网段或防火墙场景下比 v4 更稳定。 |
hard |
硬挂载:当网络或服务端暂时不可达时,客户端 持续重试,永不向应用程序返回 I/O 错误。 |
intr |
可中断:在 hard 重试期间,允许用户用 Ctrl-C 等信号中断挂起的进程,防止永久阻塞。 |
timeo=600 |
超时时间为 60 秒(单位是 0.1 秒)。第一次 RPC 无响应后等待 60 秒再重传。 |
retrans=3 |
重传次数。最多重传 3 次仍未响应才向上层报错;结合 timeo 共可等待 180 秒。 |
172.16.33.106:/data/models |
远程共享路径(服务端 IP + 导出目录)。 |
/data/models |
本地挂载点,远程目录将出现在这个本地目录下。 |
- 重新自动挂载共享目录
cat >> /etc/fstab <<'EOF'
172.16.33.106:/data/models /data/models nfs vers=3,hard,intr,timeo=600,retrans=3,_netdev 0 0
EOF
- 验证挂载
mount -a
启动 GPUStack
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /data/models:/models \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack:latest-npu \
--port 8080 \
--cache-dir /models/gpustack-cache
- 获取默认密码:
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password
- 获取 Token:
docker exec -it gpustack cat /var/lib/gpustack/token
添加 Worker
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /data/models:/models \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack:latest-npu \
--server-url http://172.16.33.106:8080 \
--token <您的 Token> \
--cache-dir /models/gpustack-cache